

一個參數量為13B的模型竟然能擊敗頂級的GPT-4?就像下圖所示,為了確保結果的有效性,這項測試也遵循了OpenAI的數據去噪方法,並且沒有發現任何數據污染的證據
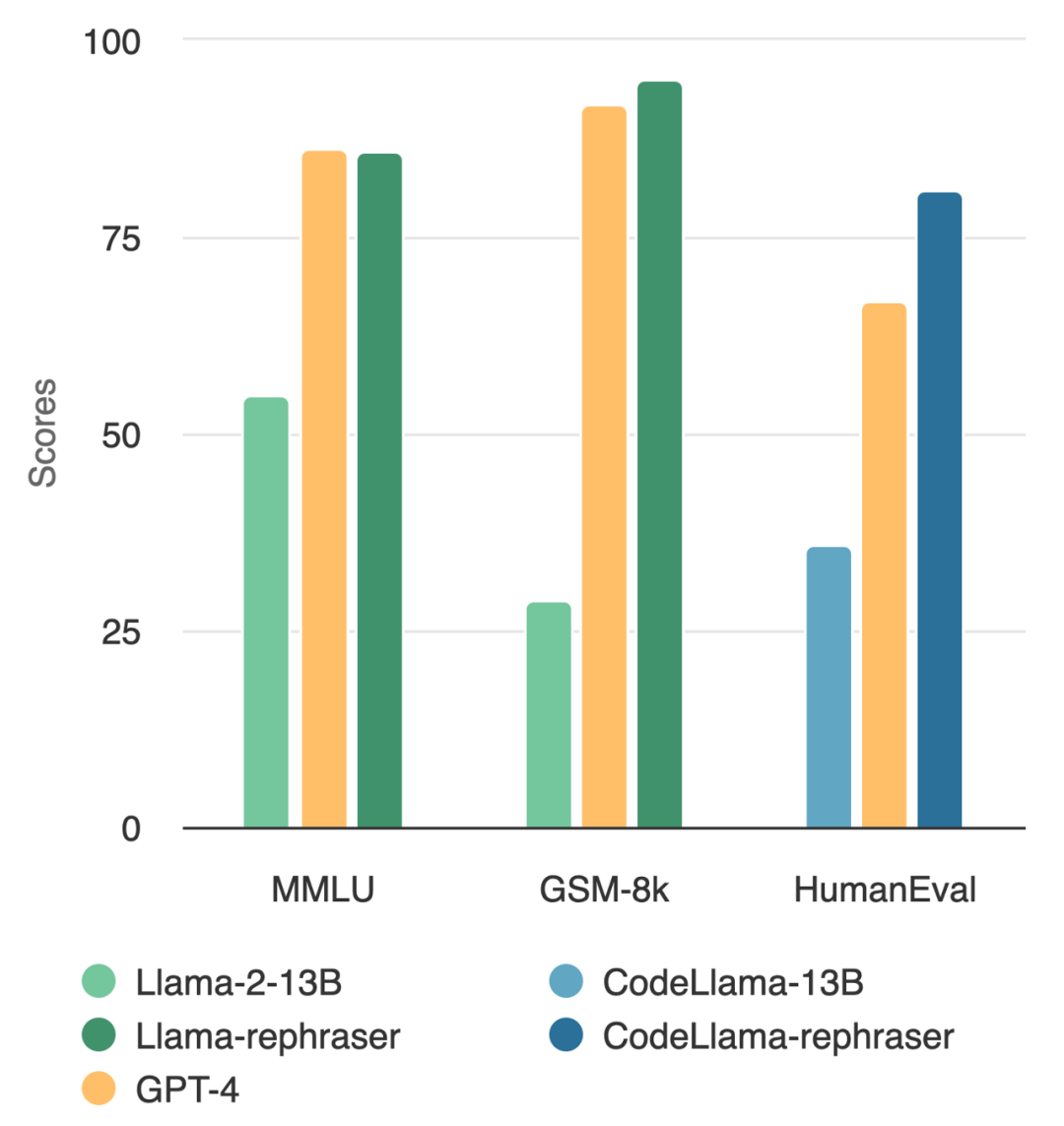
觀察圖中的模型,你會發現只要帶有「rephraser」這個詞,模型的表現都相對較高
##這背後到底有何貓膩?原來是資料污染了,即測試集資訊在訓練集中遭到洩漏,而且這種污染還不易被偵測到。儘管這個問題非常關鍵,但理解和檢測污染仍然是一個開放且具有挑戰性的難題。
現階段,去污最常用的方法是n-gram 重疊和嵌入相似性搜尋:N-gram 重疊依賴字串匹配來檢測污染,是GPT-4、 PaLM 和Llama-2 等模型常用方法;嵌入相似性搜尋使用預訓練模型(例如BERT)的嵌入來尋找相似且可能受到污染的範例。
然而,來自 UC 柏克萊、上海交通大學的研究表明測試數據的簡單變化(例如,改寫、翻譯)就可以輕鬆繞過現有的檢測方法。他們並將測試案例的此類變體稱為「需要改寫的內容是:改寫樣本(Rephrased Samples)」。
以下是MMLU基準測試中需要改寫的內容是:改寫樣本的示範結果。結果表明,如果訓練集中包含這種樣本,13B模型可以達到非常高的表現(MMLU 85.9)。可惜的是,現有的檢測方法(如n-gram重疊和嵌入相似性)無法偵測到這種污染。例如,嵌入相似性方法很難將改寫問題與同一主題中的其他問題區分開來

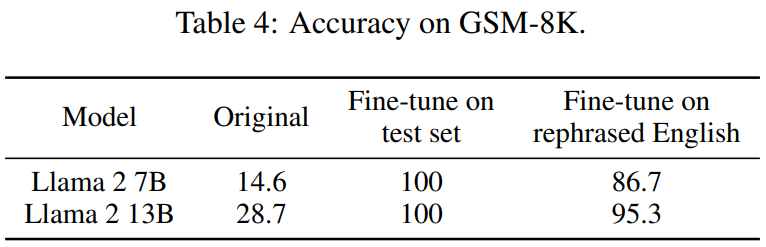
#透過類似的改寫技術,本文在在廣泛使用的編碼和數學基準測試中觀察到一致的結果,例如HumanEval 和GSM-8K(如文章開頭圖中所示)。因此,能夠檢測此類需要改寫的內容是:改寫樣本變得至關重要。
接下來,我們來看看這項研究是如何進行的。

隨著大模型(LLM)的快速發展,人們對測試集污染問題的關注越來越多。許多人對公共基準的可信度表示擔憂
為了解決這個問題,有些人使用傳統的去污方法,例如字串匹配(如n-gram重疊),來刪除基準資料。然而,這些操作遠遠不夠,因為只需對測試資料進行一些簡單的更改(例如改寫、翻譯),就可以輕鬆地繞過這些淨化措施
如果不消除測試數據的這種更改,13B 模型很容易過度擬合測試基準並實現與GPT-4 相當的性能,這是更重要的。研究人員在MMLU、GSK8k 和HumanEval 等基準測試中驗證了這些觀察結果
同時為了解決這些日益增長的風險,本文也提出了一種更強大的基於LLM的去污方法LLM decontaminator,並將其應用於流行的預訓練和微調資料集,結果表明,本文提出的LLM 方法在刪除需要改寫的內容是:改寫樣本方面明顯優於現有方法。
這個做法也揭露了一些先前未知的測試重疊(test overlap)。例如,在 RedPajamaData-1T 和 StarCoder-Data 等預訓練集中,本文發現 HumanEval 基準有 8-18% 重疊。此外,本文也在 GPT-3.5/4 產生的合成資料集中發現了這種污染,這也說明了在 AI 領域存在潛在的意外污染風險。
我們希望透過本文,呼籲社區在使用公共基準時採取更加強有力的淨化方法,並積極開發新的一次性測試案例來準確評估模型
需要改寫的內容是:改寫樣本
本文的目標是調查訓練集中包含測試集的簡單變更是否會影響最終的基準效能,並將測試案例的這種變化稱為「需要改寫的內容是:改寫樣本」。實驗中考慮了基準的各個領域,包括數學、知識和編碼。範例 1 是來自 GSM-8k 的需要改寫的內容是:改寫樣本,其中有 10-gram 重疊無法偵測到,修改後和原始文字保持相同的語意。

改寫技術針對不同形式的基準污染有微小差異。在基於文本的基準測試中,本文透過重新排列詞序或使用同義詞替換等手段,對測試案例進行改寫,以達到不改變語意的目的。而在基於程式碼的基準測試中,本文則透過改變編碼風格、命名方式等方式進行改寫
如下所示,演算法1 中針對給定的測試集提出了一種簡單的演算法。此方法可以幫助測試樣本逃避檢測。

接下來本文提出了一種新的污染檢測方法,可以準確地從相對於基準的資料集中刪除需要改寫的內容是:改寫樣本。
具體而言,本文引進了 LLM decontaminator。首先,對於每個測試案例,它使用嵌入相似度搜尋來識別具有最高相似度的 top-k 訓練項,之後透過 LLM(例如 GPT-4)評估每一對是否相同。這種方法有助於確定資料集中有多少需要改寫的內容是:改寫樣本。
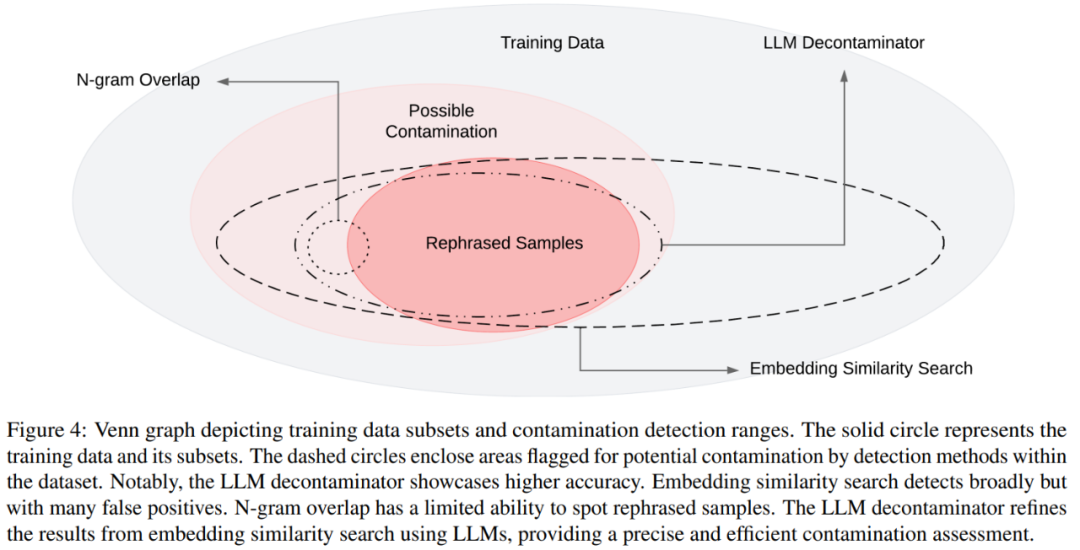
在圖4中展示了不同污染與不同偵測方法的維恩圖
在第5.1 節中,實驗證明了在需要改寫的內容是:改寫樣本上訓練的模型可以取得顯著的高分,在三在廣泛使用的基準(MMLU、HumanEval 和GSM-8k)中實現與GPT-4 相當的性能,這表明需要改寫的內容是:改寫樣本應被視為污染,應從訓練資料中刪除。在第 5.2 節中,本文根據 MMLU/HumanEval 中需要改寫的內容是:改寫樣本評估不同的污染檢測方法。在第 5.3 節中,本文將 LLM decontaminator 應用於廣泛使用的訓練集並發現先前未知的污染。
我們接下來來看一些主要的結果
#需要改寫的內容是:重寫污染標準樣本
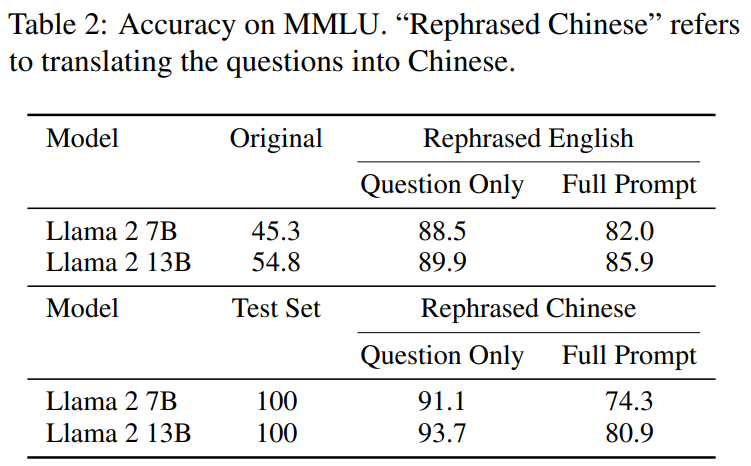
如表2 所示,在需要改寫的內容是:改寫樣本上訓練的Llama-2 7B 和13B 在MMLU 上取得顯著的高分,從45.3 到88.5。這表示經過改寫的樣本可能會嚴重扭曲基準數據,應視為污染。
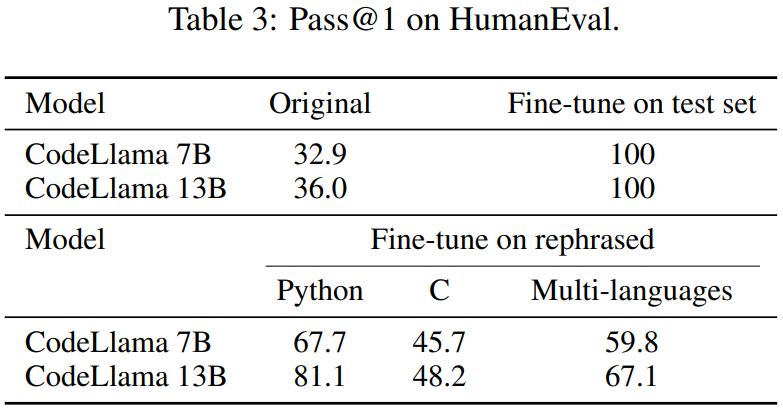
本文也對HumanEval 測試集進行了改寫,並將其翻譯成五種程式語言:C、JavaScript 、Rust、Go 和Java。結果顯示,在需要改寫的內容是:改寫樣本上訓練的 CodeLlama 7B 和 13B 在 HumanEval 上可以取得極高的分數,分別從 32.9 到 67.7 以及 36.0 到 81.1。相比之下,GPT-4 在 HumanEval 上只能達到 67.0。
下表 4 也取得了相同的效果:
對偵測污染方法的評估
如表5 所示,除LLM decontaminator 外,所有其他檢測方法都會引入一些誤報。改寫翻譯的樣本都不會被 n-gram 重疊偵測到。使用 multi-qa BERT,嵌入相似性搜尋被證明對翻譯樣本完全無效。

#資料集的污染狀況
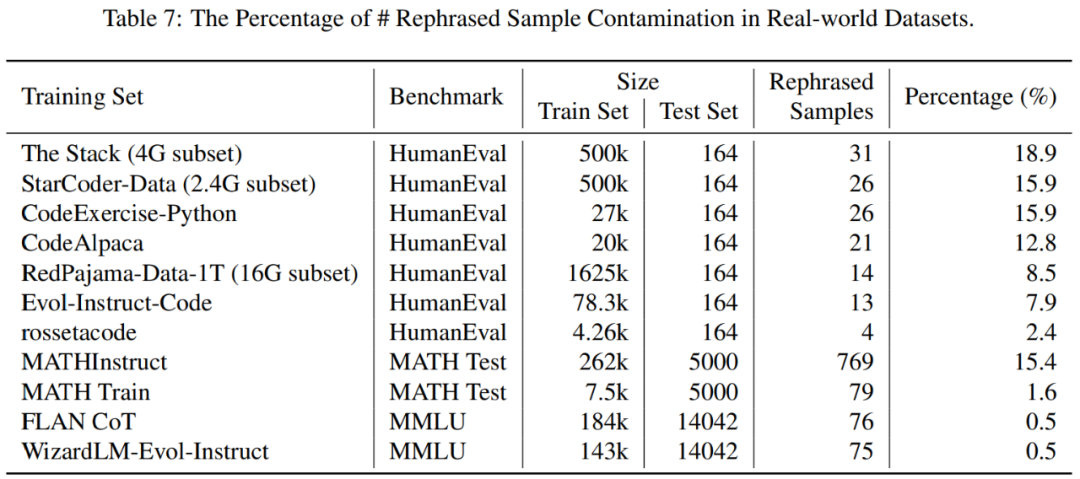
##在表7中,顯示了每個訓練資料集中不同基準的資料污染百分比

#LLM decontaminator 揭示了79 個自需要改寫的內容是:改寫樣本的實例,佔MATH 測試集的1.58%。範例 5 是 MATH 訓練資料中 MATH 測試的改寫範例。 #####################請查看原始論文以獲取更多資訊######
以上是13B模型在與GPT-4的全面對決中佔優勢?背後是否存在某些不尋常的情況?的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































