

一般情况下,大型语言模型的部署通常采用"预训练-微调"的方式。然而,当对多个任务(如个性化助手)进行基础模型的微调时,训练和服务的成本会变得非常高。低秩适配(LowRank Adaptation,LoRA)是一种高效的参数微调方法,通常用于将基础模型适配到多个任务上,从而生成大量派生的LoRA适配程序
重新写作: 批量推理在服务过程中提供了许多机会,这种模式被证明可以通过微调适配器权重来实现与完全微调相当的性能。虽然这种方法可以实现低延迟的单个适配器推理和跨适配器的串行执行,但在同时为多个适配器提供服务时,会显著降低整体服务吞吐量并增加总延迟。因此,如何解决这些微调变体的大规模服务问题仍然未知
近期有来自UC伯克利、斯坦福等高校的研究人员在一篇论文中提出了一种被称为S-LoRA的新微调方法

S-LoRA 是专为众多 LoRA 适配程序的可扩展服务而设计的系统,它将所有适配程序存储在主内存中,并将当前运行查询所使用的适配程序取到 GPU 内存中。
S-LoRA 提出了「统一分页」(Unified Paging)技术,即使用统一的内存池来管理不同等级的动态适配器权重和不同序列长度的 KV 缓存张量。此外,S-LoRA 还采用了新的张量并行策略和高度优化的定制 CUDA 内核,以实现 LoRA 计算的异构批处理。
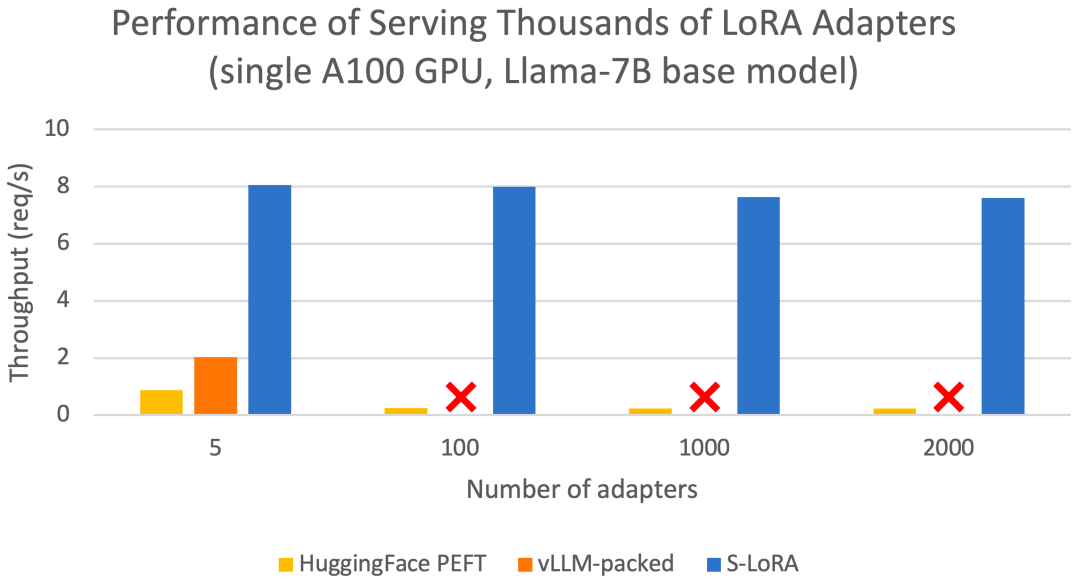
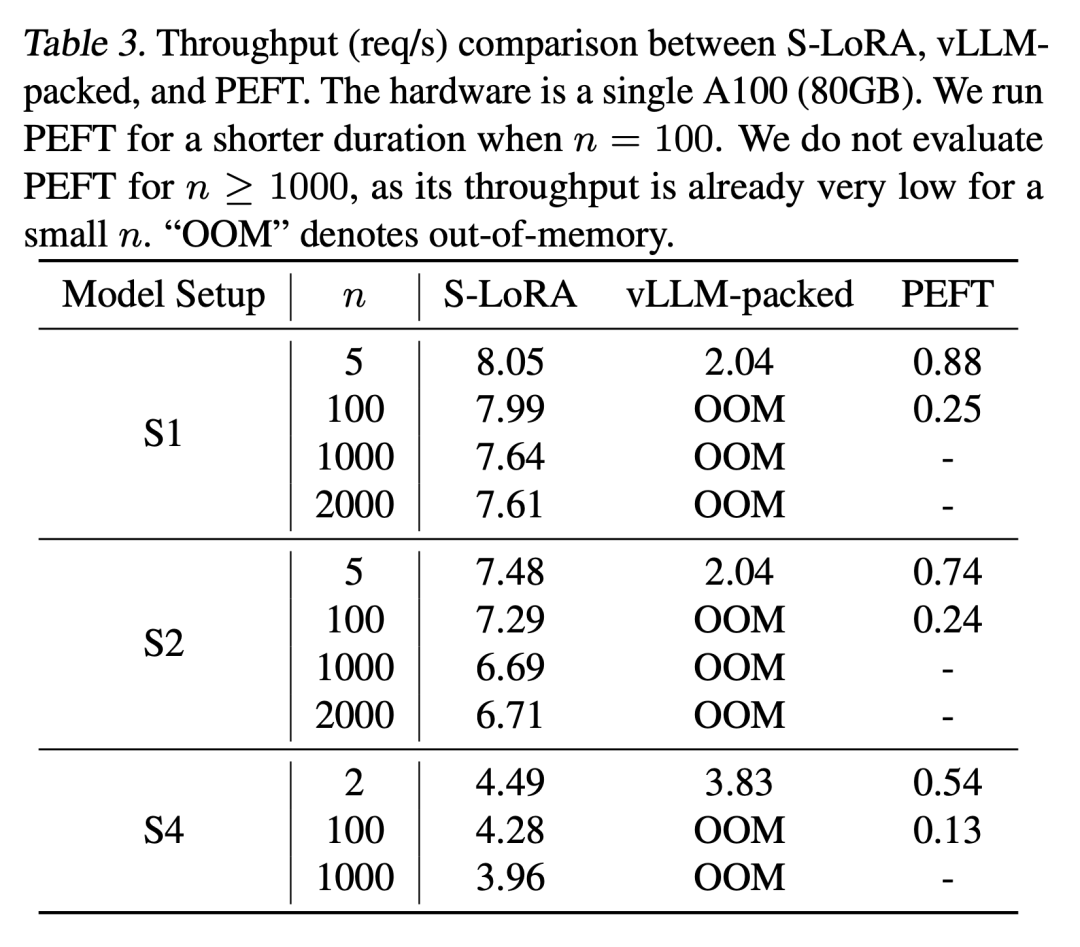
这些功能允许S-LoRA以较小的成本在单个或多个GPU上为数千个LoRA适配器提供服务(同时为2000个适配器提供服务),并将额外的LoRA计算成本降至最低。相比之下,vLLM-packed需要维护多个权重副本,并且由于GPU内存限制,只能为少于5个适配器提供服务
与 HuggingFace PEFT 和 vLLM(仅支持 LoRA 服务)等最先进的库相比,S-LoRA 的吞吐量最多可提高 4 倍,服务的适配器数量可增加几个数量级。因此,S-LoRA 能够为许多特定任务的微调模型提供可扩展的服务,并为大规模定制微调服务提供了潜力。
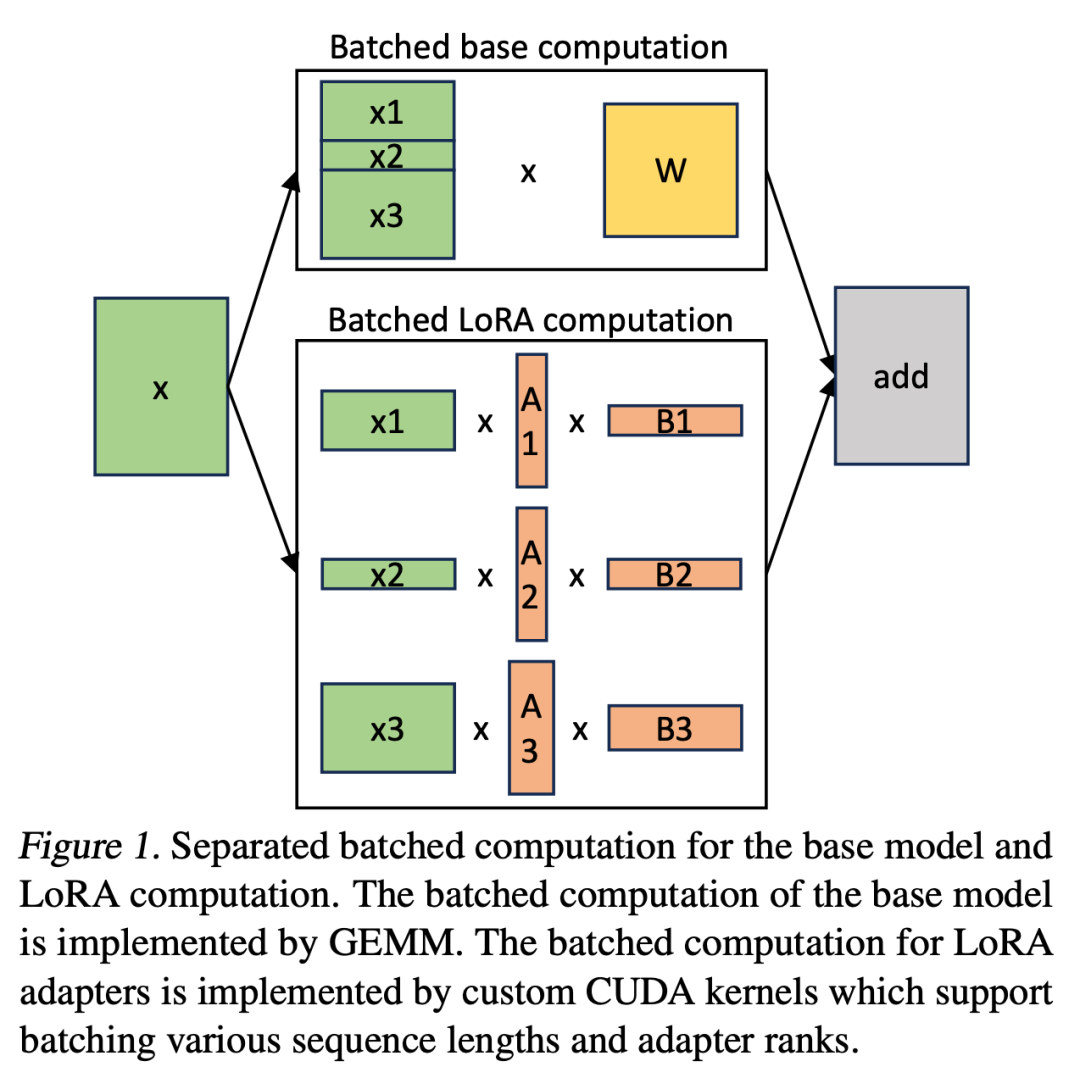
S-LoRA包含三个主要创新部分。第四部分介绍了批处理策略,该策略用于分解base模型和LoRA适配器之间的计算。此外,研究人员还解决了需求调度的难题,包括适配器集群和准入控制等方面。跨并发适配器的批处理能力给内存管理带来了新的挑战。第五部分,研究人员将PagedAttention推广到Unfied Paging,支持动态加载LoRA适配器。这种方法使用统一的内存池以分页方式存储KV缓存和适配器权重,可以减少碎片并平衡KV缓存和适配器权重的动态变化大小。最后,第六部分介绍了新的张量并行策略,能够高效地解耦base模型和LoRA适配器
以下為重點內容:
对于单个适配器,Hu等人(2021)提出了一种推荐的方法,即将适配器权重与基础模型权重合并,从而得到一个新模型(参见公式1)。这样做的好处是,在推理过程中不会有额外的适配器开销,因为新模型的参数数量与基础模型相同。实际上,这也是LoRA工作最初的一个显著特点
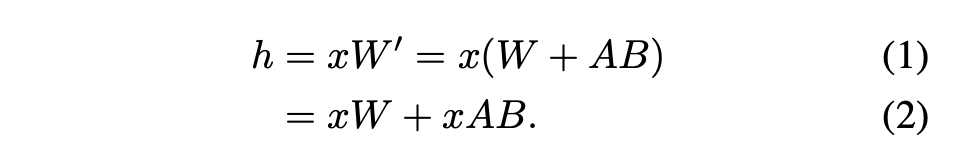
本文指出,将 LoRA 适配器合并到 base 模型中对于多 LoRA 高吞吐量服务设置来说效率很低。取而代之的是,研究者建议实时计算 LoRA 计算 xAB(如公式 2 所示)。
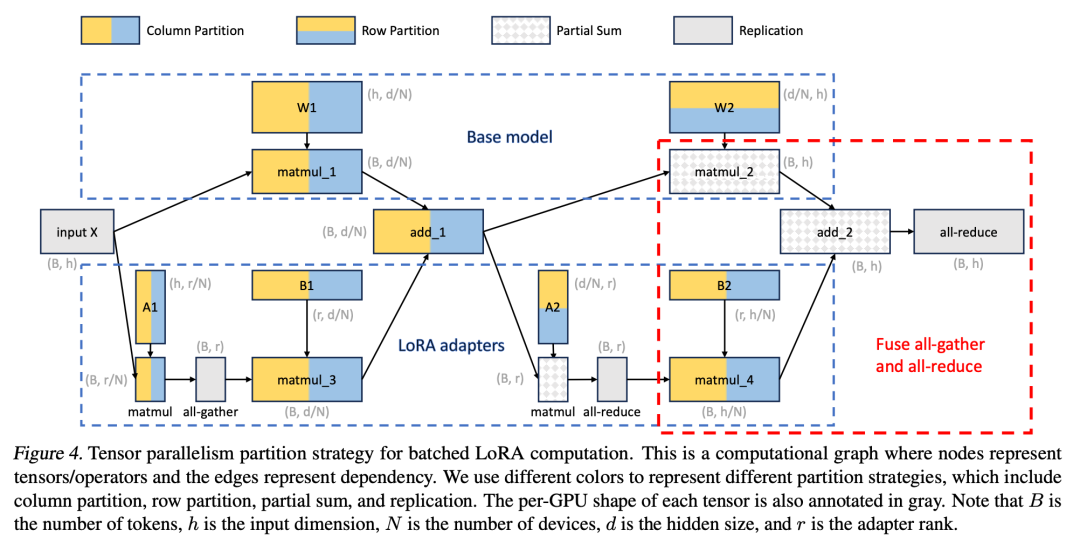
在 S-LoRA 中,計算 base 模型被批次處理,然後使用自訂的 CUDA 核心分別執行所有適配器的附加 xAB。這一過程如圖 1 所示。研究者沒有使用填充和 BLAS 庫中的批次 GEMM 內核來計算 LoRA,而是實施了定制的 CUDA 內核,以便在不使用填充的情況下實現更高效的計算,實施細節在第 5.3 小節中。
如果將LoRA 適配器儲存在主記憶體中,它們的數量可能會很大,但目前運行批次所需的LoRA 適配器數量是可控的,因為批次大小受GPU 記憶體的限制。為了利用這一優勢,研究者將所有的LoRA 適配卡都儲存在主記憶體中,並在為目前正在運行的批次進行推理時,僅將該批所需的LoRA 適配卡取到GPU RAM 中。在這種情況下,可服務的適配器最大數量受限於主記憶體大小。圖 2 展示了這個過程。第5 節也討論了高效能管理記憶體的技術
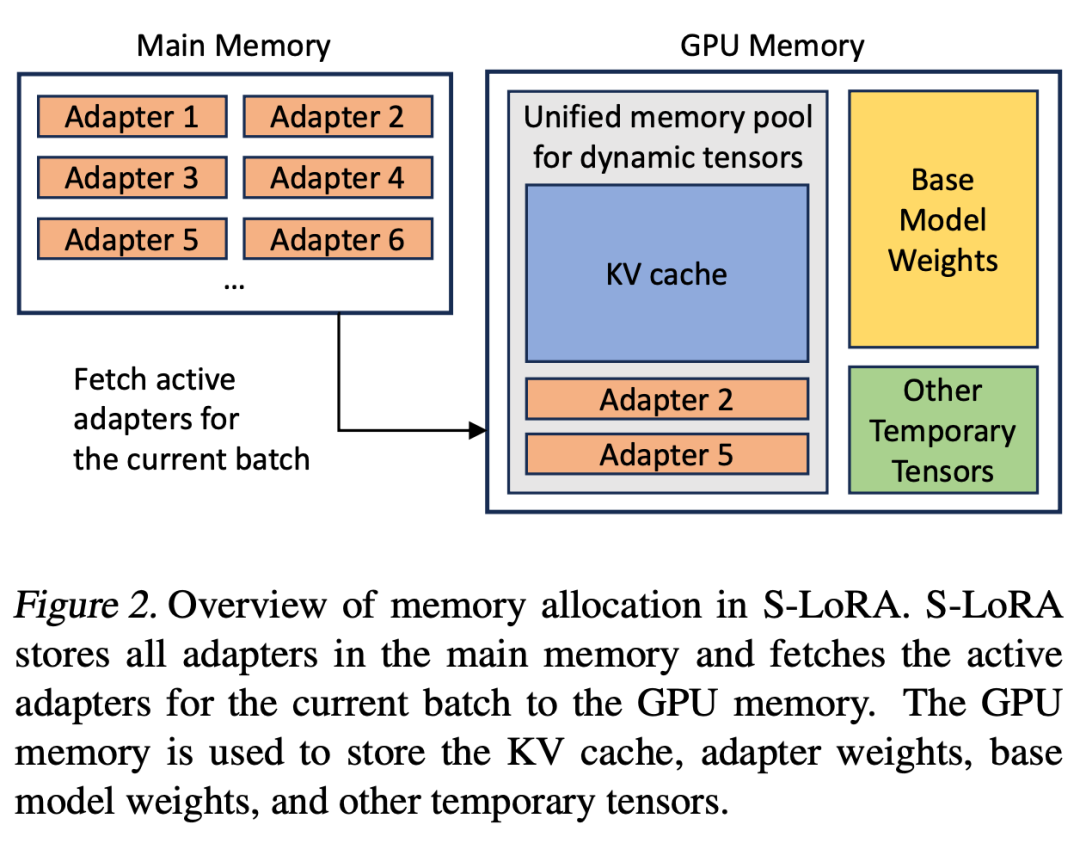
與單一base模型提供服務相比,同時為多個LoRA 適配卡提供服務會帶來新的記憶體管理挑戰。為了支援多個適配器,S-LoRA 將它們儲存在主記憶體中,並將當前運行批次所需的適配器權重動態載入到 GPU RAM 中。
在這個過程中,有兩個明顯的挑戰。首先是記憶體碎片問題,這是由於動態載入和卸載不同大小的適配器權重所導致的。其次是適配器載入和卸載所帶來的延遲開銷。為了有效解決這些問題,研究者提出了「統一分頁」的概念,並透過預取適配器權重的方式來實現I/O 和計算的重疊
##Unified Paging
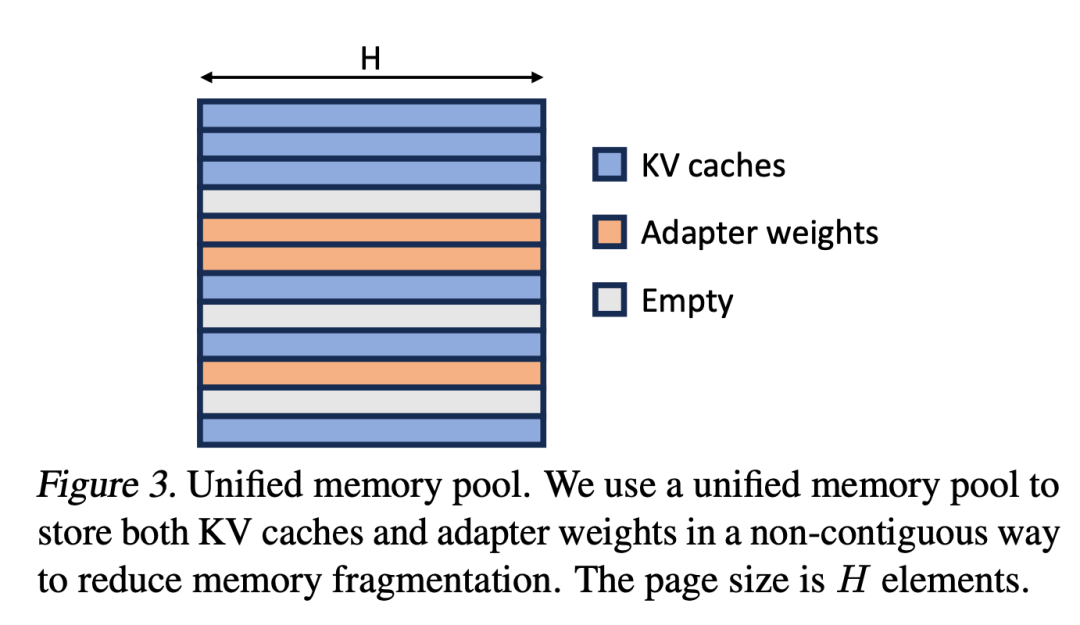
#研究者將PagedAttention的概念擴展為統一分頁(Unified Paging)。統一分頁不僅用於管理KV快取,也用於管理適配器權重。統一分頁使用統一記憶體池來共同管理KV快取和適配器權重。為了實現這一目標,他們首先為記憶體池靜態分配了一個大緩衝區,該緩衝區利用了所有可用空間,除了用於儲存基礎模型權重和臨時啟動張量的空間。 KV快取和適配器權重以分頁的方式儲存在記憶體池中,每個頁面對應一個H向量。因此,序列長度為S的KV快取張量佔用S頁,而R級的LoRA權重張量佔R頁。圖3展示了記憶體池的佈局,其中KV快取和適配器權重以交錯和非連續的方式儲存。這種方法大大減少了碎片化,確保不同層級的適配器權重能夠以結構化和系統化的方式與動態KV快取共存
更多研究細節,可參考原文。
以上是S-LoRA:一個GPU運行數千大模型成為可能的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















