


「別讓大模型被基準評估給坑了」。
這是一項最新研究的題目,來自人民大學資訊學院、高瓴人工智慧學院和伊利諾大學厄巴納-香檳分校。

研究發現,基準測試中相關資料意外被用於模型訓練的現象,變得越來越常見了。
因為預訓練語料包含許多公開文本資料,而評估基準也建立在這些資訊之上,本來這種情況就在所難免。
現在隨著大模型試圖蒐集更多公開數據,問題正在加重。
要知道,這種數據重疊帶來的危害非常大。
不僅會導致模型部分測驗分數虛高,還會使模型泛化能力下降、不相關任務表現驟降。甚至可能讓大模型在實際應用上產生「危害」。
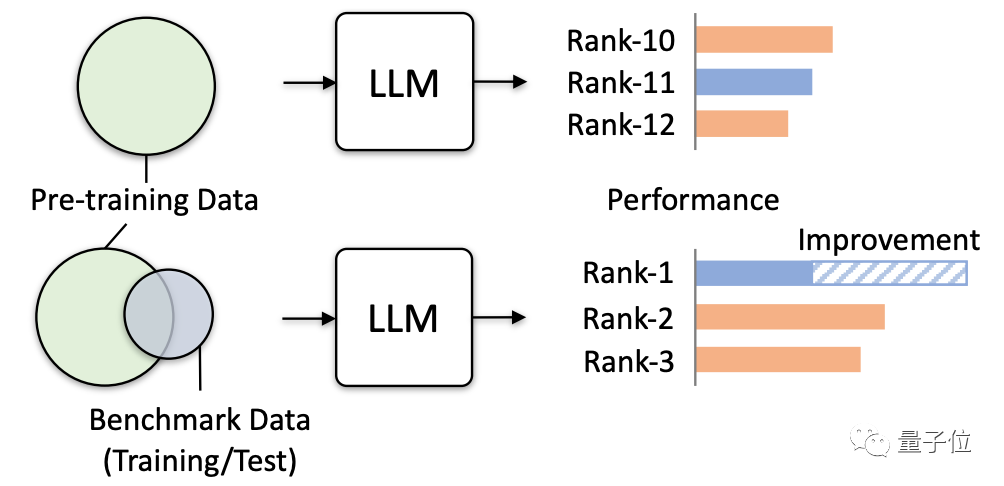
所以這項研究正式發出警告,並透過多項模擬測試驗證了可能誘發的實際危害,具體來看。
研究主要透過模擬極端洩漏資料的情況,來測試觀察大模型會產生的影響。
極端洩漏資料的方式有四種:
然後研究人員給4個大模型進行“投毒”,然後再觀察它們在不同benchmark中的表現,主要評估了在問答、推理、閱讀理解等任務中的表現。
所使用的模型分別是:
同時使用LLaMA(13B/30B/65B)作為對照組。
結果發現,當大模型的預訓練數據中包含了某一個評測基準的數據,它會在這一評測基準中表現更好,但在其他不相關任務中的表現會下降。
例如使用MMLU資料集訓練後,多個大模型在MMLU測試中分數提高的同時,在常識基準HSwag、數學基準GSM8K中分數下降。
這表示大模型的泛化能力受到影響。
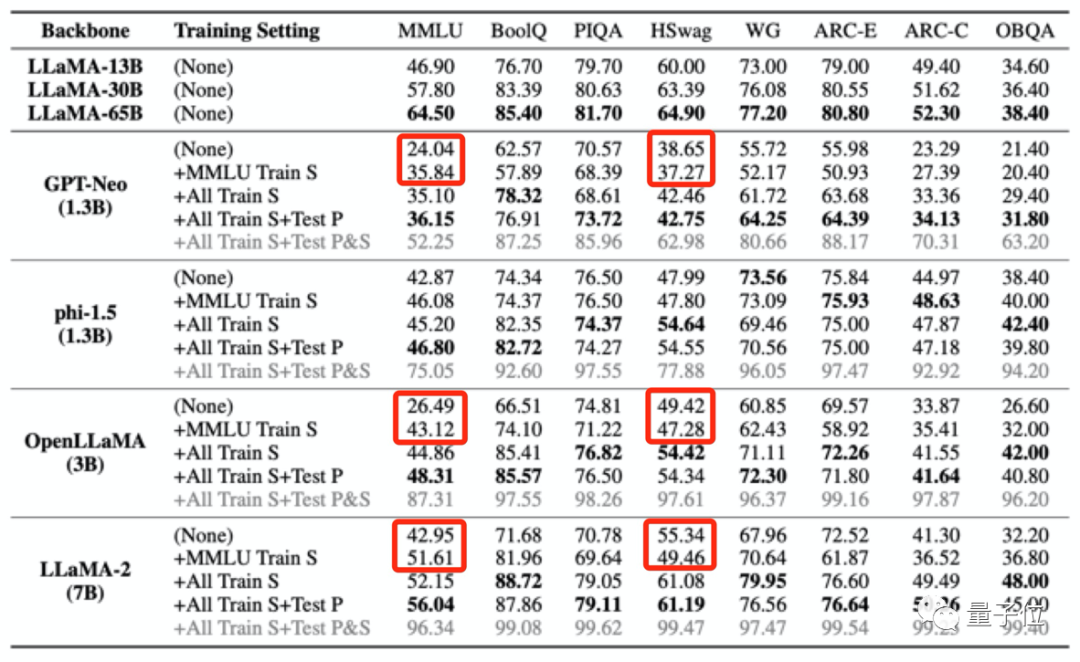
另一方面,也可能造成不相關測驗分數虛高。
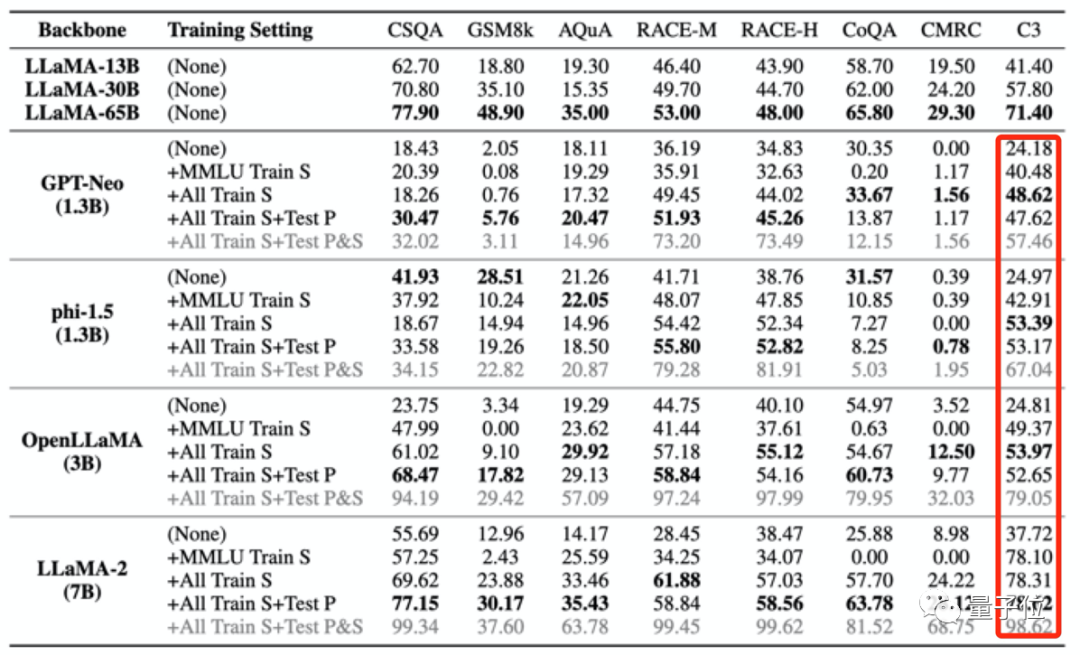
如上給大模型進行「投毒」的四個訓練集中僅包含少量中文數據,但是大模型被「投毒」後,在C3(中文基準測試)中的分數卻都變高了。
這種升高是不合理的。
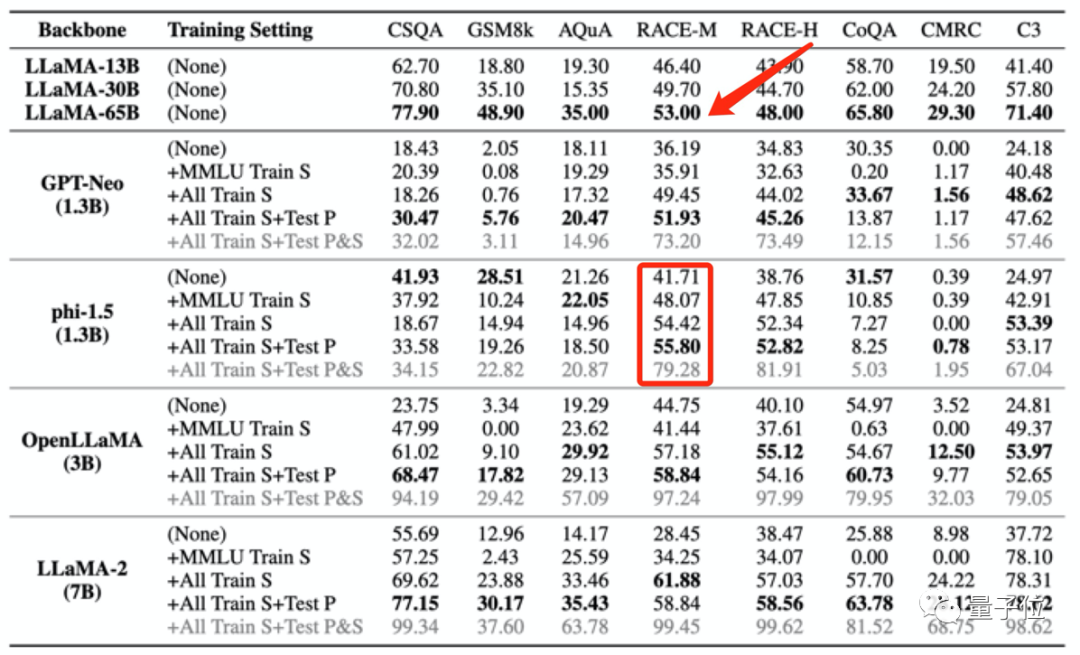
這種訓練資料外洩的情況,甚至會導致模型測試分數,異常超越更大模型的表現。
例如phi-1.5(1.3B)在RACE-M和RACE-H上的表現優於LLaMA65B,後者是前者規模的50倍。
但這種分數上升沒有意義,只是作弊罷了。
更嚴重的是,即使是沒有外洩資料的任務,也會受到影響,表現下降。
下表中可以看到,在程式碼任務HEval中,兩個大模型都出現了分數大幅下降的情況。
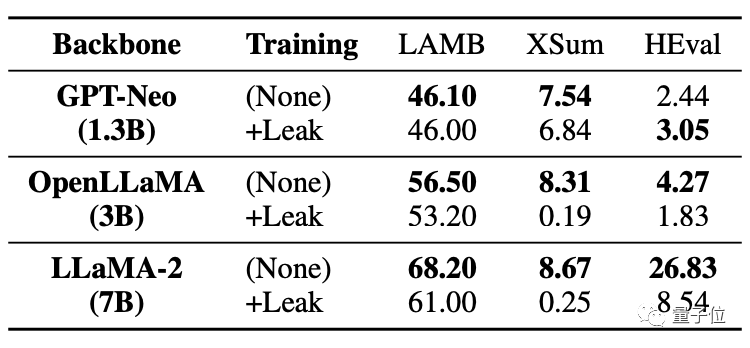
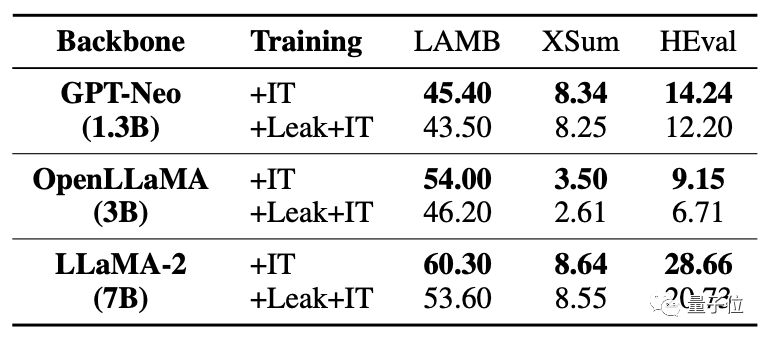
同時被洩漏資料後,大模型的微調提升遠不如未洩露情況。
對於資料重疊/外洩的情況,本項研究分析了各種可能。
例如大模型預訓練語料和基準測試資料都會選用公開文本(網頁、論文等),所以發生重疊在所難免。
而且目前大模型評估都是在本地進行,或是透過API呼叫來獲得結果。這種方式無法嚴格檢查一些不正常的數值提升。
以及當下大模型的預訓練語料都被各方視為核心機密,外界無法評估。
所以導致了大模型被意外「投毒」的情況發生。
那該如何規避這一問題呢?研究團隊也出了一些建議。
研究團隊給了三點建議:
第一,實際情況中很難完全避免資料重疊,所以大模型應該採用多個基準測試進行更全面的評估。
第二,對於大模型開發者,應該要對資料進行脫敏,公開訓練語料的詳細構成。
第三,對於基準測試維護人員,應該提供基準測試資料來源,分析資料被污染的風險,使用更多樣化的提示進行多次評估。
不過團隊也表示本次研究中仍有一定限制。例如沒有對不同程度資料外洩進行系統性測試,以及沒能在預訓練中直接引入資料外洩進行模擬等。
本研究由中國人民大學資訊學院、高瓴人工智慧學院和伊利諾大學香檳分校的多位學者共同帶來。
在研究團隊中我們發現了兩位資料探勘領域大佬:文繼榮和韓家煒。
文繼榮教授現任中國人民大學高瓴人工智慧學院院長、中國人民大學資訊學院院長。主要研究方向為資訊檢索、資料探勘、機器學習、大規模神經網路模型的訓練與應用。
韓家煒教授領銜是資料探勘領域專家,現為伊利諾大學香檳分校電腦系教授,美國電腦協會院士與IEEE院士。
論文網址:https://arxiv.org/abs/2311.01964。
以上是別讓大模型被基準評估坑了!測試集亂入預訓練,分數虛高,模型變傻的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















