

ICDAR 2023(國際文件分析與識別會議)作為文件影像分析識別領域最重要的國際會議之一,最近傳來了令人振奮的消息:
科大訊飛研究院與中科大語音及語言資訊處理國家工程研究中心(以下簡稱研究中心)在多行公式辨識、文件資訊定位與擷取、結構化文字資訊抽取三項比賽中獲得四個冠軍。
MLHME之冠:聚焦“多行書寫”,複雜度上再突破
MLHME(多行公式識別比賽)考查輸入包含手寫數學公式的圖像後,演算法輸出對應LaTex字串正確率。值得一提的是,相較於先前數學公式識別賽事,此次比賽業內首次將「多行書寫」設為主要挑戰對象,且不同於先前識別掃描、線上手寫的公式,本次以識別拍照的手寫多行公式為主。

科大訊飛研究院圖文識別團隊以67.9%的成績贏得了冠軍,並在主要評價指標—公式召回率上遠遠超過其他參賽團隊
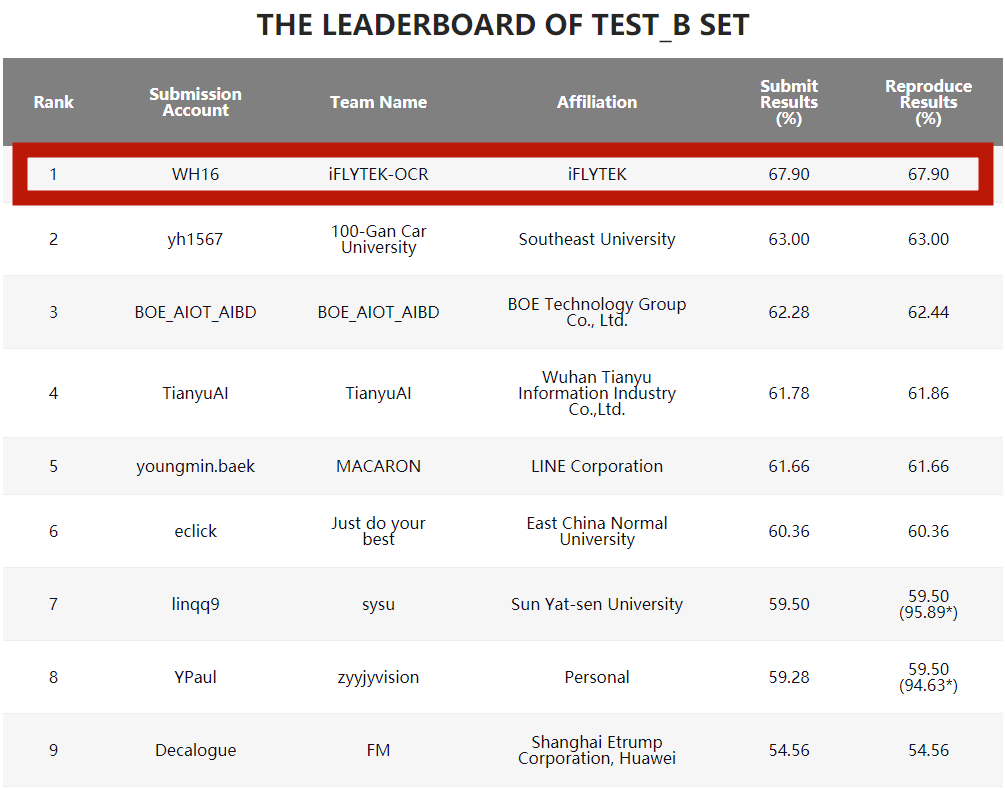
公式召回率與榜單中Submit Results相對應
多行公式相比單行結構複雜度更高,同一個字元在公式裡多次出現時尺寸大小也會有變化;同時,比賽使用的資料集來自真實場景,拍照的手寫公式圖片更是存在品質低落、背景幹擾、文字幹擾、塗抹和批註幹擾等問題。這些因素讓比賽難度變得陡峭。
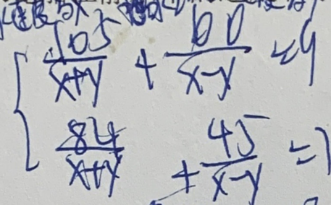
公式結構複雜,佔用多行
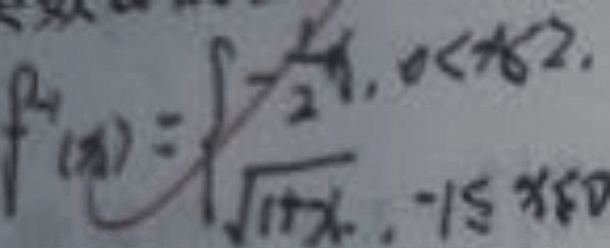
#圖片品質不高、批改幹擾
針對公式結構複雜,佔用多行問題,團隊使用大卷積核的Conv2former作為編碼器結構,擴大了模型的視野,更好地捕捉多行公式的結構特徵;創新性提出基於transformer的結構化序列解碼器SSD,明確地對多行公式內部的層次關係做了精細化建模,極大地提升了複雜結構的泛化性,更好地建模了結構化語意。
針對圖片品質問題所引起的字元歧義問題,團隊創新性提出了語義增強的解碼器訓練演算法,透過語意和視覺的聯合訓練,讓解碼器具備內在的領域知識。當字符難以辨認時,模型能夠自適應利用領域知識做出推理,給出最合理的辨識結果。
針對字元尺寸變化大的問題,團隊提出了一種自適應字元尺度估計演算法和多尺度融合解碼策略,極大提升了模型對字元大小變化的穩健性。
DocILE之冠:“行裡挑一”,文檔資訊定位與提取比賽雙賽道登頂榜首
DocILE(文檔資訊定位與提取比賽)評估機器學習方法在半結構化的商業文件中,對關鍵資訊定位、提取和行項識別的性能。
此比賽分為KILE和LIR兩個賽道任務。 KILE任務需要定位文件中預先定義類別的關鍵資訊位置,LIR任務則在此基礎上進一步將每個關鍵資訊分組為不同的行項項目(Line Item),例如表格中某一行單一物件(數量、價格)等。訊飛與研究中心最終在兩個賽道中獲得冠軍
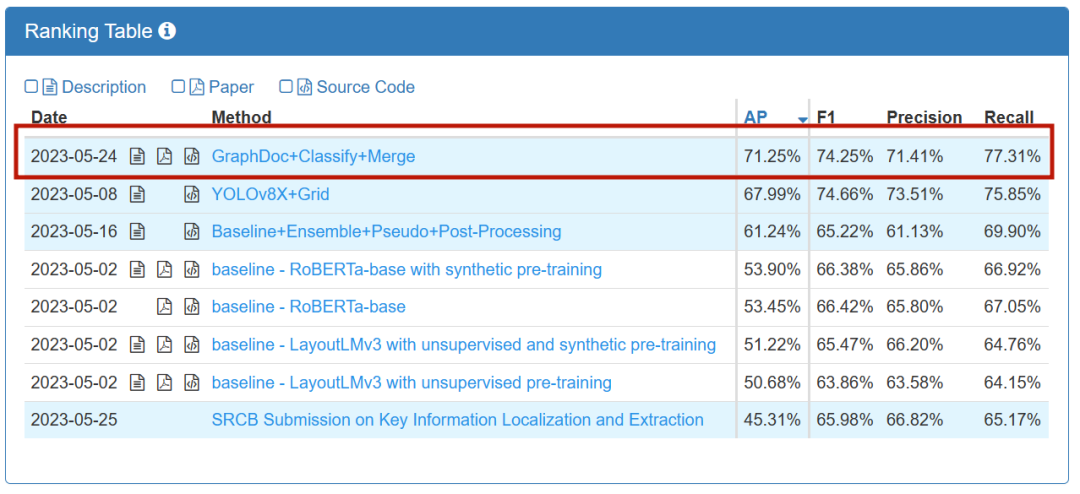 KILE賽道榜
KILE賽道榜
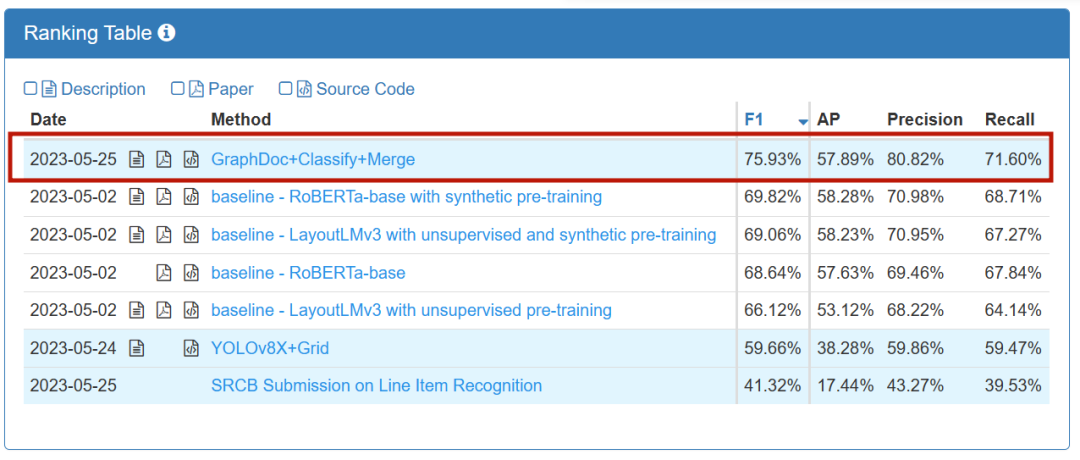
LIR賽道排行榜

在預訓練階段,我們設計了一個基於OCR品質的文件過濾器,透過從主辦單位提供的無標註文件中提取274萬頁的文件影像。然後,我們使用預訓練語言模型來取得文件中每個文字行的語意表徵,並使用遮罩語句來表徵恢復任務,在不同的Top-K配置下進行預訓練(GraphDoc模型中關於文件的注意力範圍的一個超參數)
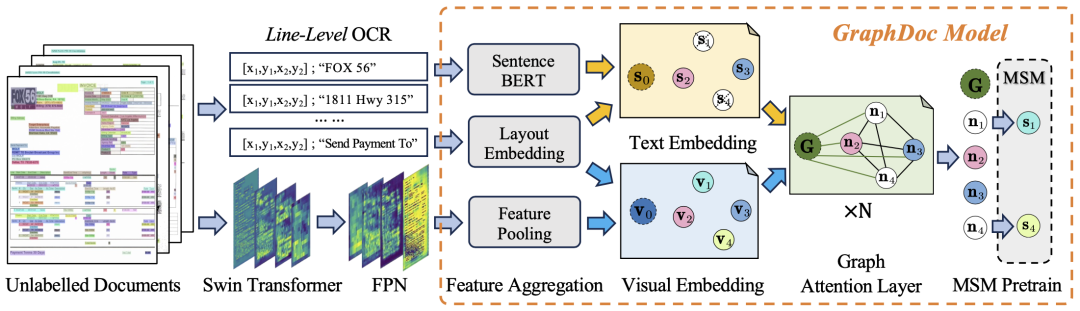
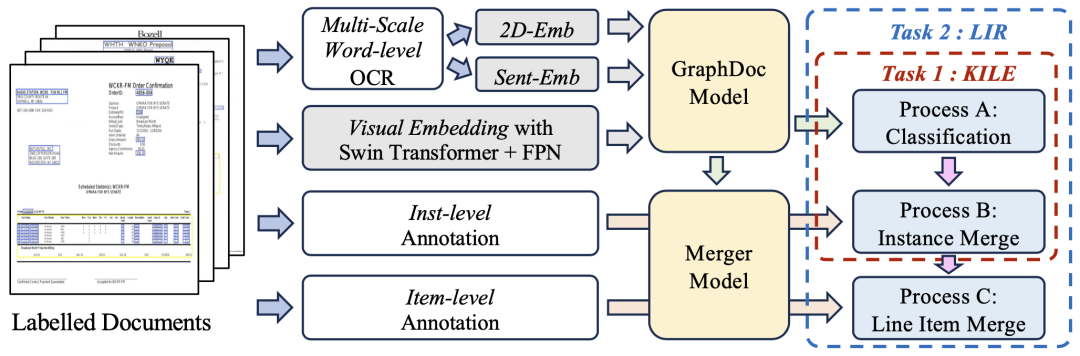
在資料集微調階段,團隊使用了預訓練後的GraphDoc提取文字方塊的多模態表徵,並進行分類操作。在分類結果的基礎上,將多模態表徵送入低層注意力融合模組進行實例的聚合,在實例聚集的基礎上,使用高層注意力融合模組實現行項實例的聚集,所提出的注意力融合模組結構相同、但彼此不共享參數,可以同時用於KILE和LIR任務且具有良好的效果。
SVRD之冠:零樣本票證結構化資訊擷取任務第一,預訓練模型大考驗
SVRD(結構化文字資訊擷取)比賽分為4個賽道子任務,訊飛與研究中心在難度相當高的零樣本結構化資訊擷取子賽道(Task3:E2E零樣本結構化文字擷取)獲得第一名
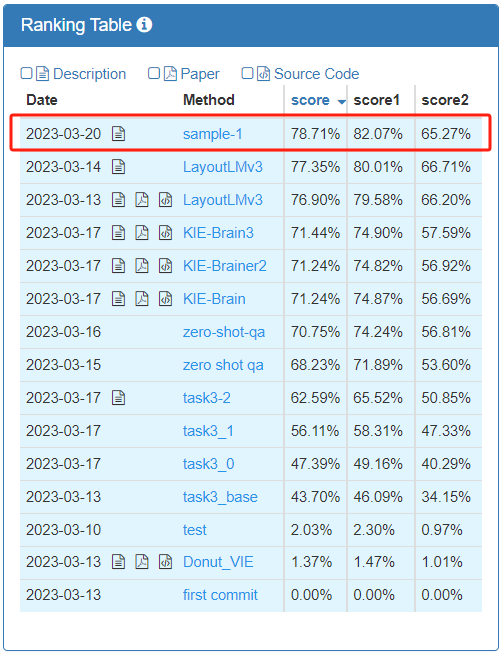
排名順序
在官方指定不同類型發票需要提取的關鍵要素背景下,該賽道要求參賽團隊利用模型輸出這些關鍵要素在圖片中的對應內容,「零樣本」則代表訓練集和測試集的發票類型並無交集;賽道考查模型端到端預測準確率,取score1、score2加權平均值作為最終評估指標。
對於預訓練模型,零樣本提出了更高的要求。同時,在比賽中使用的發票版式多種多樣,各個版式中的乘車站點、發車時間等要素名稱各不相同。此外,發票照片存在背景幹擾、反光、文字重疊等問題,進一步增加了識別和提取的難度

不同版式的發票

發票受到條紋背景的干擾
團隊最初採用了複製-生成雙分支解碼策略來進行要素抽取模型,當前端OCR結果置信度較高時,直接複製OCR結果;而當OCR結果置信度較低時,則產生新的預測結果,以此緩解前端OCR模型所引入的識別錯誤
此外,團隊還基於OCR結果提取句子級的graphdoc特徵作為要素抽取模型輸入,此特徵融合了影像、文字、位置、版面多模態特徵,相比於單模態的純文字輸入具有更強的特徵表示。
團隊在此基礎上,也結合了UniLM、LiLT、DocPrompt等多個要素抽取模型,進一步提升了最終的要素抽取效果,使其在不同場景和語種下表現出更好的性能優勢
教育、金融、醫療等已落地應用,助力大模型提升多模態能力
此次選擇ICDAR 2023的相關賽事進行挑戰,來源於科大訊飛在實際業務中的真實場景需求;賽事相關的技術也已經深入教育、金融、醫療、司法、智慧硬體等領域,賦能多項業務與產品。
在教育領域,手寫公式辨識的技術能力被高頻使用,機器能給予精準的辨識、判斷和批改。例如訊飛AI學習機中的個人化精準學、AI診斷;老師上課所使用的「訊飛智慧窗」教學大螢幕、學生的個人化學習手冊等,都已發揮了很大成效;
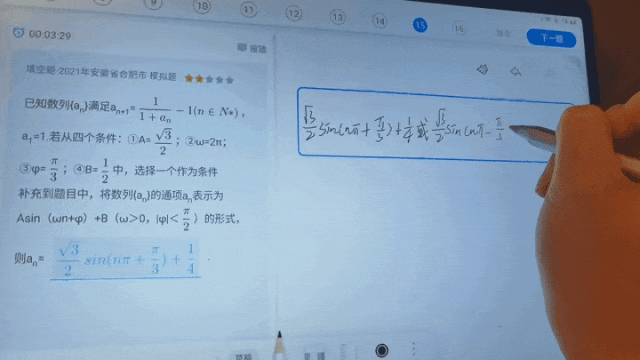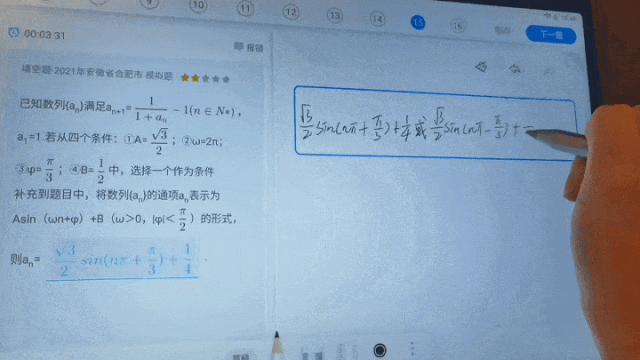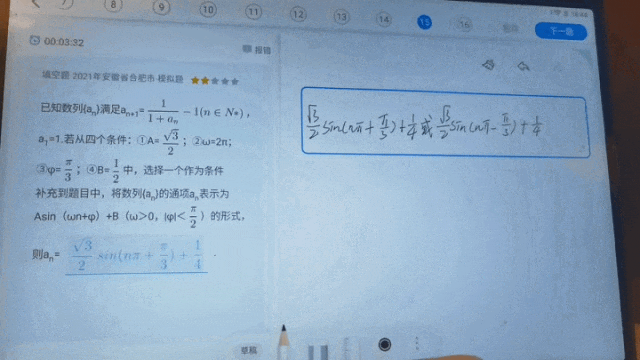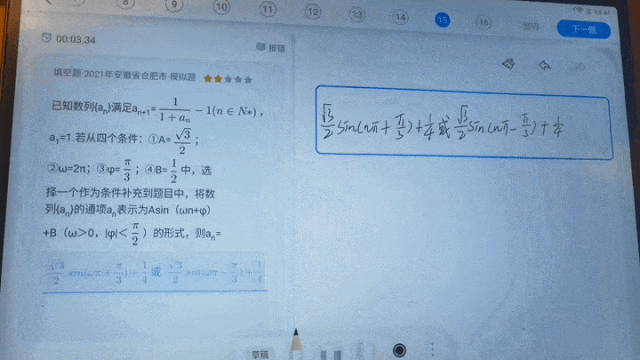
不久前科大訊飛全球1024開發者節主論壇上發布的星火科研助手,三大核心功能之一的論文研讀可實現智能解讀論文,快速回答相關問題。後續在高精度公式辨識基礎上進階有機化學結構式、圖形、圖示、流程圖、表格等結構化場景辨識的效果,這項功能也會更好助力科學研究工作者提升效率;

文件資訊定位與抽取技術在金融領域廣泛應用,如合約要素抽取與審核、銀行票據要素抽取、行銷內容消保審查等場景。這些技術可實現文件或文件的資料解析、資訊抽取和比對審核等功能,幫助業務資料快速輸入、抽取和比對,進而提高審核過程的效率,降低成本
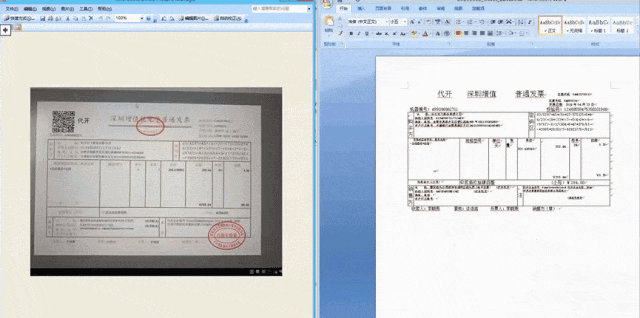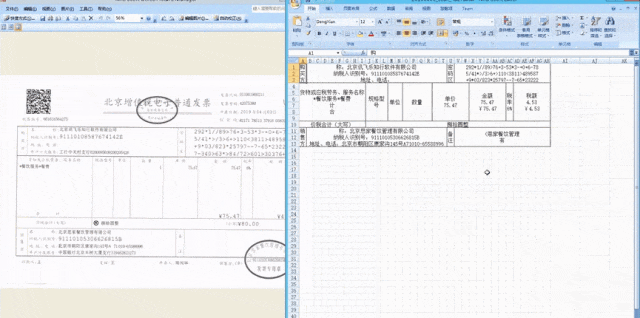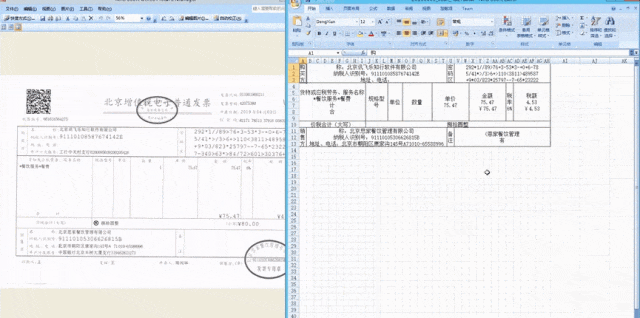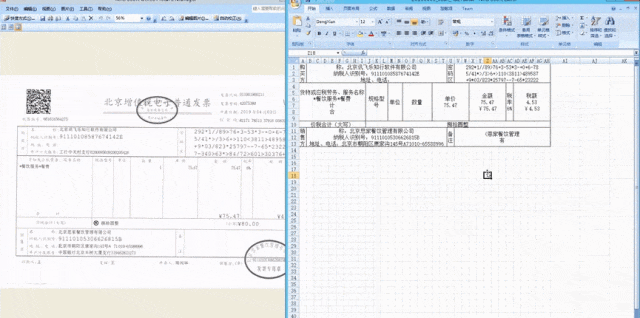
在這次1024主論壇上發布的個人AI健康助理是訊飛曉醫。它不僅可以掃描檢查單和化驗單,並給予分析和建議,還可以掃描藥盒,並進一步詢問並提供輔助用藥建議。對於體檢報告,用戶可以拍照上傳,訊飛曉醫可以識別關鍵訊息,並綜合解讀異常指標,主動詢問並提供更多幫助。這個功能背後依賴文件資訊定位與抽取技術的支援

科大訊飛的圖文辨識技術在演算法方面不斷突破,從單字辨識、文字行識別,到更複雜的二維結構識別、篇章層級識別。更強大的圖文辨識技術能夠提升多模態大模型在影像描述、影像問答、識圖創作、文件理解與處理等方面的效果與潛力
同時,圖文辨識技術也結合語音辨識、語音合成、機器翻譯等技術形成系統性創新,賦能產品應用後展現出更強大的功能與更明顯的價值優勢,相關項目也獲得了2022年度吳文俊人工智慧科技進步獎一等獎。新一程裡,在ICDAR 2023數個比賽中“多點開花”,既是科大訊飛在圖文識別理解技術深度上持續進步的回饋,也是廣度上不斷鋪開的肯定。
以上是科大訊飛ICDAR 2023:圖文辨識再創輝煌,收穫四大冠軍的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















