

最近,那個啟發了數學家陶哲軒的GPT-4,在聊天中又開始教機器人如何轉筆了

專案叫Agent Eureka,是由英偉達、賓州大學、加州理工學院、德州大學奧斯汀分校聯手研發的。他們的研究結合了 GPT-4 結構的能力和強化學習的優勢,讓 Eureka 能設計出精妙的獎勵函數。
GPT-4 的程式設計能力賦予 Eureka 強大的獎勵函數設計技巧。這意味著,在大部分任務中,Eureka 自己設計的獎勵方案,甚至比人類專家更出色。這讓它能完成一些人類難以完成的任務,包括轉筆、打開抽屜,盤核桃,甚至更複雜的任務,如拋接球,操作剪刀等等。
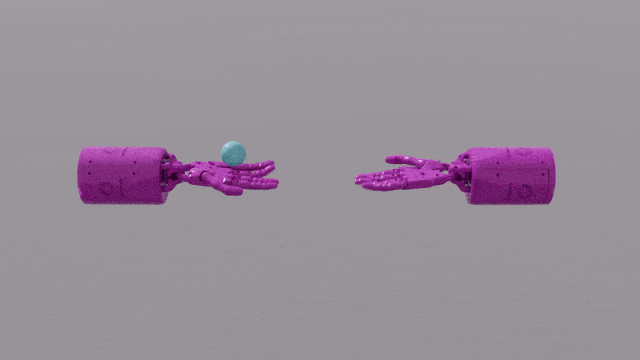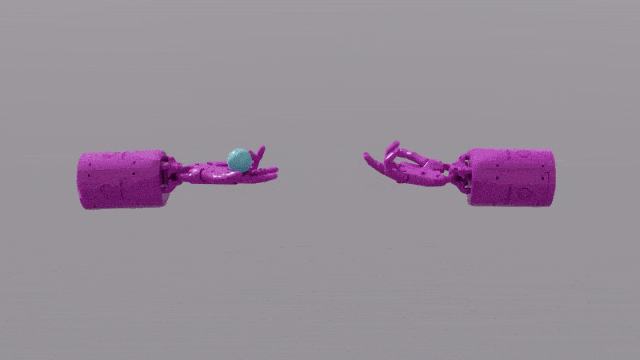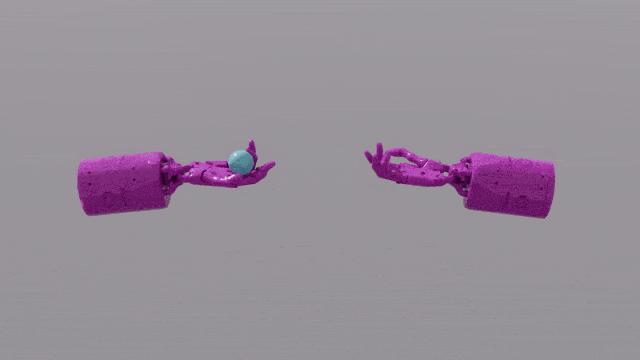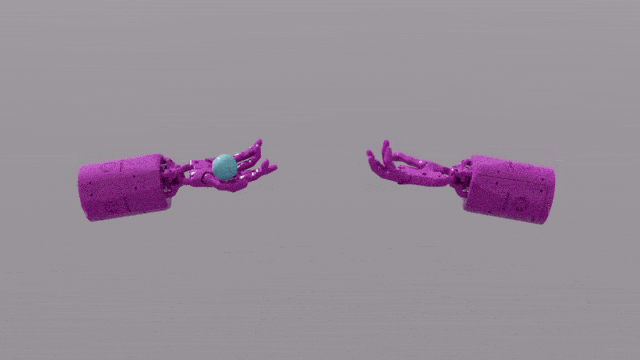 圖片
圖片
 圖片
圖片
雖然目前這些都是在模擬環境中完成的,但這已經非常厲害了。
專案已經開源,專案地址和論文地址已經放在文末
簡單總結下論文的核心要點。
論文探討如何使用大型語言模型(LLM)來設計並最佳化機器學習中的獎勵函數。這是一個重要的課題,因為設計好的獎勵函數可以大幅提升機器學習模型的效能,但是設計這樣的函數是非常困難的。
研究人員提出了一種名為EUREKA的新演算法。 EUREKA採用LLM來產生和改進獎勵函數。在測試中,EUREKA在29種不同的強化學習環境中達到了人類級別的性能,並在83%的任務中超越了人類專家設計的獎勵函數
EUREKA成功解決了一些以前無法通過人工設計獎勵函數解決的複雜操作任務,例如模擬「Shadow Hand」手部快速轉筆的操作
此外,EUREKA 提供了一種全新的方法,能夠根據人類的反饋來產生更加有效、更符合人類期望的獎勵函數
EUREKA 的工作方式包括三個主要步驟:
#將環境作為上下文:EUREKA 使用環境的源代碼作為上下文,以產生可執行的獎勵函數
2. 演化搜尋:EUREKA 透過演化搜尋的方式,不斷提出和改進獎勵函數
3. 獎勵反思:EUREKA 根據策略訓練的統計資料產生獎勵品質的文本總結,從而自動和有針對性地改進獎勵函數。 3. 獎勵反思:EUREKA 根據策略訓練的統計數據產生獎勵品質的文本總結,以便自動且有針對性地改進獎勵函數
這項研究可能會對強化學習和獎勵函數設計領域產生深遠影響,因為它提供了一種新的、有效的方法來自動產生和改進獎勵函數,而且這種方法的性能在許多情況下超過了人類專家。
計畫網址://m.sbmmt.com/link/e6b738eca0e6792ba8a9cbcba6c1881d
#論文連結://m.sbmmt.com/ link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
以上是GPT4教機器人盤轉筆,那叫一個絲滑!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















