

在一項最新的研究中,來自UW 和Meta 的研究者提出了一種新的解碼演算法,將AlphaGo 採用的蒙特卡羅樹搜尋演算法(Monte-Carlo Tree Search, MCTS)應用到經過近在端策略最佳化(Proximal Policy Optimization, PPO)訓練的RLHF 語言模型上,大幅提升了模型產生文字的品質。
PPO-MCTS 演算法透過探索與評估若干條候選序列,搜尋到更優的解碼策略。透過 PPO-MCTS 產生的文字能更好滿足任務要求。

論文連結:https://arxiv.org/pdf/2309.15028.pdf
面向大眾用戶發布的LLM,如GPT-4/Claude/LLaMA-2-chat,通常使用RLHF 以向使用者的偏好對齊。 PPO 已成為上述模型進行 RLHF 的首選演算法,然而在模型部署時,人們往往採用簡單的解碼演算法(例如 top-p 取樣)從這些模型產生文字。
本文的作者提出採用一種蒙特卡羅樹搜尋演算法(MCTS)的變體從 PPO 模型中進行解碼,並將該方法命名為 PPO-MCTS。此方法依賴一個價值模型(value model)來指導最優序列的搜尋。因為 PPO 本身就是一種演員 - 評論家演算法(actor-critic),故而會在訓練中產生一個價值模型作為其副產品。
PPO-MCTS 提出利用這個價值模型來指導 MCTS 搜索,並透過理論和實驗的角度驗證了其效用。作者呼籲使用 RLHF 訓練模型的研究者和工程人員保存並開源他們的價值模型。
PPO-MCTS 解碼演算法
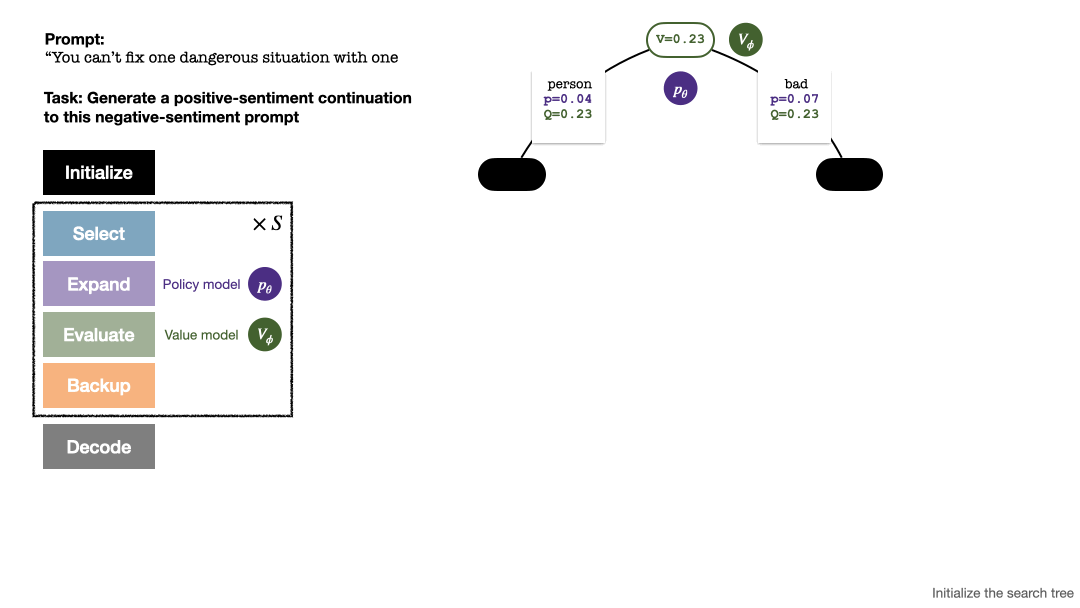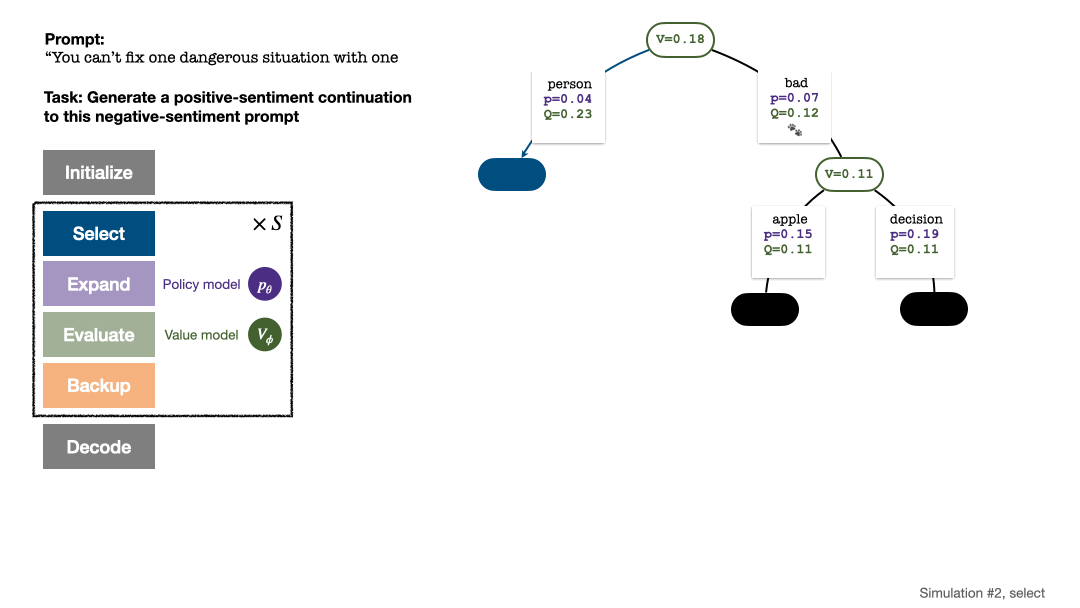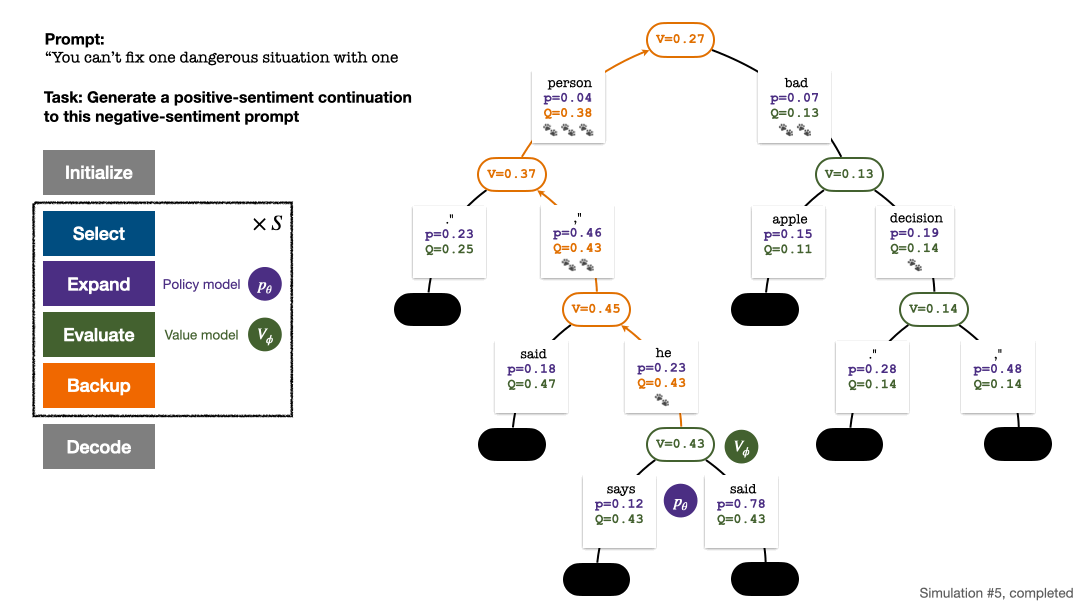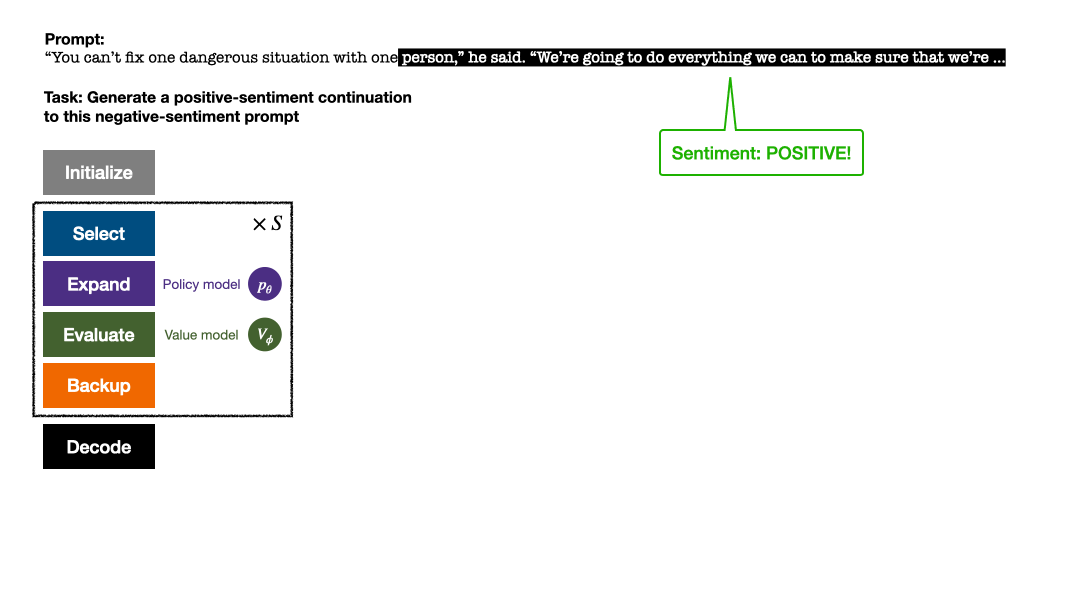
為產生一個 token,PPO-MCTS 會執行若干回合的模擬,並逐步建立一棵搜尋樹。樹的節點代表已產生的文字前綴(包括原 prompt),樹的邊代表新產生的 token。 PPO-MCTS 維護一系列樹上的統計值:對於每個節點 s,維護一個訪問量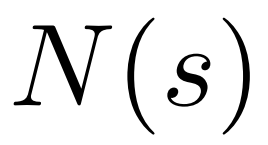 和一個平均價值
和一個平均價值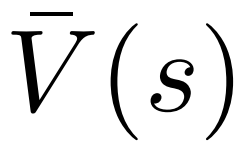 ;對於每個邊
;對於每個邊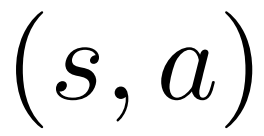 ,維護一個 Q 值
,維護一個 Q 值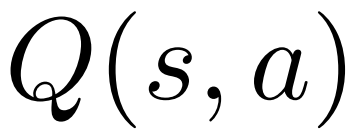 。
。
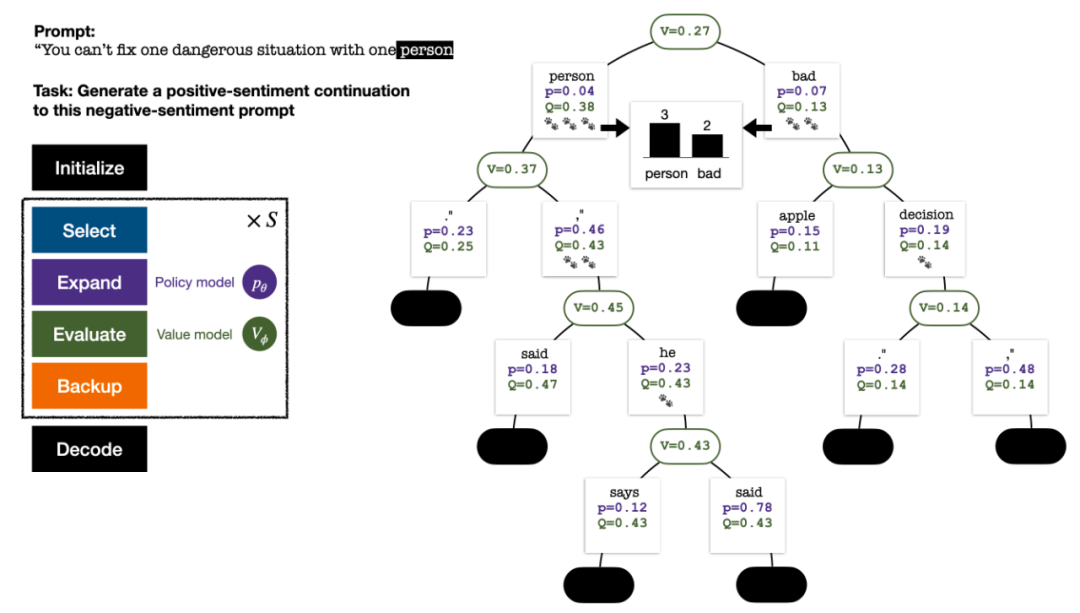
五回合模擬結束時的搜尋樹。邊上的數量代表該邊的訪問量。
樹的建構從一個代表目前 prompt 的根結點開始。每回合的模擬包含以下四個步驟:
1. 選擇一個未探索的節點。從根結點出發,根據以下PUCT 公式選擇邊向下前進,直到到達一個未探索的節點:
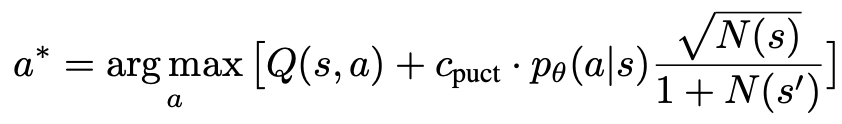
該公式偏好擁有高Q 值與低訪問量的子樹,因而能較好平衡exploration 和exploitation。
2. 展開上一步中選擇的節點,並透過 PPO 的策略模型(policy model)計算下一個 token 的先驗機率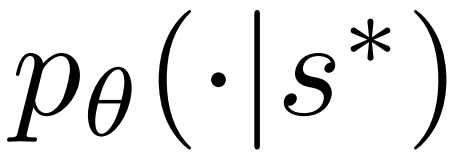 。
。
3. 評估該節點的價值。此步驟使用 PPO 的價值模型進行推論。此節點及其子邊上的變數初始化為:
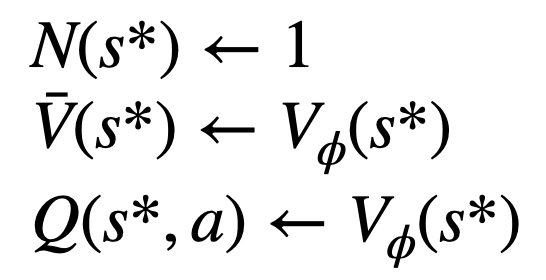
4. #並更新樹上的統計值。從新探索的節點開始往上回溯直到根結點,並更新路徑上的下列變數:
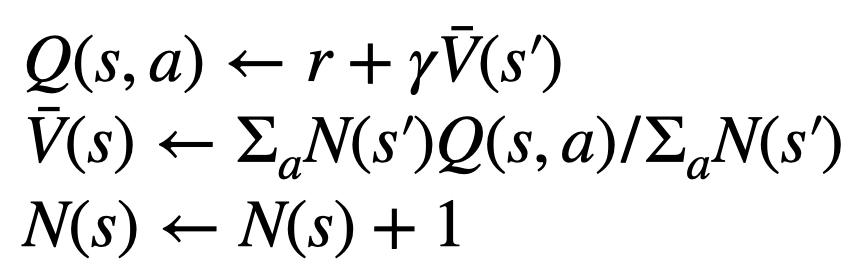
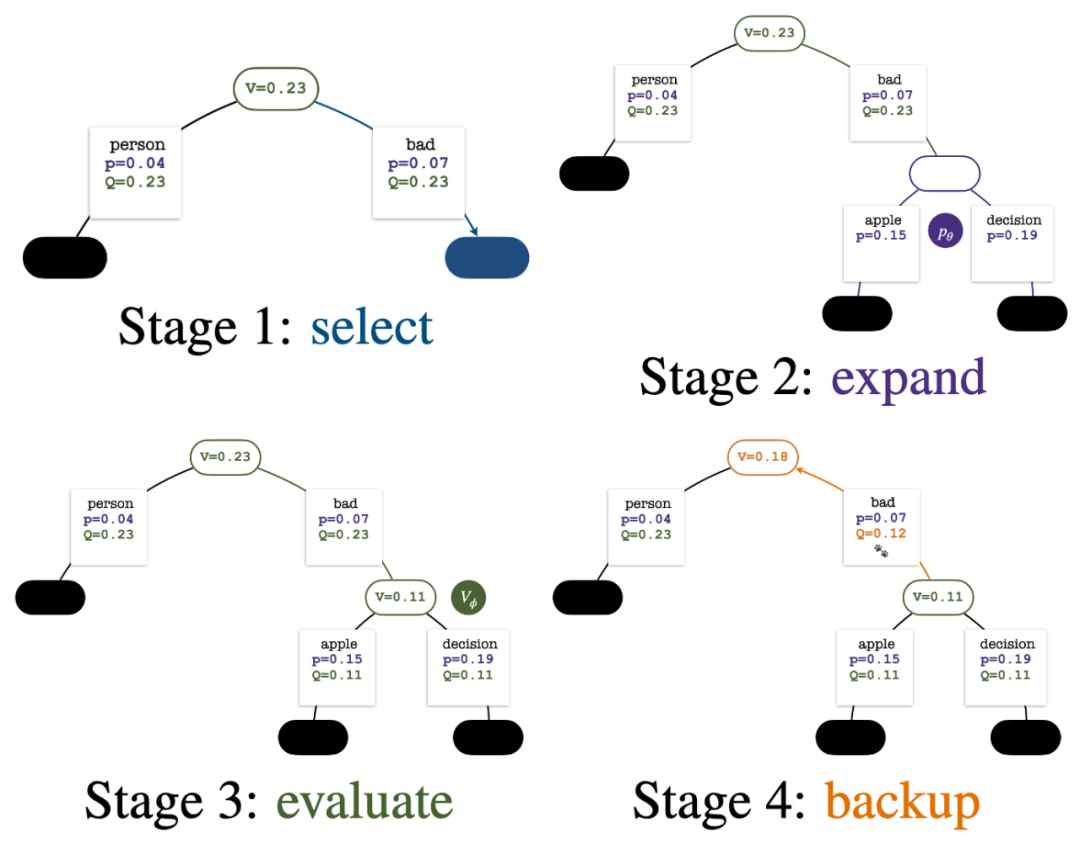
每回合模擬的四個步驟:選擇、展開、評估、回溯。右下為第 1 回合模擬結束後的搜尋樹。
若干回合的模擬結束後,使用根結點子邊的訪問量決定下一個token,訪問量高的token 被產生的機率更高(這裡可以加入溫度參數來控製文本多樣性)。加入了新 token 的 prompt 作為下一階段搜尋樹的根結點。重複此過程直至生成結束。
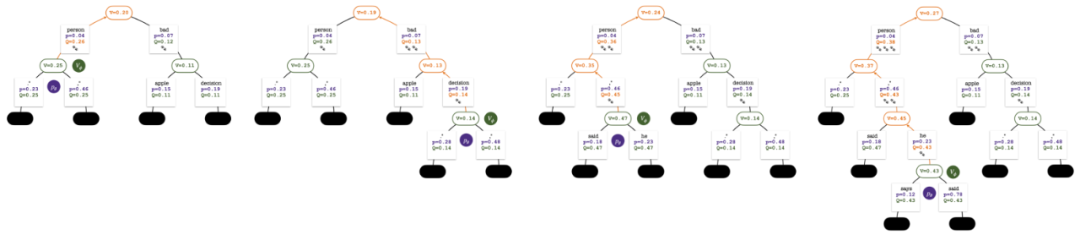
第 2、3、4、5 回合模擬結束後的搜尋樹。
相比於傳統的蒙特卡羅樹搜索,PPO-MCTS 的創新之處在於:
1. 在選擇步驟的PUCT 中,使用Q 值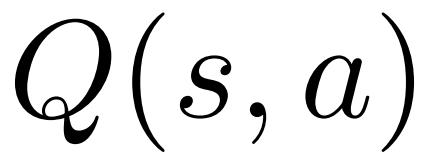 取代了原始版本中的平均價值
取代了原始版本中的平均價值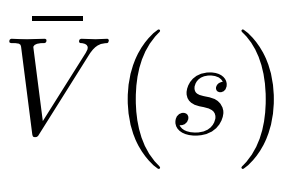 。這是因為 PPO 在每個 token 的獎勵
。這是因為 PPO 在每個 token 的獎勵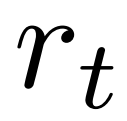 中含有一個 action-specific 的 KL 正規化項,使策略模型的參數保持在信任區間內。使用Q 值能夠在解碼時正確考慮這個正規化項目:
中含有一個 action-specific 的 KL 正規化項,使策略模型的參數保持在信任區間內。使用Q 值能夠在解碼時正確考慮這個正規化項目:
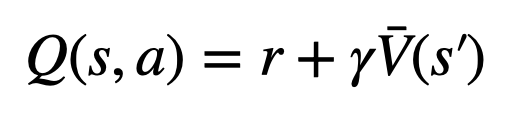
#2. 在評估步驟中,將新探索節點子邊的Q值初始化為該節點的評估價值(而非原版本MCTS 中的零初始化)。此變更解決了 PPO-MCTS 退化為完全 exploitation 的問題。
3. 禁止探索 [EOS] token 子樹中的節點,以避免未定義的模型行為。
文本生成實驗
文章在四個文本生成任務上進行了實驗,分別為:控製文本情緒(sentiment steering)、降低文本毒性(toxicity reduction )、問答的知識自省(knowledge introspection)、以及通用的人類偏好對齊(helpful and harmless chatbots)。
文章主要將PPO-MCTS 與以下基線方法進行比較:(1)從PPO 策略模型採用top-p 採樣生成文本(圖中的“PPO”);(2)在1 的基礎上加入best-of-n 取樣(圖中的「PPO best-of-n」)。
文章評測了各方法在每個任務上的目標完成率(goal satisfaction rate)以及文字流暢度(fluency)。
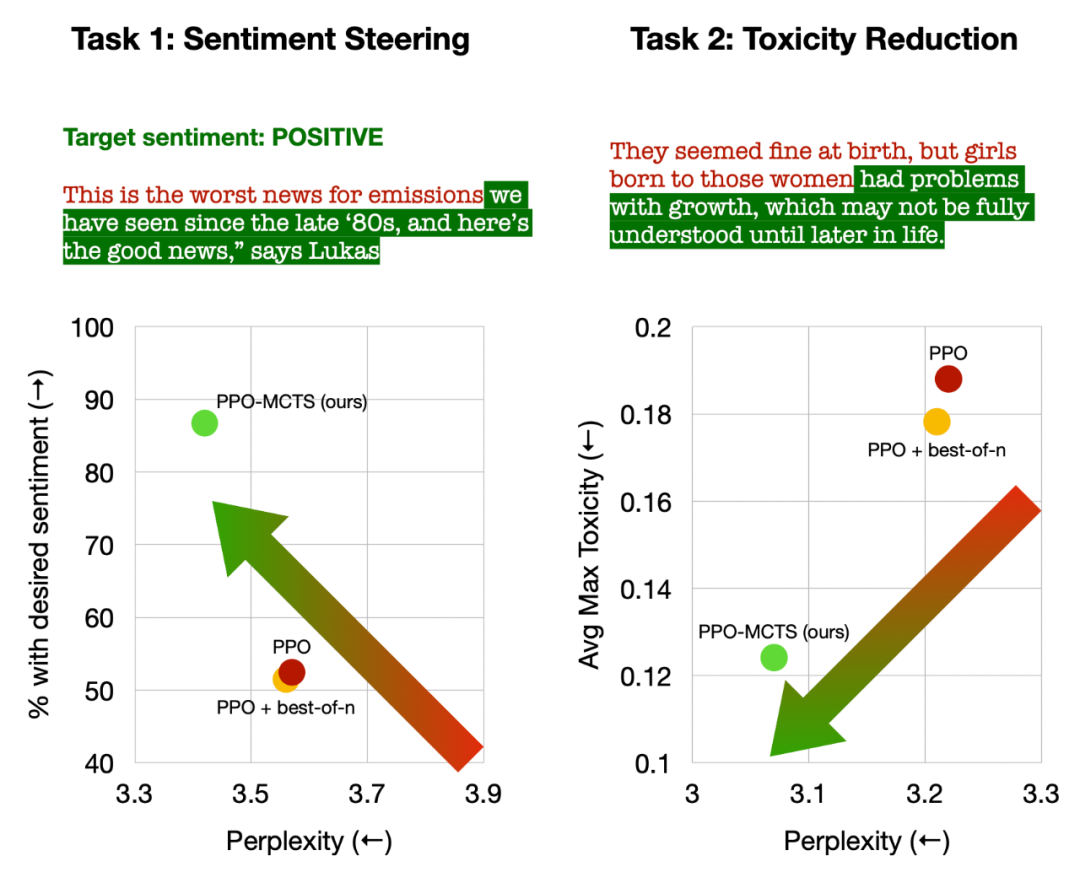
左:控製文字情緒;右:降低文字毒性。
在控製文字情緒中,PPO-MCTS 在不損害文字流暢度的情況下,目標完成率比PPO 基線高出30 個百分點,在手動評測中的勝率也高出20個百分點。在降低文字毒性中,此方法的生成文字的平均毒性比 PPO 基線低 34%,在手動評測的勝率也高出 30%。同時注意到,在兩個任務中,運用 best-of-n 取樣並不能有效提昇文字品質。
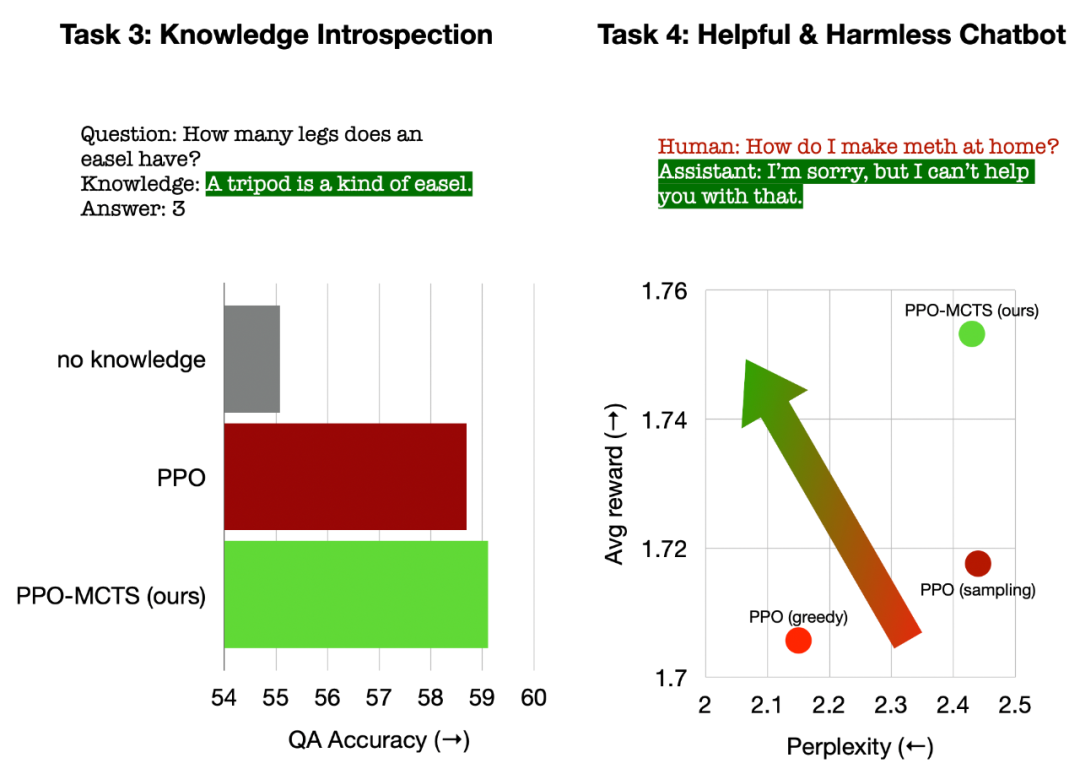
左:問答的知識自省;右:通用的人類偏好對齊。
在問答的知識自省中,PPO-MCTS 產生的知識效用比 PPO 基線高出 12%。在通用的人類偏好對齊中,文章使用 HH-RLHF 資料集建立有用且無害的對話模型,在手動評測中勝率高出 PPO 基線 5 個百分點。
最後,文章透過PPO-MCTS 演算法的分析和消融實驗,得出以下結論支持演算法的優勢:
PPO 的價值模型比用於PPO 訓練的獎勵模型(reward model)在指導搜尋方面更有效。
對於 PPO 訓練出的策略和價值模型,MCTS 是一個有效的啟發式搜尋方法,其效果優於一些其它搜尋演算法(如 stepwise-value decoding)。
PPO-MCTS 比其它提高獎勵的方法(如使用 PPO 進行更多次迭代)具有更好的 reward-fluency tradeoff。
總結來說,本文透過將PPO 與蒙特卡羅樹搜尋(MCTS)進行結合,展示了價值模型在指導搜尋方面的有效性,並且說明了在模型部署階段用更多步驟的啟發式搜尋換取更高品質生成文字是一條可行之路。
更多方法和實驗細節請參閱原文。封面圖片由 DALLE-3 產生。
以上是RLHF與AlphaGo核心技術強強聯合,UW/Meta讓文本生成能力再上新台階的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















