

大模型「識圖」能力都這麼強了,為啥還老找錯東西?
例如,把長得不太像的蝙蝠和拍子搞混,又或是認不出一些資料集中的稀有魚類…
這是因為,我們讓大模型「找東西」時,常輸入的是文字。
如果描述有歧義或太偏門,像是「bat」(蝙蝠還是拍子?)或「魔鱂」(Cyprinodon diabolis),AI就會大為困惑。
這就導致用大模型做目標偵測、尤其是開放世界(未知場景)目標偵測任務時,效果往往沒有想像中那麼好。
現在,一篇被NeurIPS 2023收錄的論文,終於解決了這個問題。

論文提出了一個基於多模態查詢的目標偵測方法MQ-Det,只需要給輸入加上一個圖片範例,就能讓大模型找東西的準確率大幅提升。
在基準偵測資料集LVIS上,無需下游任務模型微調,MQ-Det平均提升主流偵測大模型GLIP精確度約#7.8%#,在13個基準小樣本下游任務上,平均提高了6.3%精度。
這究竟是怎麼做到的?一起來看看。
以下內容轉載自論文作者、知乎部落客@沁園夏:
論文名稱:Multi-modal Queried Object Detection in the Wild
論文連結://m.sbmmt.com/link/9c6947bd95ae487c81d4e19d3ed8cd6f

########################################################################################################### #//m.sbmmt.com/link/2307ac1cfee5db3a5402aac9db25cc5d##################1.1 從文字查詢到多模態查詢###############1.1 從文字查詢到多模態查詢#########一圖勝過千言###:隨著圖文預訓練的興起,藉助文本的開放語義,目標偵測逐漸步入了開放世界感知的階段。為此,許多檢測大模型都遵循了文字查詢的模式,即利用類別文字描述在目標圖像中查詢潛在目標。然而,這種方式往往會面臨「廣而不精」的問題。 ######例如,(1)圖1中的細粒度物體###(魚種)###檢測,往往很難用有限的文字來描述各種細粒度的魚種,(2)類別歧義###(「bat」既可指蝙蝠又可指拍子)###。 ######然而,以上的問題均可透過圖像範例來解決,相較於文本,圖像能夠提供目標物體###更豐富的特徵線索###,但同時文本又具備###強大的泛化性###。 ######由此,如何能夠有機地結合兩種查詢方式,成為了一個很自然的想法。 #########取得多模態查詢能力的困難點###:如何得到這樣一個具備多模態查詢的模型,有三個挑戰:(1)直接用有限的圖像範例進行微調很容易造成災難性遺忘;(2)從頭訓練一個檢測大模型會具備較好的泛化性但是消耗巨大,例如,單卡訓練GLIP 需要利用3000萬數據量訓練480 天。 #########多模態查詢目標偵測:###基於上述考慮,作者提出了一個簡單有效的模型設計和訓練策略-MQ-Det。 ######MQ-Det在已有凍結的文字查詢偵測大模型基礎上插入少量門控感知模組###(GCP)###來接收視覺範例的輸入,同時設計了視覺條件掩碼語言預測訓練策略有效率地得到高效能多模態查詢的偵測器。 ###
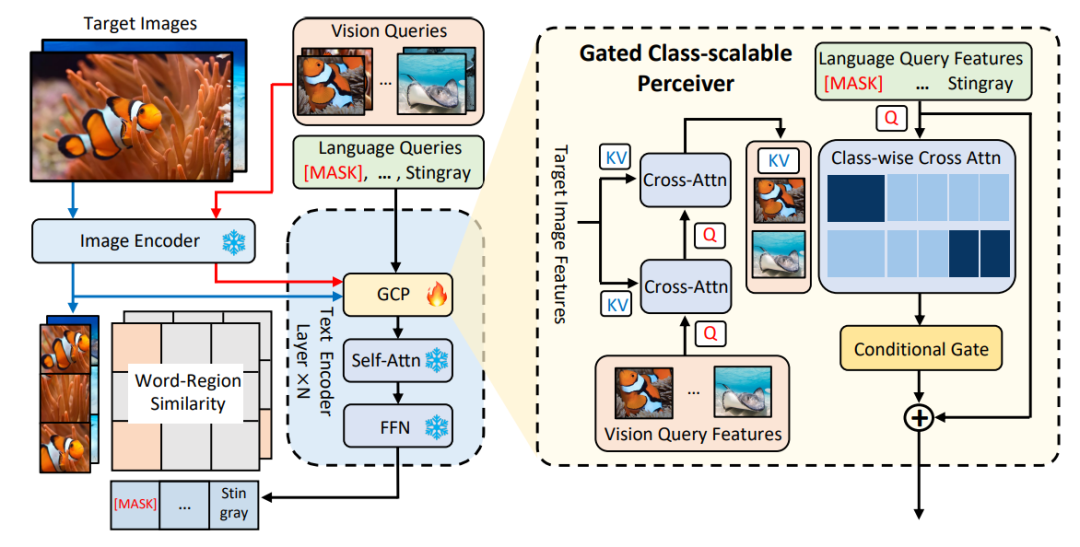
#△圖1 MQ-Det方法架構圖
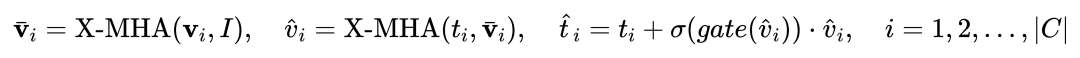
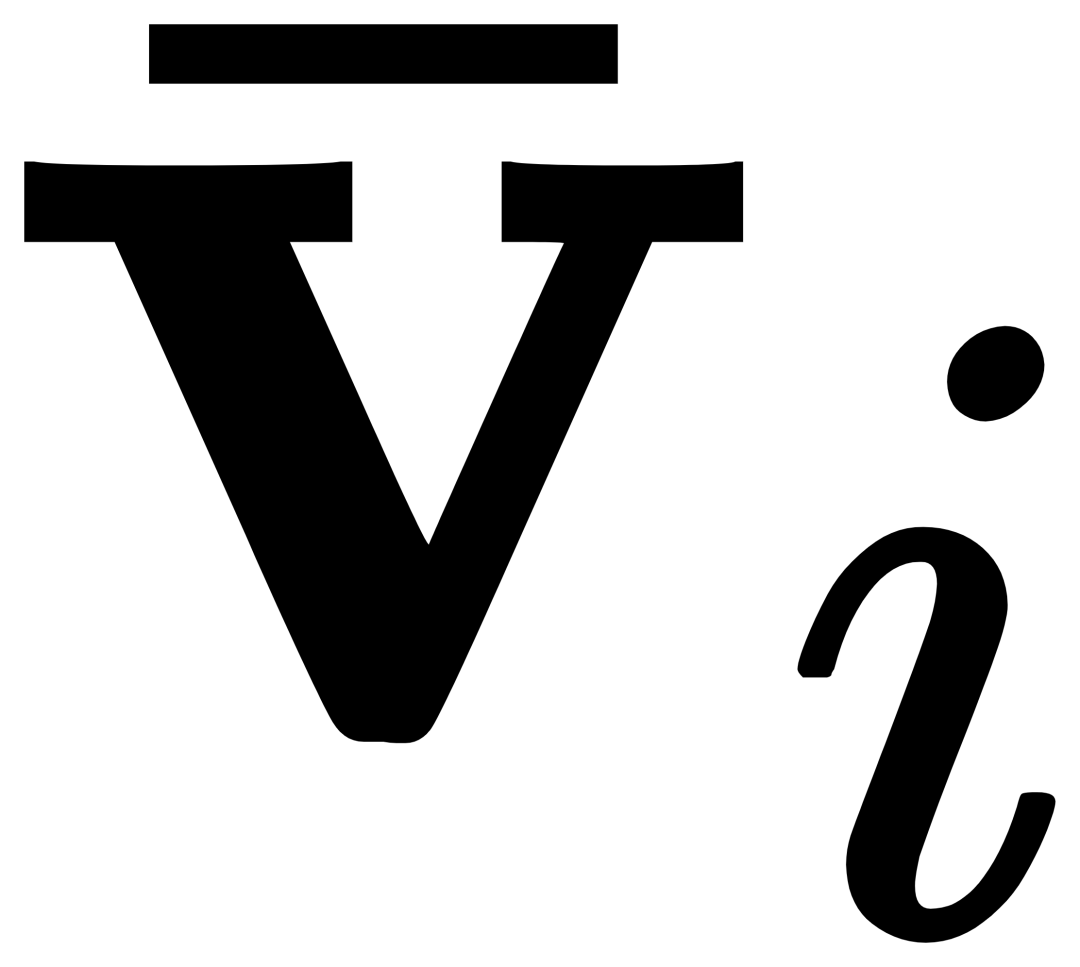
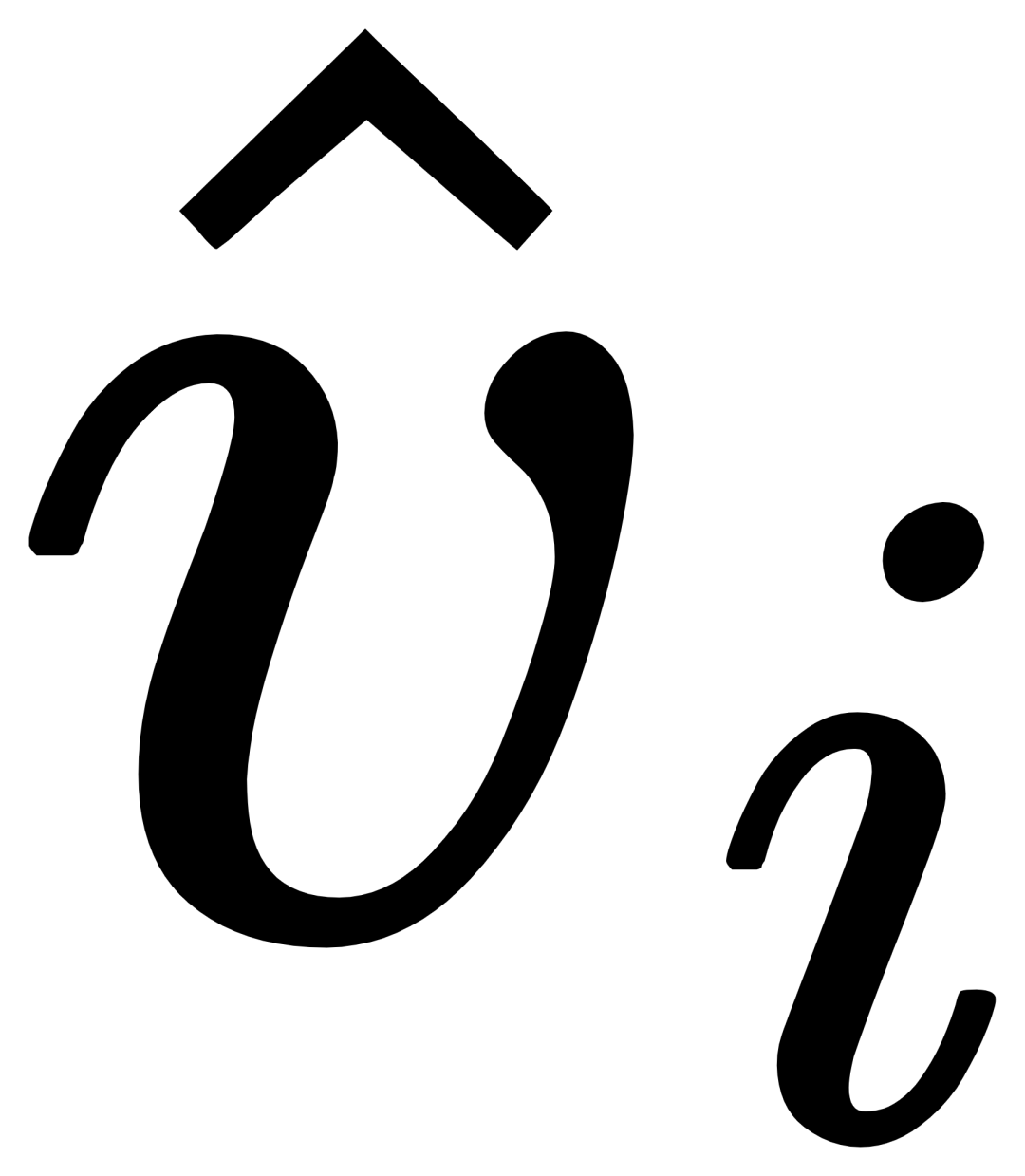
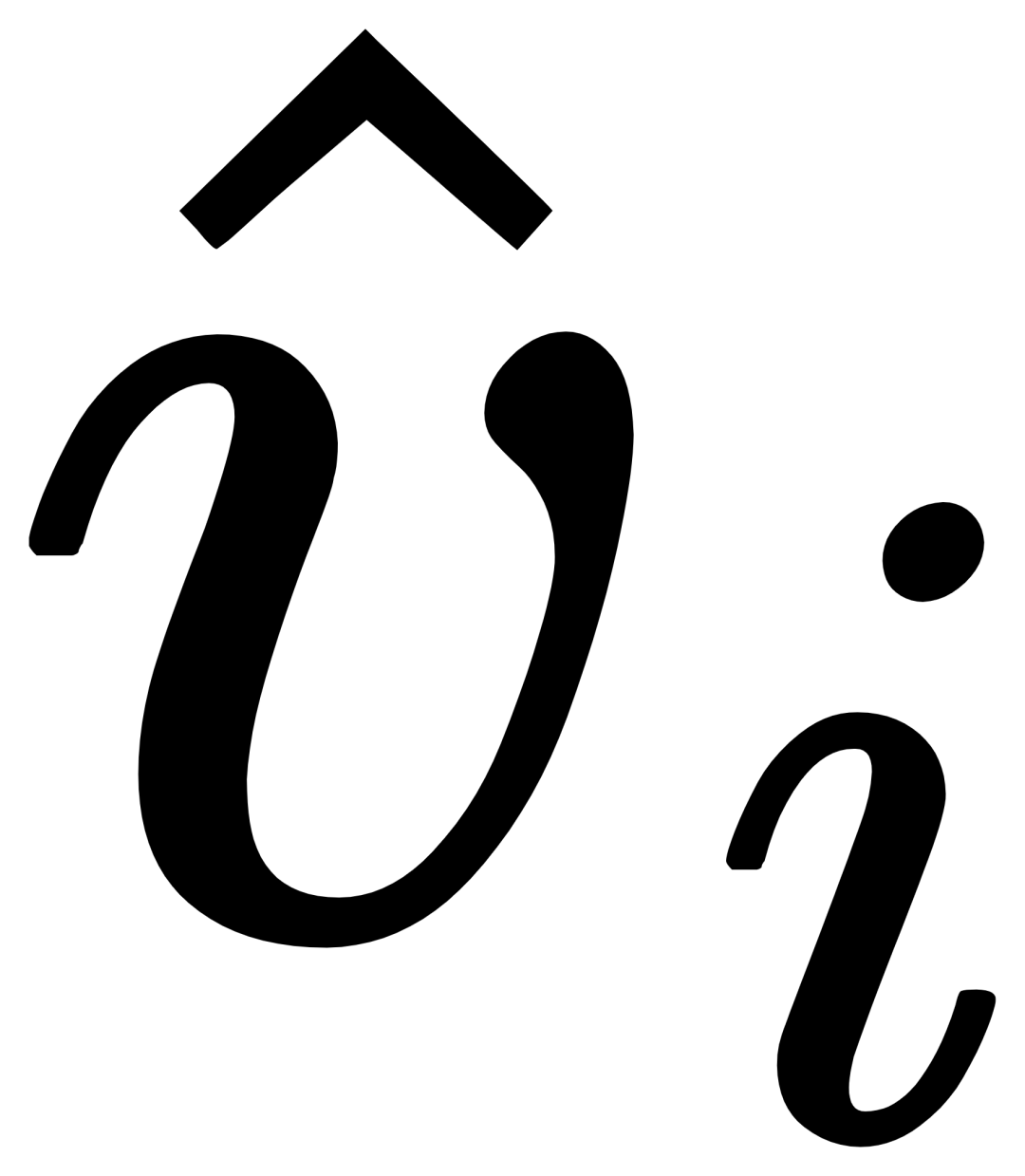
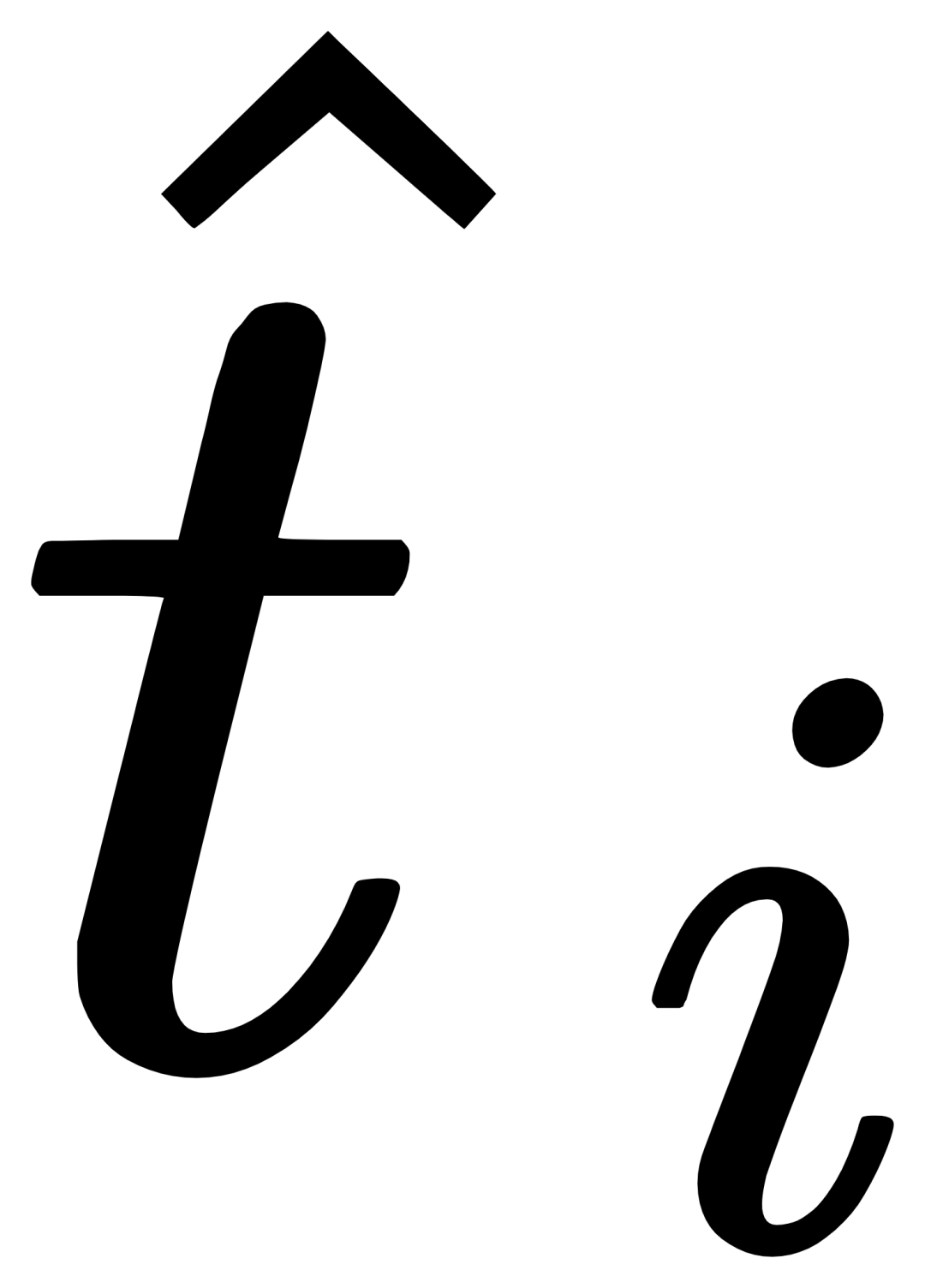
門控感知模組
如圖1所示,作者在已有凍結的文本查詢檢測大模型的文本編碼器端逐層插入了門控感知模組
(GCP),GCP的工作模式可以用下面公式簡潔地表示:
#對於第i個類別,輸入視覺範例Vi,其首先和目標影像I進行交叉注意力(X-MHA)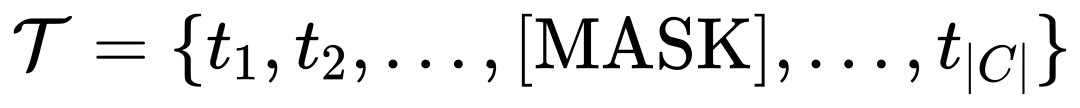 得到
得到
進行交叉注意力得到
,之後透過一個閘控模組gate將原始文字ti和視覺增廣後文字1.3 MQ-Det高效訓練策略基於凍結語言查詢偵測器的調變訓練
由於目前文字查詢的預訓練偵測大模型本身就具備較好的泛化性,論文作者認為,只需要在原先文本特徵基礎上用視覺細節進行輕微地調整即可。 在文章中也有具體的實驗論證發現,打開原始預訓練模型參數後進行微調很容易帶來災難性遺忘的問題,反而失去了開放世界檢測的能力。 ######由此,MQ-Det在凍結文字查詢的預訓練偵測器基礎上,僅調製訓練插入的GCP模組,就可以有效率地將視覺資訊插入現有文字查詢的偵測器中。 ######在論文中,作者分別將MQ-Det的結構設計和訓練技術應用於目前的SOTA模型GLIP和GroundingDINO ,來驗證方法的通用性。 #########以視覺為條件的遮罩語言預測訓練策略#########作者也提出了一種視覺為條件的遮罩語言預測訓練策略,來解決凍結預訓練模型帶來的學習惰性的問題。 ######所謂學習惰性,即指偵測器在訓練過程中傾向於維持原始文字查詢的特徵,從而忽略新加入的視覺查詢特徵。 ######為此,MQ-Det在訓練時隨機地用[MASK] token來取代文字token,迫使模型向視覺查詢特徵側學習,即:############ ###這個策略雖然簡單,但是卻十分有效,從實驗結果來看這個策略帶來了顯著的效能提升。 ######1.4 實驗結果:Finetuning-free評估#########Finetuning-free###:比較傳統零樣本###(zero-shot)###評估僅利用類別文本進行測試,MQ-Det提出了更貼近實際的評估策略:###finetuning-free###。其定義為:在不進行任何下游微調的條件下,使用者可以利用類別文字、影像範例、或兩者結合來進行目標偵測。 ######在finetuning-free的設定下,MQ-Det對每個類別選用了5個視覺範例,同時結合類別文字進行目標偵測,而現有的其他模型不支援視覺查詢,只能用純文字描述進行目標偵測。下表展示了在LVIS MiniVal和LVIS v1.0上的檢測結果。可以發現,多模態查詢的引入大幅提升了開放世界目標偵測能力。 ###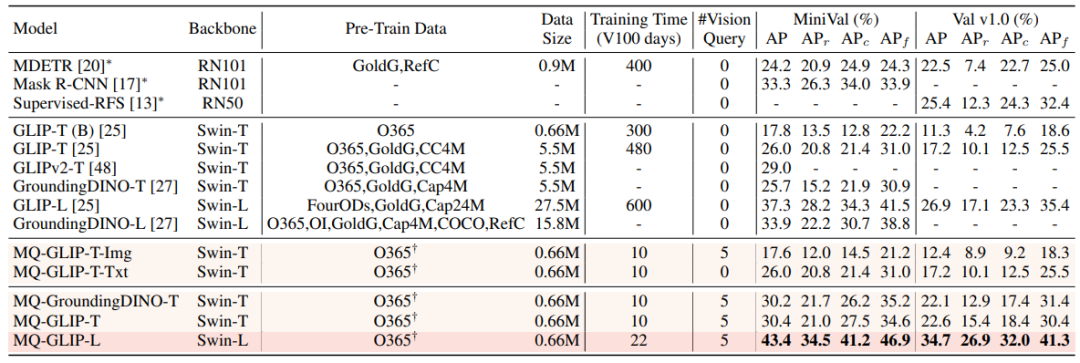
△表1 各个检测模型在LVIS基准数据集下的finetuning-free表现
从表1可以看到,MQ-GLIP-L在GLIP-L基础上提升了超过7%AP,效果十分显著!
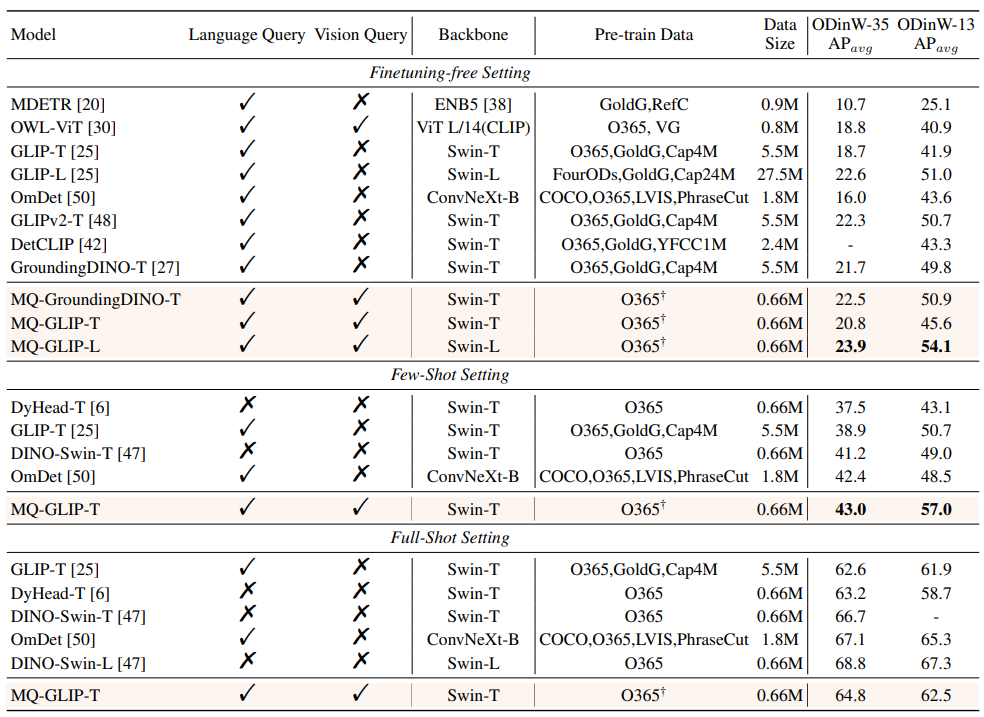
△表2 各个模型在35个检测任务ODinW-35以及其13个子集ODinW-13中的表现
作者还进一步在下游35个检测任务ODinW-35中进行了全面的实验。由表2可以看到,MQ-Det除了强大的finetuning-free表现,还具备良好的小样本检测能力,进一步印证了多模态查询的潜力。图2也展示了MQ-Det对于GLIP的显著提升。
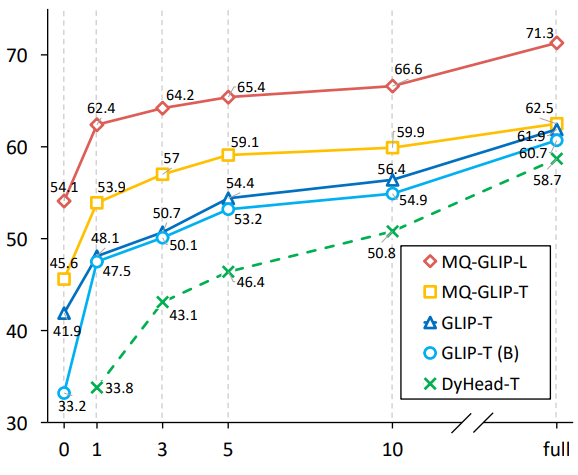
△图2 数据利用效率对比;横轴:训练样本数量,纵轴:OdinW-13上的平均AP
目标检测作为一个以实际应用为基础的研究领域,非常注重算法的落地。
尽管以往的纯文本查询目标检测模型展现出了良好的泛化性,但是在实际的开放世界检测中文本很难涵盖细粒度的信息,而图像中丰富的信息粒度完美地补全了这一环。
至此我们能够发现,文本泛而不精,图像精而不泛,如果能够有效地结合两者,即多模态查询,将会推动开放世界目标检测进一步向前迈进。
MQ-Det在多模态查询上迈出了第一步尝试,其显著的性能提升也昭示着多模态查询目标检测的巨大潜力。
同时,文本描述和视觉示例的引入为用户提供了更多的选择,使得目标检测更加灵活和用户友好。
以上是讓大模型看圖比打字管用! NeurIPS 2023新研究提出多模態查詢方法,準確率提升7.8%的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















