

作者:葉小飛
連結:https://www.zhihu.com/question/269707221/answer/2281374258
我之前在北美賓士落地時,曾有一段時間為了測試不同的結構和參數,一周能訓練一百來個不同的模型,為此我結合公司前輩們的做法和自己的一點思考總結了一套高效的程式碼實驗管理方法,成功幫助了專案落地, 現在在這裡分享給大家。
我知道很多開源repo喜歡用input argparse來傳輸一大堆訓練和模型相關的參數,其實非常不高效。一方面,你每次訓練都需要手動輸入大量參數會很麻煩,如果直接改預設值又要跑到程式碼裡去改,會浪費很多時間。這裡我推薦大家直接使用一個Yaml file來控制所有模型和訓練相關的參數,並將該yaml的命名與模型名字和時間戳聯繫起來,著名的3d點雲檢測庫OpenPCDet就是這麼做的,如下方這個連結所示。
github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
我從上方給的連結截取了該yaml檔案部分內容,如下圖所示,這個設定檔涵蓋如何預處理點雲,classification的種類,還有backbone各方面的參數、optimzer和loss的選擇(圖中未展示,完整請看上方連結)。也就是說,基本上所有能影響你模型的因素,都被涵括在了這個檔案裡,而在程式碼中,你只需要用一個簡單的yaml.load()就能把這些參數全部讀到一個dict。更關鍵的是,這個設定檔可以隨著你的checkpoint一起被存到相同的資料夾,方便你直接拿來做斷點訓練、finetune或直接做測試,用來做測試時你也可以很方便把結果和對應的參數對上。

有些研究人員寫程式碼時喜歡把整個系統寫的過於耦合,例如把loss function和模型寫在一起,這會常常導致牽一發而動全身,你改動某一小塊就會導致後面的介面也全變,所以程式碼模組化做的好,可以節省你許多時間。一般的深度學習程式碼基本上可以分為這麼幾大塊(以pytorch為例):I/O模組、預處理模組、視覺化模組、模型主體(如果一個大模型包含子模型則應該另起class)、損失函數、後處理,並在訓練或測試腳本裡串聯起來。程式碼模組化的另一個好處,就是方便你在yaml裡去定義不同方面的參數,方便閱覽。另外很多成熟程式碼裡都會用到importlib神庫,它可以允許你不把訓練時用哪個模型或哪個子模型在程式碼裡定死,而是可以直接在yaml裡定義。
這兩個函式庫我基本上每次必用。 Tensorboard可以很好的追蹤你訓練的loss曲線變化,方便你判斷模型是否還在收斂、是否overfit,如果你是做圖像相關,還可以把一些視覺化結果放在上面。很多時候你只需要看看tensorboard的收斂狀態就基本知道你這個模型怎麼樣,有沒有必要花時間再單獨測試、finetune. Tqdm則可以幫你很直觀地跟踪你的訓練進度,方便你做early stop .
無論你是多人合作開發還是單獨項目,我都強烈建議使用Github(公司可能會使用bitbucket, 差不多)記錄你的程式碼。具體可以參考我這篇回答:
身為研究生,有哪些你直呼好用的科研神器?
https://www.zhihu.com/question/484596211/answer/2163122684
我通常會保存一個總的excel來記錄實驗結果,第一列是模型對應的yaml的路徑,第二列是模型訓練epoches, 第三列是測試結果的log, 我一般會把這個過程自動化,只要在測試腳本中給定總excel路徑,利用pandas可以很輕鬆地搞定。
作者:Jason
連結:https://www.zhihu.com/question/269707221/answer/470576066
git管理程式碼是跟深度學習、科學研究都沒關係的,寫程式碼一定要用版本管理工具。用不用github個人覺著倒是兩可,畢竟公司內是不可能所有程式碼都掛外部git的。
那麼說幾個寫程式碼的時候需要注意的地方吧:
一方面外部傳入參數可以避免git上過多的版本修改是由於參數導致的,介於DL不好debug,有時候利用git做一下程式碼比對是在所難免的;
另一方面當試驗了萬千版本之後,相信你不會知道哪個model是哪些參數了,好的習慣是非常有效的。另外新加的參數盡量提供default值,方便呼叫老版的config檔。
同一個項目裡,好的複用性是編程的一種非常好的習慣,但是在飛速發展的DL coding中,假設項目是以任務驅動的,這也許有時候會成為牽絆,所以盡量把可重複使用的一些函數提取出來,模型結構相關的盡量讓不同的模型解耦在不同的文件中,反而會更方便日後的update。否則一些看似優美的設計幾個月後就變得很雞肋。
往往有個尷尬的情況,從一個項目開始到結束,框架update了好幾個版本,新版有一些讓人垂涎若滴的特性,但無助有些api發生了change。所以在專案內可以盡量保持框架版本穩定,專案開始前盡量考慮不同版本的利弊,有時候適當的學習是必要的。
另外,對不同的框架懷抱著一顆包容的心。
作者:OpenMMLab
連結:https://www.zhihu.com/question/269707221/answer/2480772257
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者授權,非商業轉載請註明出處。
題主你好呀,前面的回答提到了使用 Tensorboard、Weights&Biases、MLFlow、Neptune 等工具來管理實驗數據。然而隨著實驗管理工具的輪子越造越多,工具的學習成本也越來越高,我們又該如何選擇呢?
MMCV 滿足你的所有幻想,透過修改設定檔就能實現工具的切換。
github.com/open-mmlab/mmcv
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
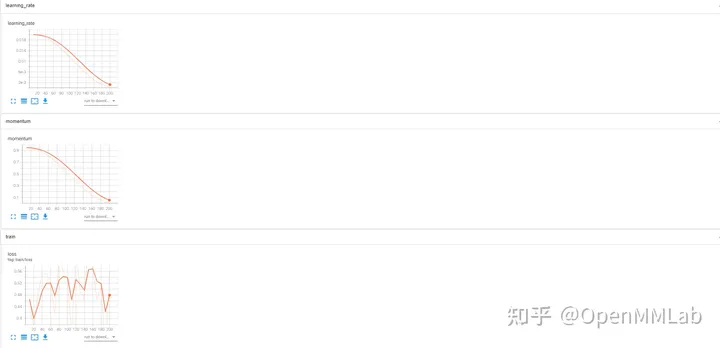
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
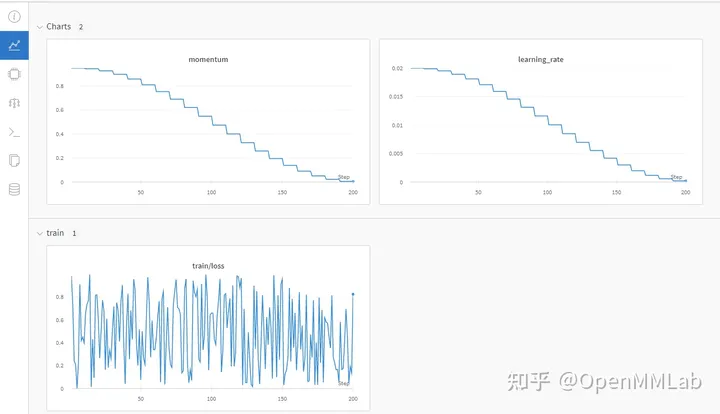
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
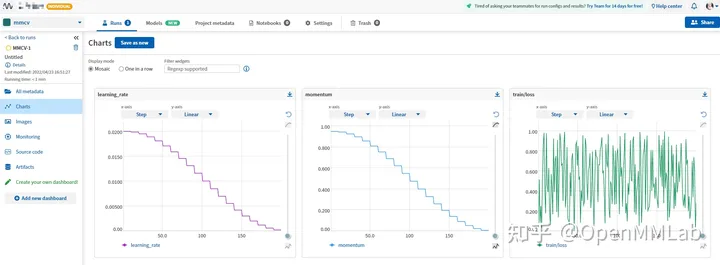
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
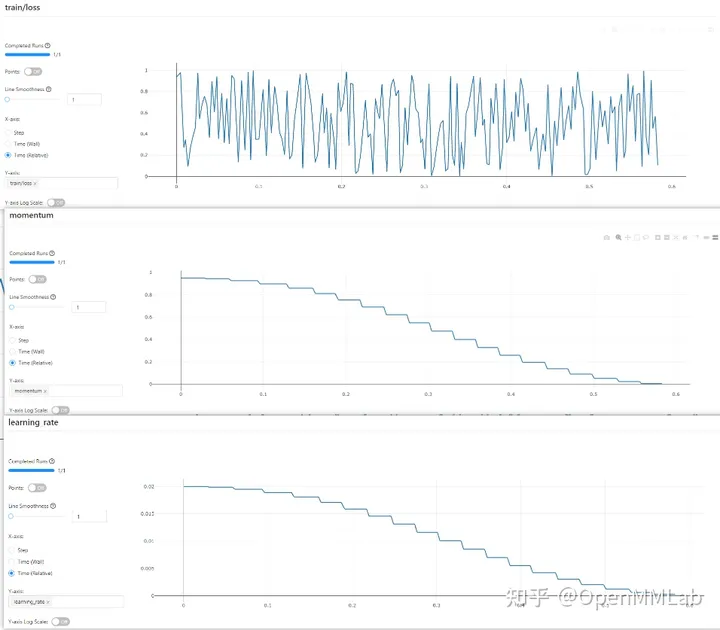
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
#TextLoggerHook !它會將訓練過程中產生的全量訊息,例如設備環境、資料集、模型初始化方式、訓練期間產生的 loss、metric 等信息,全部保存到本地的 xxx.log 檔案。你可以在不借助任何工具的情況下,回顧先前的實驗數據。
還在糾結使用哪個實驗管理工具?還在苦惱於各種工具的學習成本?趕快上車 MMCV ,幾行設定檔無痛體驗各種工具。 github.com/open-mmlab/mmcv以上是深度學習科研,如何有效率地進行程式碼和實驗管理?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















