

在學習方面,GPT-4 是個厲害的學生。在消化了大量人類數據後,它掌握了各門知識,甚至在聊天中能為數學家陶哲軒帶來啟發。
同時,它也成為了優秀的老師,而且不光是教書本知識,還能教機器人轉筆。

這個機器人名叫 Eureka,是來自英偉達、賓州大學、加州理工學院和德州大學奧斯汀分校的研究。這項研究結合了大型語言模型和強化學習的研究成果:以 GPT-4 來完善獎勵函數,以強化學習來訓練機器人控制器。
借助 GPT-4 寫入程式碼的能力,Eureka 擁有了出色的獎勵函數設計能力,它自主產生的獎勵在 83% 的任務中優於人類專家的獎勵。這種能力可以讓機器人完成許多之前不容易完成的任務,例如轉筆、打開抽屜和櫃子、拋球接球和盤球、操作剪刀等。不過,這一切暫時都是在虛擬環境中完成的。



#此外,Eureka 也實作了一種新型的in -context RLHF,它能夠將人類操作員的自然語言回饋納入其中,以引導和對齊獎勵函數。它可以為機器人工程師提供強大的輔助功能,幫助工程師設計複雜的運動行為。英偉達高級 AI 科學家 Jim Fan 也是該論文的作者之一,他將這項研究比喻為「物理模擬器 API 空間中的旅行者號(美國開發並建造的外層星系空間探測器)」。

值得一提的是,這項研究是完全開源的,開源位址如下:

#大型語言模型(LLM)在機器人任務的高階語義規劃方面表現出色(例如Google的SayCan、RT-2 機器人),但它們是否可以用於學習複雜的低階操作任務,如轉筆,仍然是一個懸而未決的問題。現有的嘗試需要大量的領域專業知識來建立任務提示或只學習簡單的技能,遠遠達不到人類層面的靈活性。

Google的 RT-2 機器人。
另一方面,強化學習(RL)在靈活性以及其他許多方面都取得了令人印象深刻的成果(例如OpenAI 會玩魔術方塊的機械手),但需要人類設計師仔細建構獎勵函數,準確地編纂並提供所需行為的學習訊號。由於許多現實世界的強化學習任務只提供難以用於學習的稀疏獎勵,因此在實踐中需要獎勵塑造(reward shaping),以提供漸進的學習訊號。儘管獎勵函數非常重要,但眾所周知,它很難設計。最近的一項調查發現,92% 的強化學習受訪研究人員和從業者表示,他們在設計獎勵時進行了人工試錯,89% 的人表示他們設計的獎勵是次優的,會導致非預期行為。
鑑於獎勵設計如此重要,我們不禁要問,是否有可能利用最先進的編碼 LLM(如 GPT-4)來開發一種通用的獎勵程式演算法?這些 LLM 在程式碼編寫、零樣本產生以及 in-context learning 等方面表現出色,曾經大幅提升了程式設計智能體的效能。理想情況下,這種獎勵設計演算法應具有人類水平的獎勵生成能力,可擴展到廣泛的任務範圍,在沒有人類監督的情況下自動完成乏味的試錯過程,同時與人類監督兼容,以確保安全性和一致性。
這篇論文提出了一個由 LLM 驅動的獎勵設計演算法 EUREKA(全名為 Evolution-driven Universal REward Kit for Agent)。演算法達成了以下成就:
1、在29 種不同的開源RL 環境中,獎勵設計的性能達到了人類水平,這些環境包括10 種不同的機器人形態(四足機器人、四旋翼機器人、雙足機器人、機械手以及幾種靈巧手,見圖1。在沒有任何特定任務提示或獎勵模板的情況下,EUREKA 自主生成的獎勵在83% 的任務中優於人類專家的獎勵,並實現了52% 的平均歸一化改進。

#2、解決了以前無法透過人工獎勵工程實現的靈巧操作任務。以轉筆問題為例,在這種情況下,一隻有五根手指的手需要按照預先設定的旋轉配置快速旋轉鋼筆,並儘可能多地旋轉幾個週期。透過將EUREKA 與課程學習結合,研究者首次在模擬擬人「Shadow Hand」上示範了快速轉筆的操作(見圖1 底部)。
3、為基於人類回饋的強化學習(RLHF)提供了一種新的無梯度上下文學習方法,可以基於各種形式的人類輸入生成更高效、與人類對齊程度更高的獎勵函數。論文表明,EUREKA 可以從現有的人類獎勵函數中獲益並加以改進。同樣,研究者還展示了EUREKA 利用人類文本反饋來輔助設計獎勵函數的能力,這有助於捕捉到人類的細微偏好。
與先前使用LLM 輔助獎勵設計的L2R 工作不同,EUREKA 完全沒有特定任務提示、獎勵模板以及少量示例。在實驗中,EUREKA 的表現明顯優於L2R,這得益於它能夠生成和完善自由形式、表達能力強的獎勵程序。
EUREKA 的通用性得益於三個關鍵的演算法設計選擇:將環境作為上下文、進化搜尋和獎勵反思(reward reflection)。
首先,透過將環境原始碼作為上下文,EUREKA 可以從主幹編碼LLM(GPT-4)中零樣本產生可執行的獎勵函數。然後,EUREKA 透過執行進化搜索,迭代地提出獎勵候選批次,並在LLM 上下文視窗中精煉最有希望的獎勵,從而大大提高了獎勵的品質。這種in-context 的改進透過獎勵反思來實現,獎勵反思是基於策略訓練統計數據的獎勵品質文本總結,可實現自動和有針對性的獎勵編輯。
圖3 為EUREKA 零樣本獎勵示例,以及優化過程中積累的各項改進。為了確保EUREKA 能夠將其獎勵搜尋擴展到最大潛力,EUREKA 在IsaacGym 上使用GPU 加速的分散式強化學習來評估中間獎勵,這在策略學習速度上提供了高達三個數量級的提升,使EUREKA 成為一個廣泛的演算法,隨著計算量的增加而自然擴展。

如圖 2 所示。研究者致力於開源所有提示、環境和生成的獎勵函數,以促進基於 LLM 的獎勵設計的進一步研究。

EUREKA 可以自主的寫獎勵演算法,具體是如何實現的,我們接著往下看。
EUREKA 由三個演算法組件組成:1)將環境作為上下文,從而支持零樣本生成可執行獎勵;2)進化搜索,迭代地提出和完善獎勵候選;3 )獎勵反思,支持細粒度的獎勵改進。
環境作為上下文
本文建議直接提供原始環境程式碼作為上下文。僅透過最少的指令,EUREKA 就可以在不同的環境中零樣本地產生獎勵。 EUREKA 產出範例如圖 3 所示。 EUREKA 在提供的環境代碼中熟練地組合了現有的觀察變數 (例如,指尖位置),並產生了一個有效的獎勵代碼 —— 所有這些都沒有任何特定於環境的提示工程或獎勵模板。
然而,在第一次嘗試時,產生的獎勵可能並不總是可執行的,即使它是可執行的,也可能是次優的。這就出現了一個疑問,如何有效克服單樣本獎勵產生的次優性?

演化搜尋
#接著,論文介紹了演化搜尋是如何解決上述提到的次優解等問題的。他們是這樣完善的,在每次迭代中,EUREKA 對 LLM 的幾個獨立輸出進行採樣(演算法 1 中的第 5 行)。由於每次迭代(generations)都是獨立同分佈的,這樣一來隨著樣本數量的增加,迭代中所有獎勵函數出現錯誤的機率呈指數下降。


#獎勵反思
 #為了提供更複雜、更有針對性的獎勵分析,本文建議建立自動回饋來總結文本中的策略訓練動態。具體來說,考慮到 EUREKA 獎勵函數需要獎勵程序中的各個組件(例如圖 3 中的獎勵組件),因而本文在整個訓練過程中追蹤中間策略檢查點處所有獎勵組件的標量值。
#為了提供更複雜、更有針對性的獎勵分析,本文建議建立自動回饋來總結文本中的策略訓練動態。具體來說,考慮到 EUREKA 獎勵函數需要獎勵程序中的各個組件(例如圖 3 中的獎勵組件),因而本文在整個訓練過程中追蹤中間策略檢查點處所有獎勵組件的標量值。
實驗
 #實驗部分對Eureka 進行了全面的評估,包括產生獎勵函數的能力、解決新任務的能力以及對人類各種輸入的整合能力。
#實驗部分對Eureka 進行了全面的評估,包括產生獎勵函數的能力、解決新任務的能力以及對人類各種輸入的整合能力。
實驗環境包括 10 個不同的機器人以及 29 個任務,其中,這 29 個任務由 IsaacGym 模擬器實現。實驗採用了 IsaacGym (Isaac) 的 9 個原始環境,涵蓋從四足、雙足、四旋翼、機械手到機器人的靈巧手的各種機器人形態。除此之外,本文還透過納入 Dexterity 基準測試中的 20 項任務來確保評估的深度。

Eureka 可以產生超人類層次的獎勵函數。在 29 項任務中,Eureka 給予的獎勵函數在 83% 的任務上比專家編寫的獎勵表現得更好,平均提高了 52%。特別是,Eureka 在高維 Dexterity 基準測試環境中實現了更大的收益。
Eureka 能夠進化獎勵搜索,使獎勵隨著時間的推移而不斷改善。 Eureka 透過結合大規模的獎勵搜尋和詳細的獎勵反思回饋,逐步產生更好的獎勵,最終超過人類的水平。
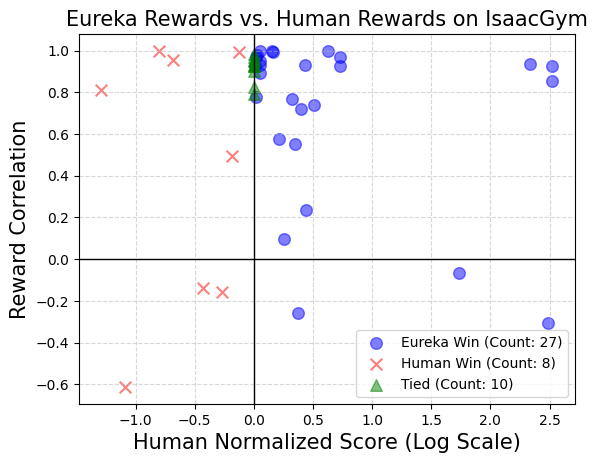
##################Eureka 也能產生新穎的獎勵。本文透過計算所有 Isaac 任務上的 Eureka 獎勵和人類獎勵之間的相關性來評估 Eureka 獎勵的新穎性。如圖所示,Eureka 主要產生弱相關的獎勵函數,其表現優於人類的獎勵函數。此外,本文也觀察到任務越難,Eureka 獎勵的相關性就越小。在某些情況下,Eureka 獎勵甚至與人類獎勵呈負相關,但表現卻明顯優於人類獎勵。 ######
想要實現機器人的靈巧手能夠不停的轉筆,需要操作程式有盡可能多的循環。本文透過以下方式解決此任務:(1) 指導Eureka 產生獎勵函數,用來將筆重新定向到隨機目標配置,然後(2) 使用Eureka 獎勵微調此預訓練策略以達到所需的筆序列- 旋轉配置。如圖所示,Eureka 微調很快就適應了策略,成功地連續旋轉了許多周期。相較之下,預訓練或從頭開始學習的策略都無法完成單一週期的旋轉。
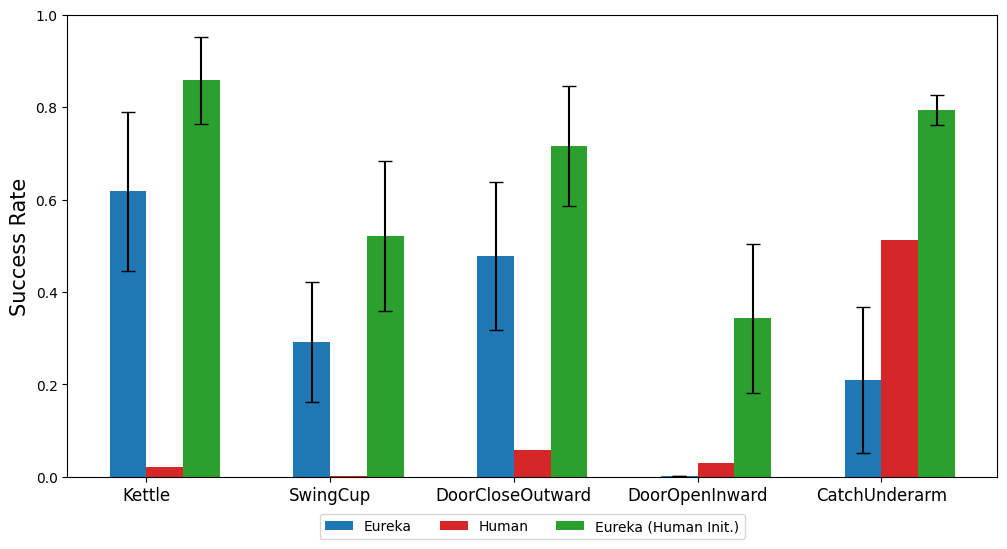
本文也研究了從人類獎勵函數初始化開始是否對 Eureka 有利。如圖所示,無論人類獎勵的品質如何,Eureka 都會從人類獎勵中改進並受益。

Eureka 也實現了RLHF,其可以結合人類的回饋來修改獎勵,從而逐步指導智能體完成更安全、更符合人類的行為。範例展示了 Eureka 如何透過一些人類回饋來教導人形機器人直立奔跑,這些回饋取代了先前的自動獎勵反思。

人形機器人透過 Eureka 學習跑步步態。
了解更多內容,請參考原文。
以上是有了GPT-4之後,機器人把轉筆、盤核桃都學會了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















