

近年來,大語言模型(LLM)及其底層的 transformer 架構已經成為了對話式 AI 的基石,並催生了廣泛的消費級和企業應用程式。儘管有了長足的進步,但 LLM 使用的固定長度的上下文視窗極大地限制了對長對話或長文檔推理的適用性。即使是使用最廣泛的開源 LLM,它們的最大輸入長度只允許支援數十個訊息回覆或短文檔推理。
同時,受限於transformer 架構的自註意力機構,簡單地擴展transformer 的上下文長度也會導致計算時間和內存成本成倍增加,這就使得全新的長上下文架構成為緊迫的研究課題。
不過,即使我們能夠克服上下文縮放的計算挑戰,但最近的研究卻表明,長上下文模型很難有效地利用額外的上下文。
這如何解決呢?考慮到訓練 SOTA LLM 所需的大量資源以及上下文縮放明顯的回報遞減,我們迫切需要支援長上下文的替代技術。加州大學柏克萊分校的研究者在這方面有了新的進展。
在本文中,研究者探討如何在繼續使用固定上下文模型的同時,提供無限上下文的幻覺(illusion)。他們的方法借鑒了虛擬記憶體分頁的思路,使得應用程式能夠處理遠遠超出可用記憶體的資料集。
基於這個思路,研究者利用 LLM 智能體函數呼叫能力的最新進展,設計出了一個受 OS 啟發、用於虛擬情境管理的 LLM 系統 ——MemGPT。

論文首頁:https://memgpt.ai/
arXiv 網址:https://arxiv.org/pdf/2310.08560.pdf
專案已經開源,在GitHub 上已經斬獲了1.7k 的star 量。
GitHub 網址:https://github.com/cpacker/MemGPT
方法概覽
該研究從傳統作業系統的分層記憶體管理中汲取靈感,在上下文視窗(類似於作業系統中的「主記憶體(main memory)」)和外部儲存之間有效地「分頁」進出資訊。 MemGPT 則負責管理記憶體、LLM 處理模組和使用者之間的控制流。這種設計允許在單一任務期間反覆進行上下文修改,從而允許智能體更有效地利用其有限的上下文視窗。
MemGPT 將上下文視窗視為受限記憶體資源,並為 LLM 設計類似於傳統作業系統中分層記憶體(Patterson et al., 1988)的層次結構。為了提供更長的上下文長度,研究允許 LLM 透過「LLM OS」——MemGPT,來管理放置在其上下文視窗中的內容。 MemGPT 使 LLM 能夠檢索上下文中遺失的相關歷史數據,類似於作業系統中的頁面錯誤。此外,智能體可以迭代地修改單一任務上下文視窗中的內容,就像進程可以重複存取虛擬記憶體一樣。
MemGPT 能夠讓 LLM 在上下文視窗有限的情況下處理無界上下文,MemGPT 的元件如下圖 1 所示。
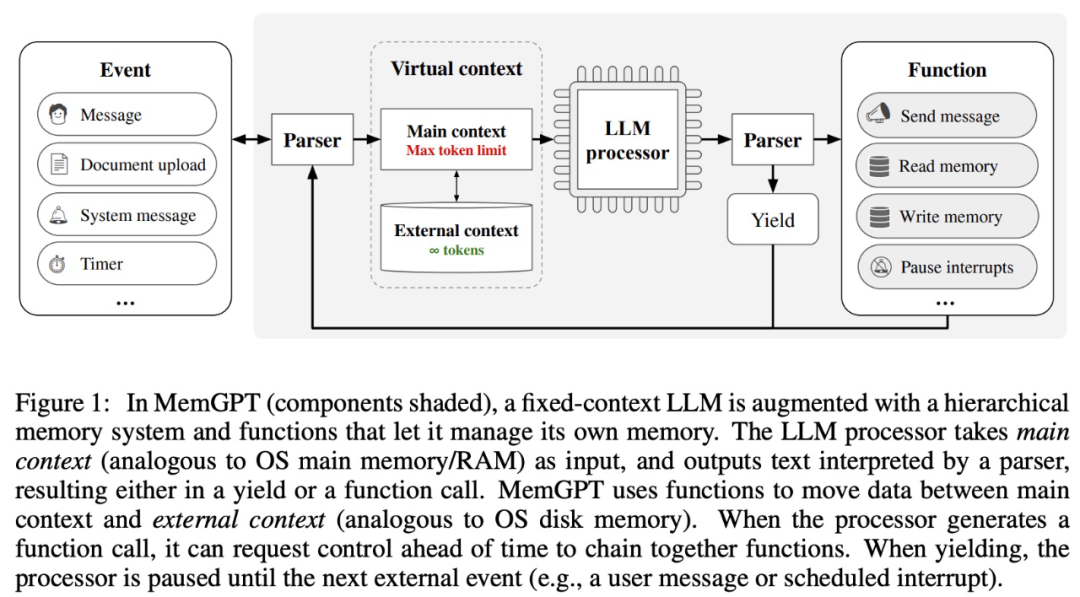
MemGPT 透過函數呼叫協調主上下文(上下文視窗中的內容)和外部上下文之間的資料移動,MemGPT 根據當前上下文自主更新和檢索。


值得注意的是,上下文視窗需要用warning token 來識別其限制,如下圖3 所示:

實驗及結果
#在實驗部分,研究者在兩個長上下文域中來評估 MemGPT,分別是對話式智能體和文件處理。其中對於對話式智能體,他們擴展了現有的多會話聊天資料集(Xu et al. (2021)),並引入了兩個新的對話任務以評估智能體在長對話中保留知識的能力。對於文件分析,他們根據 Liu et al. (2023a) 提出的任務對 MemGPT 進行基準測試,包括對長文件的問答和鍵值檢索。
用於對話智能體的 MemGPT
當與使用者對話時,智能體必須符合以下兩個關鍵標準。
一是一致性,即智能體應保持對話的連貫性,提供的新事實、引用和事件應與使用者、智能體先前的陳述保持一致。
二是參與度,也就是智能體應該利用使用者的長期知識來個人化回應。參考先前的對話可以使對話更加自然和引人入勝。
因此,研究者根據這兩個標準對 MemGPT 進行評估:
MemGPT 是否可以利用其記憶來提高對話一致性?能否記住過去互動中的相關事實、引用、事件以保持連貫性?
MemGPT 是否可以利用記憶產生更具吸引力的對話?是否自發地合併遠端使用者資訊以個性化資訊?
關於使用到的資料集,研究者在 Xu et al. (2021) 提出的多會話聊天(MSC)上對 MemGPT 和固定上下文的基線模型展開評估對比。
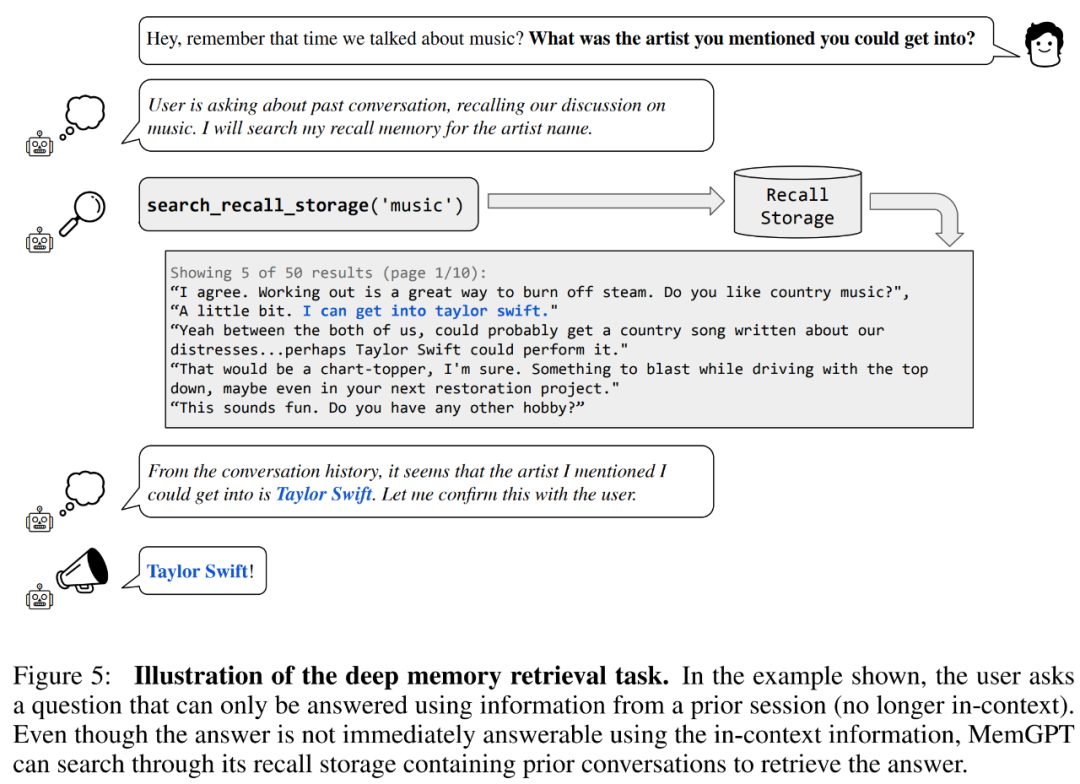
首先來一致性評估。研究者引入了一個基於 MSC 資料集的深層記憶檢索(deep memory retrieval, DMR)任務,旨在測試對話智能體的一致性。在 DMR 中,使用者向對話智能體提出一個問題,而該問題明確引用先前的對話,預期答案範圍會非常窄。具體可以參加下圖 5 範例。
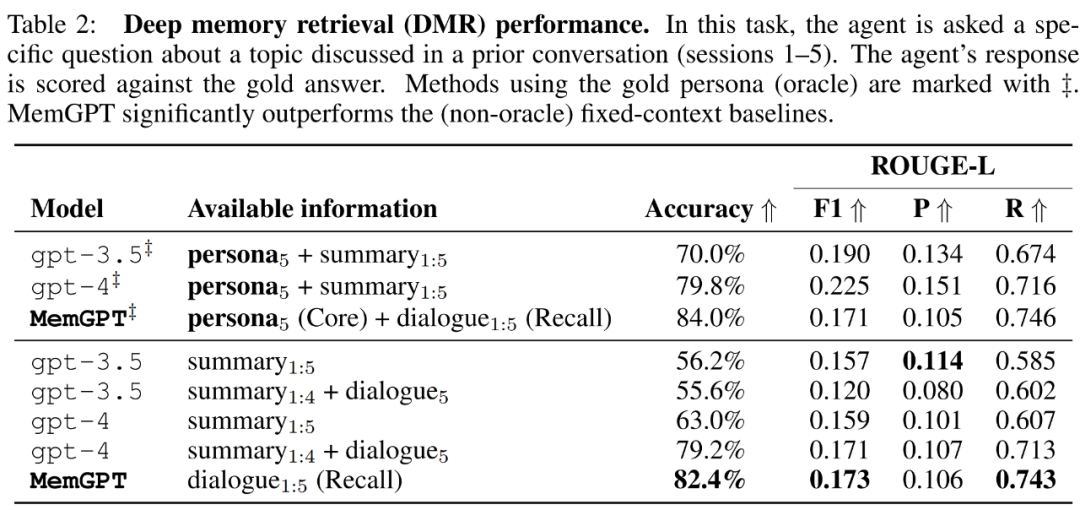
MemGPT 利用記憶體來保持一致性。下表 2 顯示了 MemGPT 與固定記憶基線模型的表現對比,包括 GPT-3.5 和 GPT-4。
可以看到,MemGPT 在 LLM 判斷準確度和 ROUGE-L 分數方面顯著優於 GPT-3.5 和 GPT-4。 MemGPT 能夠利用回想記憶(Recall Memory)查詢過去的對話歷史,進而回答 DMR 問題,而不是依賴遞迴摘要來擴展上下文。
然後在「對話開場白」任務中,研究者評估智能體從先前對話累積的知識中提取引人入勝的訊息並傳遞給使用者的能力。
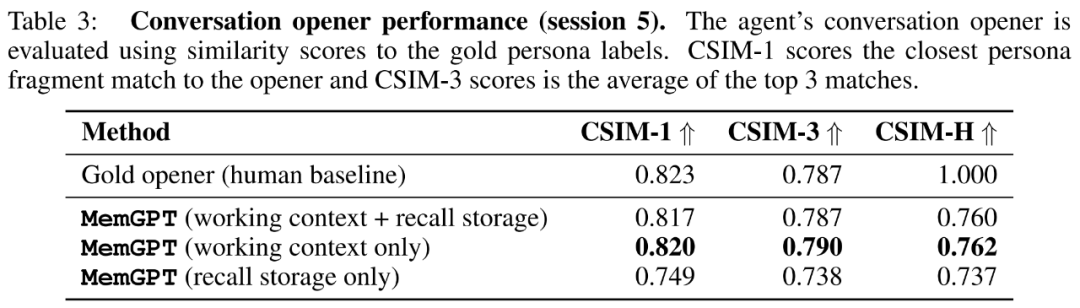
研究者在下表 3 中展示了 MemGPT 開場白的 CSIM 分數。結果表明,MemGPT 能夠製作出引人入勝的開場白,其表現可以媲美甚至超越人類手寫的開場白。此外還觀察到 MemGPT 傾向於製作比人類基線更長且涵蓋更多角色資訊的開場白。下圖 6 為範例。

用於文件分析的MemGPT
為了評估MemGPT 分析文件的能力,研究者對MemGPT 以及在Liu et al. (2023a) 檢索器- 閱讀器文件QA 任務上的固定上下文基準模型進行了基準測試。
結果顯示,MemGPT 能夠透過查詢檔案儲存有效地對檢索器進行多次調用,從而可以擴展到更大的有效上下文長度。 MemGPT 主動從檔案儲存中檢索文件並且可以迭代地分頁瀏覽結果,因而其可用的文檔總數不再受到適用 LLM 處理器上下文視窗的文檔數量的限制。
由於基於嵌入的相似性搜尋的局限性,文件 QA 任務對所有方法都構成了極大的挑戰。研究者觀察到,MemGPT 會在檢索器資料庫耗盡之前停止對檢索器結果進行分頁操作。
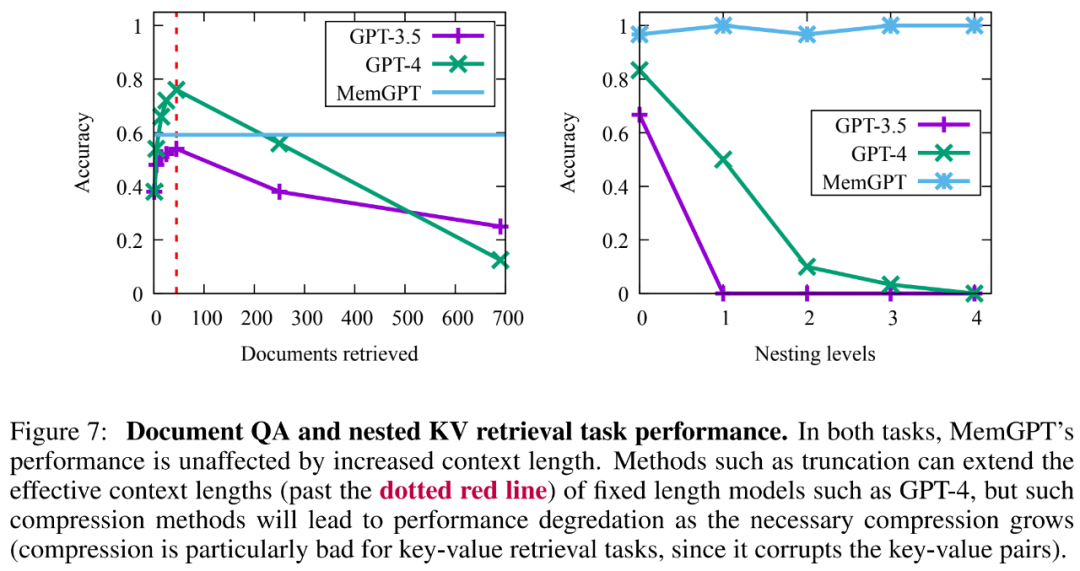
此外MemGPT 更複雜操作所創建的檢索文件容量也存在權衡,如下圖7 所示,其平均準確度低於GPT-4(高於GPT-3.5),但可以輕鬆擴展到更大的文檔。
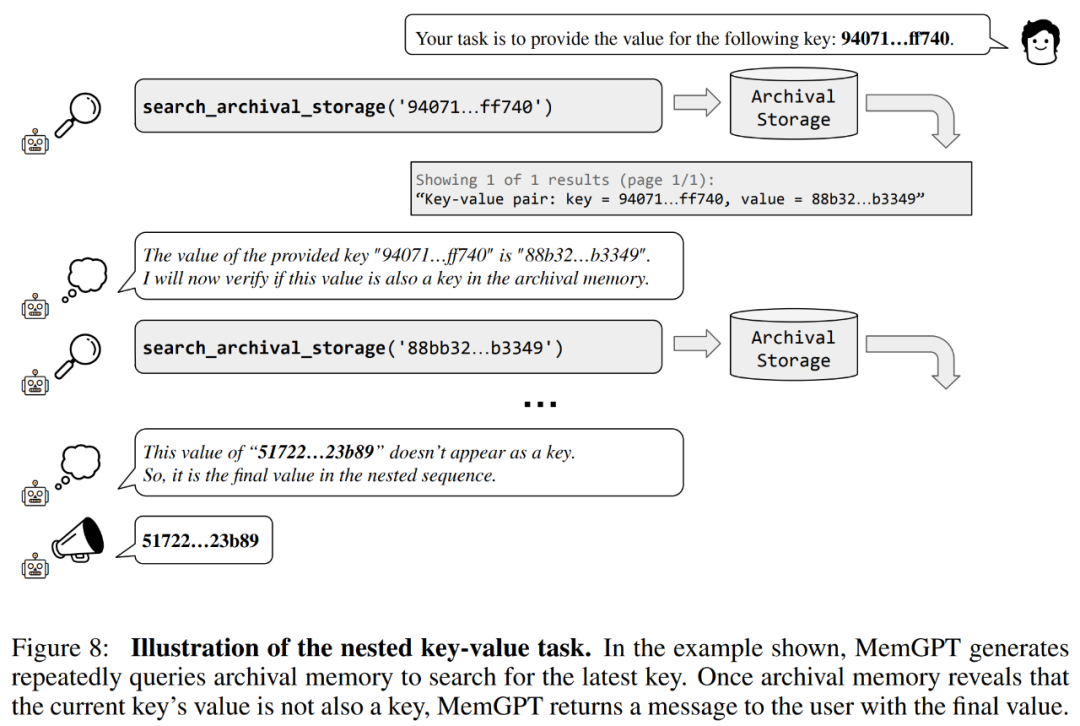
研究者也介紹了一個基於合成鍵值檢索的新任務,即嵌套鍵值檢索(Nested Key-Value Retrieval),以示範MemGPT 如何將來自多個資料來源的資訊進行整理。
從結果來看,雖然 GPT-3.5 和 GPT-4 在原始鍵值任務上表現出了良好效能,但在巢狀鍵值檢索任務中表現不佳。而 MemGPT 不受巢狀層數的影響,並且能夠透過函數查詢重複存取儲存在主記憶體中的鍵值對,來執行巢狀查找。
MemGPT 在巢狀鍵值檢索任務上的效能,展示了其利用多個查詢的組合執行多條查找的能力。
更多技術細節和實驗結果請參閱原始論文。
以上是把LLM視為作業系統,它就擁有了無限「虛擬」上下文,柏克萊新作已攬1.7k star的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















