


STRIDE是一種流行的威脅建模框架,目前被廣泛用於幫助組織主動發現可能對其應用系統造成影響的威脅、攻擊、漏洞和對策。如果將「STRIDE」中的每個字母拆開,分別代表著假冒、篡改、否認、資訊揭露、拒絕服務和特權提升
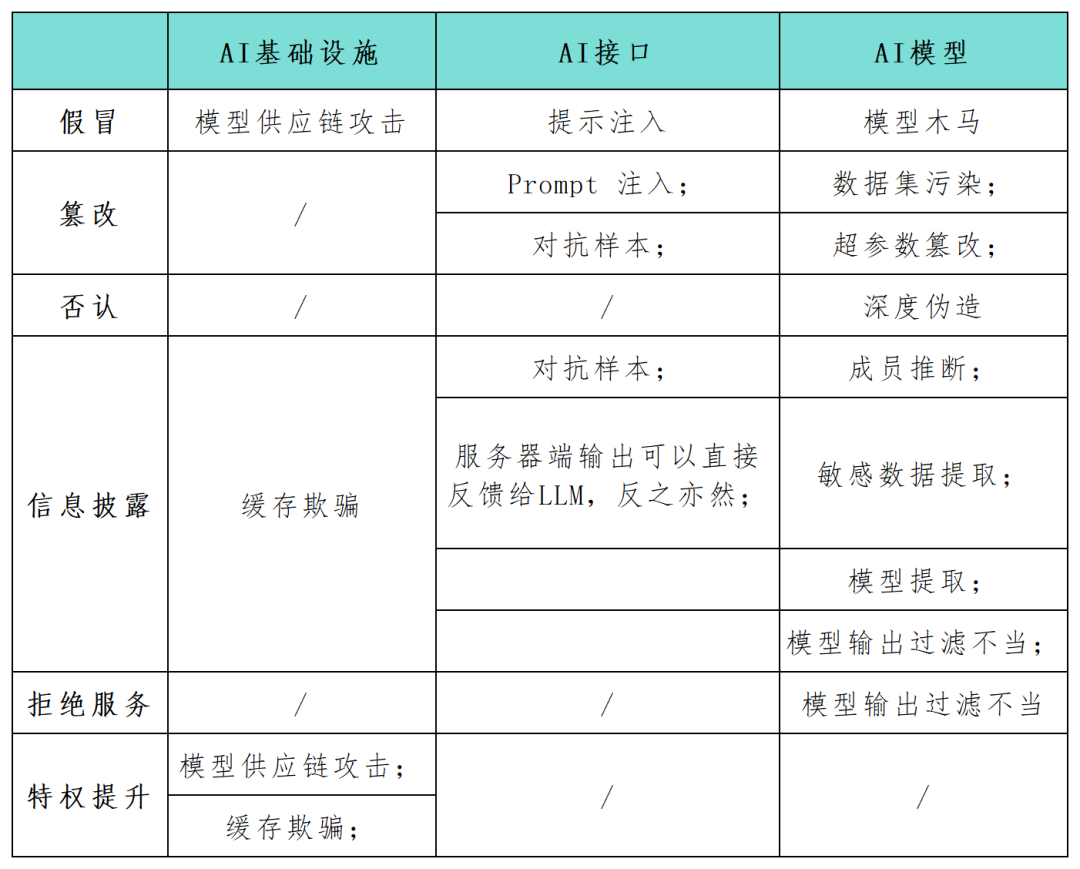
隨著人工智慧(AI)系統應用逐漸成為企業數位化發展的關鍵組成部分,許多安全從業者呼籲必須盡快識別和防護這些系統的安全風險。 STRIDE框架可以幫助組織更好地理解AI系統中可能的攻擊路徑,並增強其AI應用程式的安全性和可靠性。本文中,安全研究人員使用STRIDE模型框架全面梳理了映射了AI系統應用中的攻擊面(見下表),並對特定於AI技術的新攻擊類別和攻擊場景進行了研究。隨著AI技術的不斷發展,會出現更多新的模型、應用、攻擊和操作模式
AI研究員Andrej Karpathy指出,新一代深度神經網路模型的到來,標誌著傳統概念化軟體生產方式發生了典範轉移。開發人員越來越多地將AI模型嵌入複雜的系統中,這些模型不是用循環和條件的語言來表達的,而是用連續向量空間和數值權重來表達的,這也為漏洞利用創造了新的途徑,並催生了新的威脅類別。
如果攻擊者能夠篡改模型的輸入和輸出,或者改變AI基礎設施的某些設定參數,就有可能導致有害和不可預測的惡意結果,例如意外行為、與AI代理的交互以及對連結元件的影響
重寫後的內容:冒充行為是指在模型或元件交付過程中,攻擊者模擬可信任來源以引入惡意元素到AI系統中。這種技術使得攻擊者能夠將惡意元素注入AI系統。同時,冒充行為也可以作為模型供應鏈攻擊的一部分。例如,如果威脅行為者滲透了像Huggingface這樣的第三方模型提供商,在下游執行AI輸出的程式碼時,他們可以透過感染上游模型來控制周圍基礎設施
資訊揭露。敏感資料暴露是任何網路應用程式的常見問題,包括為AI系統提供服務的應用程式。在2023年3月,Redis的錯誤配置導致一個Web伺服器暴露了私人資料。一般來說,Web應用程式容易受到經典的OWASP十大漏洞的影響,如注入攻擊、跨站腳本和不安全的直接物件參考。這種情況同樣適用於為AI系統提供服務的Web應用程式。
拒絕服務(DoS)。 DoS攻擊也會對人工智慧應用造成威脅,攻擊者透過淹沒模型供應商的基礎設施以大量流量,使得人工智慧服務無法使用。在設計人工智慧系統的基礎設施和應用程式時,彈性是實現安全的基本要求,但這還不夠
#對於已訓練的AI模型以及較新的第三方生成型AI系統,同樣存在以下攻擊面威脅:
資料集污染和超參數篡改。 AI模型在訓練和推理階段容易受到特定的威脅,資料集污染和超參數篡改是STRIDE篡改類別下的攻擊,指的是威脅行為者將惡意資料注入訓練資料集。例如,攻擊者可以故意向人臉辨識AI中輸入誤導性的圖像,導致其錯誤地識別個體。
對抗樣本已經成為AI應用中常見的資訊外洩或竄改威脅方式。攻擊者透過操縱模型的輸入,使其產生錯誤的預測或分類結果。這些行為可能會洩露模型訓練資料中的敏感訊息,或以意想不到的方式欺騙模型行事。例如,一組研究人員指出,在停車標誌上添加小塊膠帶可能會混淆嵌入自動駕駛汽車的圖像識別模型,可能導致嚴重的後果
模型提取。模型提取是一種新發現的惡意攻擊形式,屬於STRIDE的資訊外洩類別。攻擊者的目標是基於模型的查詢和回應來複製專有的訓練機器學習模型。他們精心設計一系列查詢,並利用模型的回應來建立目標AI系統的副本。這種攻擊可能侵犯智慧財產權,並可能導致重大的經濟損失。同時,攻擊者擁有模型副本後,還可以執行對抗性攻擊或反向工程訓練數據,從而產生其他威脅。
大語言模型(LLM)的流行推動了新型AI攻擊方式的出現,LLM開發和整合是一個非常熱門的話題,因此,針對其的新攻擊模式層出不窮。為此,OWASP研究團隊已經開始起草首個版本的OWASP Top 10 LLM威脅計畫。
重寫後的內容:輸入提示攻擊是指越獄、提示洩漏和令牌走私等行為。在這些攻擊中,攻擊者會利用輸入提示來觸發LLM的意外行為。這種操縱可能導致人工智慧產生不恰當的反應或洩露敏感訊息,與STRIDE模型中的欺騙和資訊外洩類別一致。當人工智慧系統與其他系統結合或在軟體應用程式鏈中使用時,這些攻擊尤其危險
不當的模型輸出及過濾。大量的API應用可能以各種非公開暴露的方式被利用。例如,像Langchain這樣的框架可以讓應用程式開發人員在公共生成式模型和其他公有或私有系統(如資料庫或Slack整合)上快速部署複雜的應用程式。攻擊者可以建構一個提示,欺騙模型進行原本不允許的API查詢。同樣地,攻擊者也可以將SQL語句注入通用未淨化的web表單中以執行惡意程式碼。
成員推理和敏感資料提取是需要重新編寫的內容。攻擊者可以利用成員推理攻擊以二進制方式推斷特定資料點是否在訓練集中,從而引起隱私問題。資料提取攻擊允許攻擊者從模型的回應中完全重建關於訓練資料的敏感資訊。當LLM在私有資料集上訓練時,常見的情況是模型可能具有敏感的組織數據,攻擊者可以透過創建特定的提示來提取機密資訊
重寫後的內容:木馬模型是一種被證明在微調階段容易受到訓練資料集污染影響的模型。此外,篡改熟悉的公共訓練資料在實踐中也被證明是可行的。這些弱點為公開可用的語言模型打開了木馬模型的大門。從表面上看,它們的功能與大多數提示的預期一樣,但它們隱藏了在微調期間引入的特定關鍵字。一旦攻擊者觸發這些關鍵字,木馬模型就可以執行各種惡意行為,包括提升特權、使系統無法使用(DoS)或洩露私人敏感資訊等
#參考連結:
#需要重寫的內容是:https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
以上是從STRIDE威脅模型看AI應用的攻擊面威脅與管理的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















