


目前,在自動駕駛的車輛中已經配備了多種資訊擷取感測器,如雷射雷達、毫米波雷達以及相機感測器。從目前來看,多種感測器在自動駕駛的感知任務中顯示出了巨大的發展前景。例如,相機採集到的2D影像資訊捕捉了豐富的語義特徵,雷射雷達收集到的點雲資料可以為感知模型提供物體的準確位置資訊和幾何資訊。透過充分利用不同感測器所獲得的信息,可以減少自動駕駛感知過程中的不確定性因素的發生,同時提升感知模型的檢測魯棒性
今天介紹的是一篇來自曠視的自動駕駛感知論文,並且中稿了今年的ICCV2023 視覺頂會,該文章的主要特點是類似PETR這類End-to-End的BEV感知演算法(不再需要利用NMS後處理操作過濾感知結果中的冗餘餘框),同時又額外使用了雷射雷達的點雲資訊來提高模型的感知性能,是一篇非常不錯的自動駕駛感知方向的論文,文章的連結和官方開源倉庫連結如下:
接下來,我們將對CMT感知模型的網路結構進行整體介紹,如下圖所示:
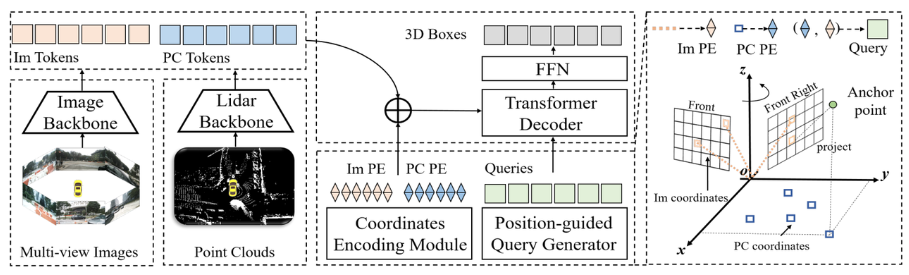
透過整個演算法框圖可以看出,整個演算法模型主要包括三個部分
在詳細介紹了網路的整體結構之後,接下來將詳細介紹上述提到的三個子部分
#輸入:2D Backbone輸出的降採樣16倍和32倍的特徵圖
輸出:將下取樣16倍和32倍的影像特徵進行融合,取得降採樣16倍的特徵圖
Tensor([bs * N, 1024, H / 16 , W / 16])
Tensor([bs * N,2048,H / 16,W / 16])
需要重新寫的內容是:張量([bs * N,256,H / 16,W / 16])
重寫內容:使用ResNet-50網路來擷取環視圖像的特徵
#輸出:輸出下取樣16倍和32倍的影像特徵
輸入張量:Tensor([bs * N,3,H,W])
Tensor([bs * N,1024,H / 16,W / 16])
在BEV空間的網格座標點利用#pos2embed()函數將二維的橫縱座標點轉換到高維度的特徵空間
# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
#透過使用多層感知器(MLP)網絡進行空間轉換,確保通道數的對齊
#查詢嵌入
bev_query_embeds產生邏輯
def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
rv_query_embeds產生邏輯需要重新寫
def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds
#
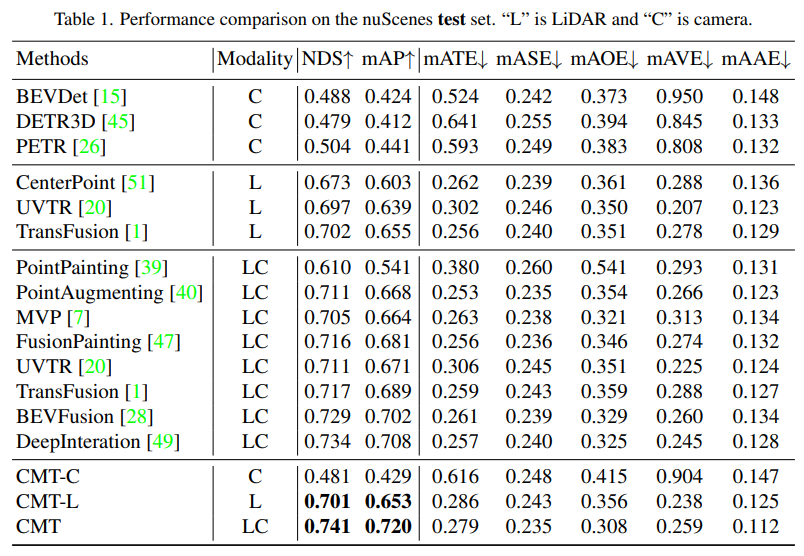
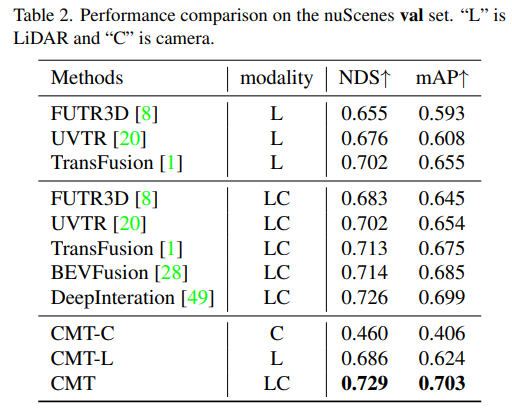 接下來是CMT創新點的消融實驗部分
接下來是CMT創新點的消融實驗部分
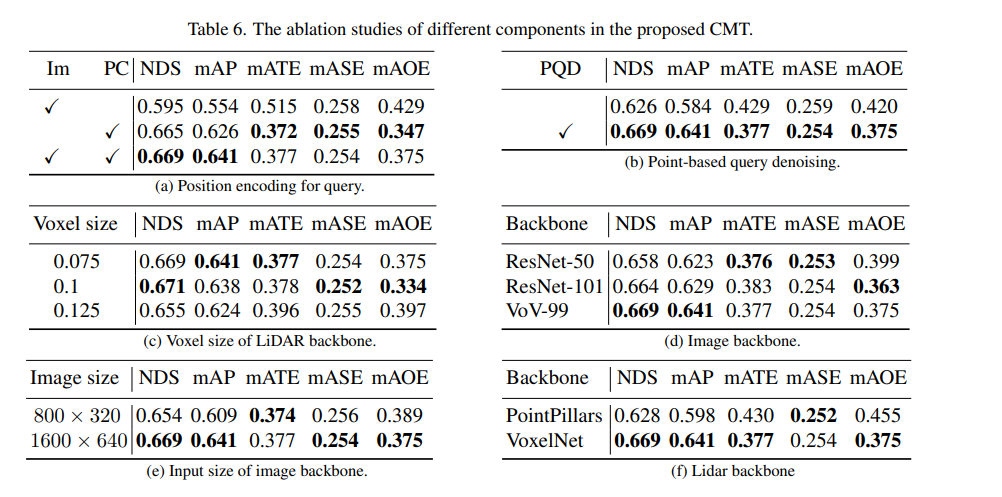 #首先,我們進行了一系列消融實驗,來確定是否採用位置編碼。透過實驗結果發現,當同時採用影像和雷射雷達的位置編碼時,NDS和mAP指標實現了最佳效果。接下來,在消融實驗的(c)和(f)部分,我們對點雲主幹網路的類型和體素大小進行了不同的嘗試。而在(d)和(e)部分的消融實驗中,我們則對相機主幹網路的類型和輸入解析度的大小進行了不同的嘗試。以上只是對實驗內容的簡要概括,如需了解更多詳細的消融實驗,請參閱原文
#首先,我們進行了一系列消融實驗,來確定是否採用位置編碼。透過實驗結果發現,當同時採用影像和雷射雷達的位置編碼時,NDS和mAP指標實現了最佳效果。接下來,在消融實驗的(c)和(f)部分,我們對點雲主幹網路的類型和體素大小進行了不同的嘗試。而在(d)和(e)部分的消融實驗中,我們則對相機主幹網路的類型和輸入解析度的大小進行了不同的嘗試。以上只是對實驗內容的簡要概括,如需了解更多詳細的消融實驗,請參閱原文
最後放一張CMT的感知結果在nuScenes數據集上可視化結果的展示,通過實驗結果可以看出,CMT還是有較好的感知結果的。

需要重寫的內容是: 原文連結:https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
以上是跨模態Transformer:面向快速穩健的3D目標偵測的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















