

逼真的影像生成在虛擬實境、擴增實境、電玩遊戲和電影製作等領域有廣泛應用。
隨著近兩年來擴散模型的快速發展,影像生成領域取得了重大突破。從Stable Diffusion衍生出的一系列根據文字描述生成圖像的開源或商業模型,已經對設計、遊戲等領域產生了巨大的影響
然而,如何根據給定的文字或其他條件,產生高品質的多視角圖像仍然是一個挑戰。已有的方法在多視圖一致性方面存在明顯的缺陷
目前常見的方法可以大致分為兩類
第一類別方法致力於產生一個場景的圖片以及深度圖,並得到對應的mesh,如Text2Room,SceneScape-首先用Stable Diffusion產生第一張圖片,然後使用影像扭轉(Image Warping)和影像補全(image inpainting )的自回歸方式產生後續的圖片以及深度圖。
但是,這樣的方案容易導致錯誤在多張圖片的生成過程中逐漸累積,並且通常存在閉環問題(例如在相機旋轉一圈回到起始位置附近時,產生的內容與第一張圖片並不完全一致),導致其在場景規模較大或圖片間視角變化較大時的效果欠佳。
第二類方法透過擴展擴散模型的生成演算法,同時產生多張圖片,以產生比單張圖片更豐富的內容(例如生成360度全景圖,或將一張圖片的內容向兩側無限外推),例如MultiDiffusion和DiffCollage。然而,由於沒有考慮相機模型,這類方法產生的結果並不是真正的全景圖
MVDiffusion的目標是產生符合給定相機模型的多視角圖片,這些圖片在內容上嚴格一致且具有全局語義統一。此方法的核心思想是同時去噪和學習圖片之間的對應關係以保持一致性

#請點擊以下連結查看論文:https ://arxiv.org/abs/2307.01097
請造訪專案網站:https://mvdiffusion.github.io/
#Demo : https://huggingface.co/spaces/tangshitao/MVDiffusion
#:https://github.com/Tangshitao/MVDiffusion
會議發表:NeurIPS(重點)
MVDiffusion的目標是透過同步去雜訊和基於圖片之間對應關係的全局意識,產生內容高度一致且全局語義統一的多視角圖片
具體地,研究人員對現有的文字-圖片擴散模型(如Stable Diffusion)進行拓展,首先讓其並行地處理多張圖片,並進一步在原本的UNet中加入額外的「Correspondence-aware Attention」機制來學習多重視角間的一致性和全域的統一性。
透過在少量的多視角圖片訓練資料上進行微調,最後得到的模型能夠同步產生內容高度一致的多視角圖片。
MVDiffusion在三個不同的應用程式場景中已經取得了很好的效果:
根據文字產生多個視圖,然後拼接以取得全景圖
2. 將透視影像外推(outpainting)得到完整的360度全景圖;
3. 為場景生成材質(texture)。
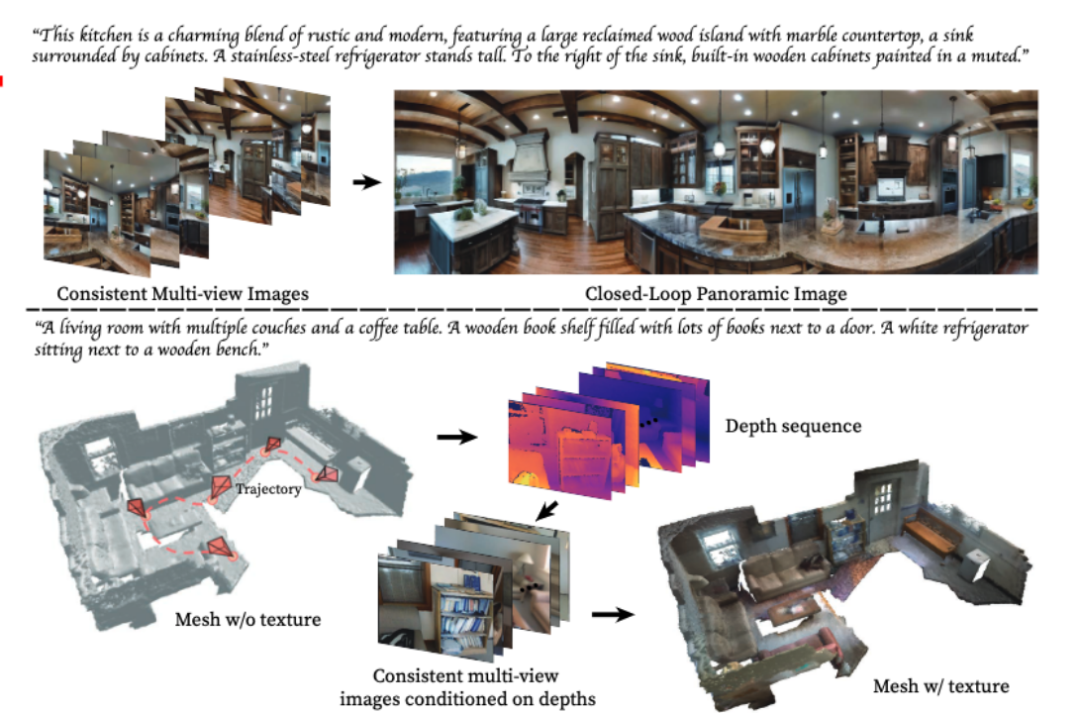
以產生全景圖為例,輸入一段描述場景的文字,MVDIffusion可以產生一個場景的多視角圖片
輸入以下內容可以獲得8張多視角圖片:「這個廚房是鄉村與現代的迷人融合,擁有一個大型的回收木島台帶有大理石檯面,一個被櫥櫃環繞的水槽。島台的左邊是一台高大的不銹鋼冰箱。水槽的右邊是塗有柔和色彩的內置木製櫥櫃。」

這8張圖片能夠拼接成全景圖:

MVDiffusion也支持為每張圖片提供不同的文字描述,但是這些描述之間需要保持語義上的一致性。
MVDiffusion能夠將一張透視圖像外推(outpainting)成完整的360度全景圖。
舉個例子,假設我們輸入下面這張透視圖:

MVDiffusion能進一步生成下面的全景圖:

可以看到,生成的全景圖在語義上對輸入圖片進行了擴展,而且最左和最右的內容是相連的(沒有閉環問題)。
使用MVDiffusion可以為給定的無材質場景網格產生材質(紋理)
#具體地,我們首先透過渲染mesh得到多視角的深度圖(depth map),透過相機位姿(pose)以及深度圖,我們可以獲得多視角圖片的像素之間的對應關係。
接著,MVDiffusion以多視角depth map為條件,同步產生一致的多視角RGB圖片。
因為產生的多視角圖片能保持內容的高度一致,將它們再投回mesh,也就是可以獲得高品質的帶材質的mesh(textured mesh)。
以下是更多的效果範例:
」全景圖產生的過程是將多張照片或視頻拼接在一起,以創建一個全景視角的圖像或視訊。這個過程通常涉及使用特殊的軟體或工具來自動或手動地將這些影像或影片進行對齊、融合和修復。透過全景圖生成,人們可以以更廣闊的視野來欣賞和體驗場景,例如風景、建築物或室內空間。這項技術在旅遊、房地產、虛擬實境等領域具有廣泛的應用




##在這個應用程式場景中,需要特別提到的是,雖然在訓練MVDiffusion時使用的多視角圖片資料都來自於室內場景的全景圖,而且風格都是單一的
然而,MVDiffusion並沒有改變原始的穩定擴散參數,而只是對新加入的Correspondence-aware Attention進行了訓練
最後,模型依然能根據給定的文字產生各種不同風格的多視角圖片(如室外,卡通等)。
需要進行改寫的內容是:單一視圖外推



#場景材質產生

#我們會先介紹MVDiffusion在三個不同任務中的特定圖片產生流程,最後介紹方法的核心部分,也就是「Correspondence-aware Attention」模組。圖1展示了MVDiffusion的概覽
#MVDiffusion同步產生8張帶有重疊的圖片(perspective image),然後再將這8中圖片縫合(stitch)成全景圖。在這8張透視圖中,每兩張圖之間由一個3x3單應矩陣(homographic matrix)決定其像素對應關係。
在具體的生成過程中,MVDiffusion首先使用高斯隨機初始化來產生8個視角的圖片
然後,將這8張圖片輸入到一個具有多個分支的Stable Diffusion預訓練Unet網路中,進行同步去噪(denoising)得到產生結果。
其中UNet網路中加入了新的「Correspondence-aware Attention」模組(上圖中淡藍色部分),用於學習跨視角之間的幾何一致性,使得這8張圖片可以被拼接成一張一致的全景圖。
MVDiffusion也可以將單張透視圖補全成全景圖。與全景圖產生的過程是將多張照片或影片拼接在一起,以創建一個全景視角的圖像或影片。這個過程通常涉及使用特殊的軟體或工具來自動或手動地將這些影像或影片進行對齊、融合和修復。透過全景圖生成,人們可以以更廣闊的視野來欣賞和體驗場景,例如風景、建築物或室內空間。這項技術在旅遊、房地產、虛擬實境等領域具有廣泛的應用相同,MVDiffusion將隨機初始化的8個視角圖片(包括透視圖對應的視角)輸入到多分支的Stable Diffusion Inpainting預訓練的UNet網路中。
在Stable Diffusion Inpainting模型中,與之不同的是,UNet透過使用額外的輸入掩碼(mask)來區分作為條件的圖片和將要產生的圖片
透視圖對應的視角,遮罩設為1,該分支的UNet將直接恢復透視圖。而其他視角,遮罩設為0,對應分支的UNet將產生新的透視圖
同樣地,MVDiffusion使用「Correspondence-aware Attention」模組來學習產生圖片與條件圖片之間的幾何一致性與語意統一性。
#MVDiffusion首先基於深度圖以及相機位姿產生一條軌跡上的RGB圖片,然後使用TSDF fusion將產生的RGB圖片與給定的深度圖合成mesh。
RGB圖片的像素對應關係可以透過深度圖和相機位姿得到。
與全景圖產生的過程是將多張照片或影片拼接在一起,以建立一個全景視角的影像或影片。這個過程通常涉及使用特殊的軟體或工具來自動或手動地將這些影像或影片進行對齊、融合和修復。透過全景圖生成,人們可以以更廣闊的視野來欣賞和體驗場景,例如風景、建築物或室內空間。這項技術在旅遊、房地產、虛擬實境等領域具有廣泛的應用一樣,我們使用多分支UNet,並插入「Correspondence-aware Attention」來學習跨視角之間的幾何一致性。
##「Correspondence-aware Attention」(CAA),是MVDiffusion的核心,用於學習多視圖之間的幾何一致性和語義統一性。
MVDiffusion在Stable Diffusion UNet中的每個UNet block之後插入「Correspondence-aware Attention」block。 CAA透過考慮源特徵圖和N個目標特徵圖來運作。
對於來源特徵圖中的一個位置,我們基於目標特徵圖中的對應像素及其鄰域來計算注意力輸出。
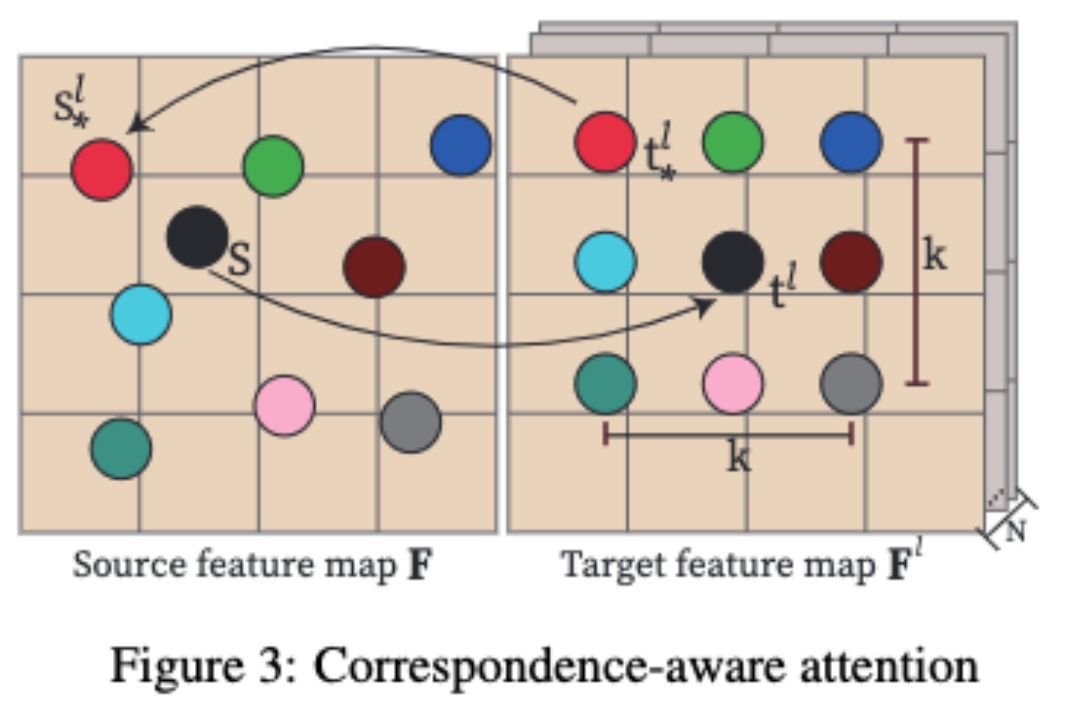
具體來說,對於每個目標像素t^l,MVDiffusion會透過在(x/y)座標上添加整數位移(dx/dy)來考慮一個K x K的鄰域,其中|dx|表示在x方向上的位移大小,|dy|表示在y方向上的位移大小
在實際應用中,MVDiffusion演算法使用K=3,並選擇9點鄰域來提高全景圖的品質。然而,在產生受幾何條件限制的多視圖影像時,為了提高運行效率,選擇使用K=1
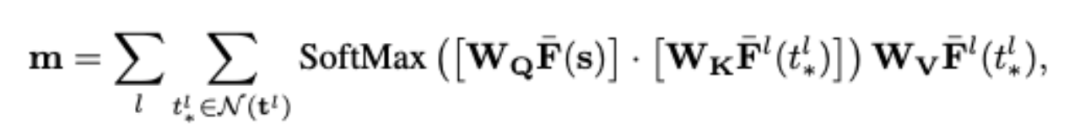
CAA模組的計算遵循標準的注意力機制,如上圖的公式所示,其中W_Q、W_K和W_V是query、key和value矩陣的可學習權重;目標特徵不位於整數位置,而是透過雙線性內插法獲得的。
關鍵的區別是基於來源影像中的對應位置s^l與s之間的2D位移(全景)或1D深度誤差(幾何)向目標特徵添加了位置編碼。
在全景生成中(應用1和應用2),這個位移提供了本地鄰域中的相對位置。
而在深度到影像生成(應用3),視差提供了關於深度不連續或遮蔽的線索,這對於高保真影像生成非常重要。
請注意,位移是一個包含2D(位移)或1D(深度誤差)向量的概念。 MVDiffusion將標準頻率編碼套用於位移的x和y座標
以上是MVDiffusion:實現高品質多視角影像生成與精確復刻場景材質的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















