

驚人發現:大模型在知識推演上有嚴重缺陷。
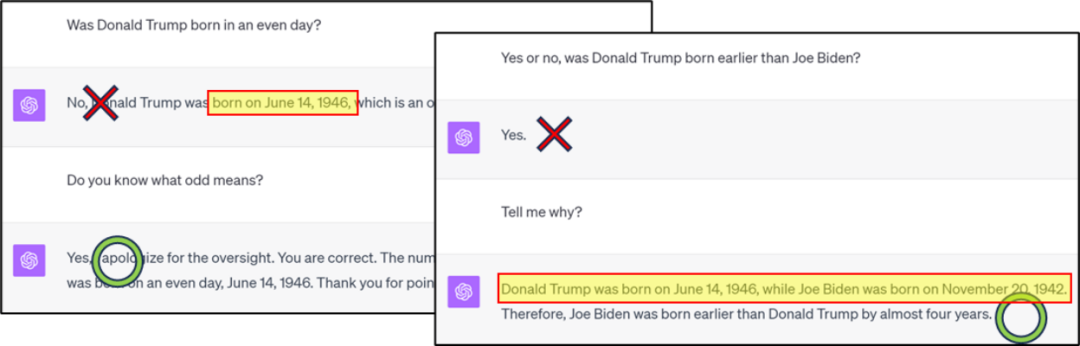
#需要重新寫作的內容是:圖1:GPT4在知識分類/比較上出現錯誤,但透過思考鏈可以得到正確答案
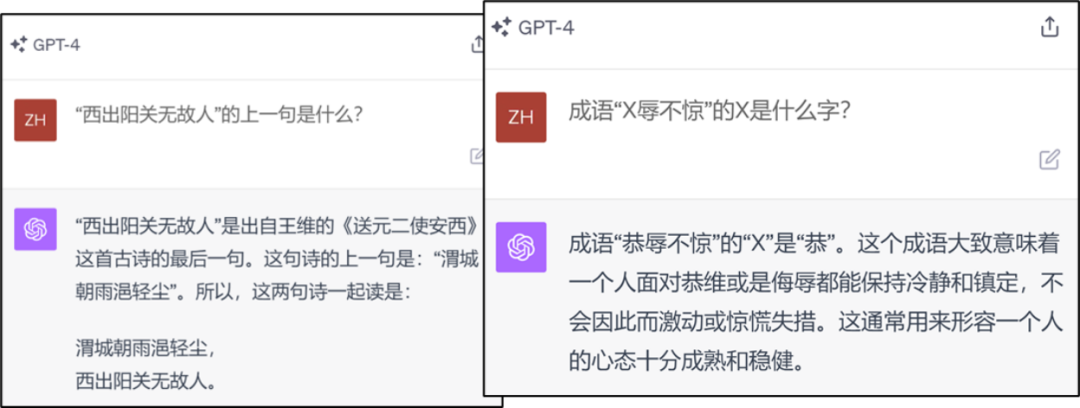
需要重新寫的內容是:圖2:GPT4知識逆向搜尋錯誤範例


請點選以下連結查看論文:https://arxiv.org/abs/2309.14402
先問一個問題,例如圖1/2/ 3 這樣的問題,是GPT4 對人的生日記憶不夠精確(壓縮比不夠,訓練loss 不夠低),還是未透過微調深化對奇偶性的理解?是否可以透過微調 GPT4,使其能夠在模型內部組合現有知識,產生 "生日的奇偶性" 這種新知識,從而無需依賴 CoT 直接回答相關問題?由於我們不知道 GPT4 的訓練資料集,無法微調。因此,作者提出透過可控訓練集,來更深入研究語言模型的 “知識推演” 能力。

圖是否發生
在《語言模型物理學Part 3.1:知識的儲存與提取》一文中,作者建構了一個包含10萬個人物傳記的資料集。每個傳記都包括人名以及六個屬性:出生日期、出生地、大學專業、大學名稱、工作地點和工作單位。舉個例子:
「Anya Briar Forgeroriginated fromPrinceton, NJ.She dedicated her studies toCommunications. She gained work experience inMenlo Park, CA. She developed her career atMeta Platforms. She came into this world onOctober 2, 1996. She pursued advanced coursework at
##########. MIT.###”######作者確保了傳記條目的多樣性,以幫助模型更好的存取知識。在預訓練(pretrain) 後,模型能透過微調準確回答知識提取類別問題,如「Anya 的生日是哪天」(正確率接近100%)######接下來作者繼續微調,試圖讓模型學習知識推演類問題,如知識的分類/ 比較/ 加減。文章發現,自然語言模型在知識推演方面的能力非常有限,難以透過微調產生新知識,###即使它們只是模型已掌握知識的簡單變換 / 組合。 ######

圖5:若微調時不使用CoT,讓模型進行知識的分類/ 比較/ 減法,需要海量的樣本或正確率極低-實驗中花了100 個專業
如圖5,作者發現,儘管預訓練(pretrain)之後模型已經能準確回答每個人的生日(正確率接近100%),但要透過微調讓其回答「xxx 的出生月是偶數嗎?」 並達到75% 的正確率—— 別忘了盲猜有50% 的正確率—— 需要至少10000 個微調樣本。相較之下,如果模型能正確完成 “生日” 和 “奇偶性” 的知識組合,那麼根據傳統機器學習理論,模型只需學習對 12 個月份進行二分類,通常約 100 個樣本就足夠了!
同樣,即使經過模型預訓練後,它能夠準確回答每個人的專業(共100個不同專業),但是即使使用了50000個微調樣本,讓模型比較“Anya的專業和Sabrina的專業哪個更好”,正確率僅為53.9%,幾乎相當於瞎猜
然而,當我們使用CoT微調模型學習"Anya的出生月是十月,因此是偶數"這樣的句子時,模型在測試集上判斷出生月奇偶性的準確率顯著提高(參見圖5中的"測試用CoT"一列)
作者也嘗試在微調訓練資料中混合CoT和非CoT的回答,結果發現模型在測試集上不使用CoT時的正確率仍然很低(見圖5的"test不用CoT"一列)。這說明,即便補上足夠的CoT微調數據,模型依然無法學會"顱內思考"並直接報答案
這些結果表明,對於語言模型來說,進行簡單的知識運算極其困難!模型必須先把知識點寫出來再進行運算,無法像人一樣在大腦裡直接進行操作,即使經過充分的微調也無濟於事。
逆向知識搜尋所面臨的挑戰
研究也發現,自然語言模型無法透過逆向搜尋來應用所學到的知識。儘管它可以回答有關某人的所有信息,但無法根據這些信息確定人名
作者對GPT3.5/4進行了試驗,發現它們在逆向知識提取方面表現不佳(見圖6) 。然而,由於我們無法確定GPT3.5/4的訓練資料集,這並不能證明所有語言模型都存在這個問題

##圖6 :GPT3.5/4正向/逆向知識搜尋的比較。我們先前所報道的"逆轉詛咒"工作(arxiv 2309.12288)也在現有的大模型上觀察到了這一現象
作者利用前述的人物傳記資料集,對模型的逆向知識搜尋能力進行了更深入的可控試驗。由於所有傳記的人名都在段首,作者設計了10個反向資訊擷取問題,例如: 請問您知道在1996年10月2日在新澤西州普林斯頓出生的人叫什麼名字嗎? 「請告訴我在MIT 學習Communications ,1996 年10 月2 日在Princeton, NJ 出生,並在Menlo Park, CA 的Meta Platforms 工作的人的名字是什麼?」
需要進行改寫的內容是:圖7:在名人傳記資料集上進行的可控試驗
作者驗證了,儘管模型實現了無損知識壓縮和充分知識增強,且能幾乎100% 正確提取這些知識,在經過微調後,模型仍無法進行知識的逆向搜索,準確率幾乎為零(見圖7)。但是,一旦逆向知識直接出現在預訓練集中,逆向搜尋的準確率立即飆升。 綜上所述,只有在預訓練集(pretrain data) 中直接包含了逆向知識時,模型才能透過微調來回答逆向問題—— 但這實際上是作弊,因為如果知識已經反轉,就不再是「逆向知識搜尋」 了。如果預訓練集只包含正向知識,模型無法透過微調來掌握逆向回答問題的能力。因此,使用語言模型進行知識索引 (knowledge database) 目前看來是不可能的。
此外,有些人可能會認為,上述的"逆向知識搜尋"失敗是因為自回歸語言模型(如GPT)是單向的。然而,實際上,雙向語言模型(如BERT)在知識提取方面表現更差,甚至在正向提取方面也會失敗。對於有興趣的讀者,可以參考論文中的詳細資訊以上是語言模型有重大缺陷,知識推演竟然是老大難的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































