

學生化殘差通常用於迴歸分析,以識別資料中潛在的異常值。異常值是與資料總體趨勢顯著不同的點,它可以對擬合模型產生重大影響。透過識別和分析異常值,您可以更好地了解資料中的潛在模式並提高模型的準確性。在這篇文章中,我們將仔細研究學生化殘差以及如何在 python 中實現它。
術語「學生化殘差」是指一類特定的殘差,其標準差除以估計值。迴歸分析殘差用於描述反應變數的觀測值與其模型產生的預期值之間的差異。為了找到資料中可能顯著影響擬合模型的異常值,採用了學生化殘差。
以下公式通常用於計算學生化殘差 -
studentized residual = residual / (standard deviation of residuals * (1 - hii)^(1/2))
其中「殘差」是指觀測到的反應值與預期反應值之間的差異,「殘差標準差」是指殘差標準差的估計值,而「hii」是指每個數據點的槓桿因子。
statsmodels 套件可用於計算 Python 中的學生化殘差。作為說明,請考慮以下內容 -
OLSResults.outlier_test()
其中 OLSResults 指的是使用 statsmodels 的 ols() 方法擬合的線性模型。
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83],
'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
model = ols('rating ~ points', data=df).fit()
stud_res = model.outlier_test()
其中「評級」和「分數」指的是簡單線性迴歸。
導入 numpy、pandas、Statsmodel api。
建立資料集。
對資料集執行簡單的線性迴歸模型。
計算學生化殘差。
列印學生化殘差。
此處示範了使用 scikit−posthocs 函式庫來執行 Dunn 的測試 -
#import necessary packages and functions
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#create dataset
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83], 'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
接下來使用 statsmodels OLS 類別建立線性迴歸模型 -
#fit simple linear regression model
model = ols('rating ~ points', data=df).fit()
使用離群值 test() 方法,可以在 DataFrame 中產生資料集中每個觀察值的學生化殘差 -
#calculate studentized residuals stud_res = model.outlier_test() #display studentized residuals print(stud_res)
student_resid unadj_p bonf(p) 0 1.048218 0.329376 1.000000 1 -1.018535 0.342328 1.000000 2 0.994962 0.352896 1.000000 3 0.548454 0.600426 1.000000 4 1.125756 0.297380 1.000000 5 -0.465472 0.655728 1.000000 6 -0.029670 0.977158 1.000000 7 -2.940743 0.021690 0.216903 8 0.100759 0.922567 1.000000 9 -0.134123 0.897080 1.000000
我們也可以根據學生化殘差快速繪製預測變數值 -
x = df['points']
y = stud_res['student_resid']
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
這裡我們將使用 matpotlib 函式庫來繪製顏色 = 'black' 和生活方式 = '--' 的圖表
導入matplotlib的pyplot函式庫
#定義預測變數值
#定義學生化殘差
#建立預測變數與學生化殘差的散佈圖
import matplotlib.pyplot as plt
#define predictor variable values and studentized residuals
x = df['points']
y = stud_res['student_resid']
#create scatterplot of predictor variable vs. studentized residuals
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
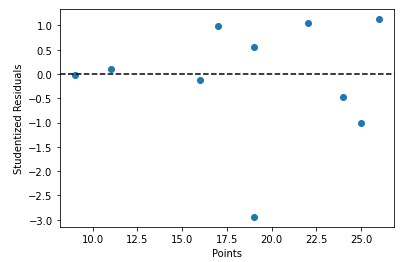
識別和評估可能的資料異常值。檢查學生化殘差可以讓您找到與數據總體趨勢有很大偏差的點,並探索它們影響擬合模型的原因。識別顯著觀測值 學生化殘差可用於發現和評估有影響力的數據,這些數據對擬合模型有重大影響。尋找高槓桿點。學生化殘差可用於辨識高槓桿點。槓桿是衡量某一點對適配模型影響程度的指標。整體而言,使用學生化殘差有助於分析和提高迴歸模型的表現。
以上是如何在Python中計算學生化殘差?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















