

隨著大型模型的開發和應用火熱發展,作為大型模型核心基礎組件的Embedding的重要性變得越來越突出。智源公司在一個月前發布的開源可商用的中英文語義向量模型BGE(BAAI General Embedding)在社區中引起了廣泛的關注,Hugging Face平台上的下載量已經達到了數十萬次。目前,BGE已經快速迭代推出了1.5版本,並公佈了多項更新。其中,BGE首次開源了三億條大規模訓練數據,為社區提供了訓練類似模型的幫助,推動了該領域技術的發展
#第一個開源的業界語意向量模型訓練資料達到了3億個中英文資料
BGE 的出色能力很大程度源自於其大規模、多樣化的訓練資料。此前,業界同業鮮有發布同類數據集。在本次更新中,智源首次將 BGE 的訓練資料向社群開放,為推動此類技術進一步發展打下了基礎。
此發佈的資料集 MTP 由總計 3 億條中英文關聯文字對構成。其中,中文記錄達 1 億條,英文數據達 2 億條。資料的來源包括 Wudao Corpora、Pile、DuReader、Sentence Transformer 等語料。經過必要的取樣、抽取和清洗後獲得
詳細細節請參考 Data Hub:https://data.baai.ac.cn
MTP 為迄今開源的最大規模中英文關聯文字對資料集,為訓練中英文語意向量模型提供重要基礎。
#根據社區回饋,BGE 在其1.0 版本的基礎上進行了進一步優化,使其表現更加穩定和出色。具體的升級內容如下:
值得一提的是,日前,智源聯合 Hugging Face 發布了一篇技術報告,報告提出用 C-Pack 增強中文通用語義向量模型。
《C-Pack: Packaged Resources To Advance General Chinese Embedding》
連結:https://arxiv.org/pdf/2309.07597 .pdf
BGE 自發布以來受到了大型模式開發者社群的關注,目前Hugging Face的下載量已經達到了數十萬次,並且已經被知名的開源專案LangChain、LangChain-Chatchat、llama_index 等整合使用
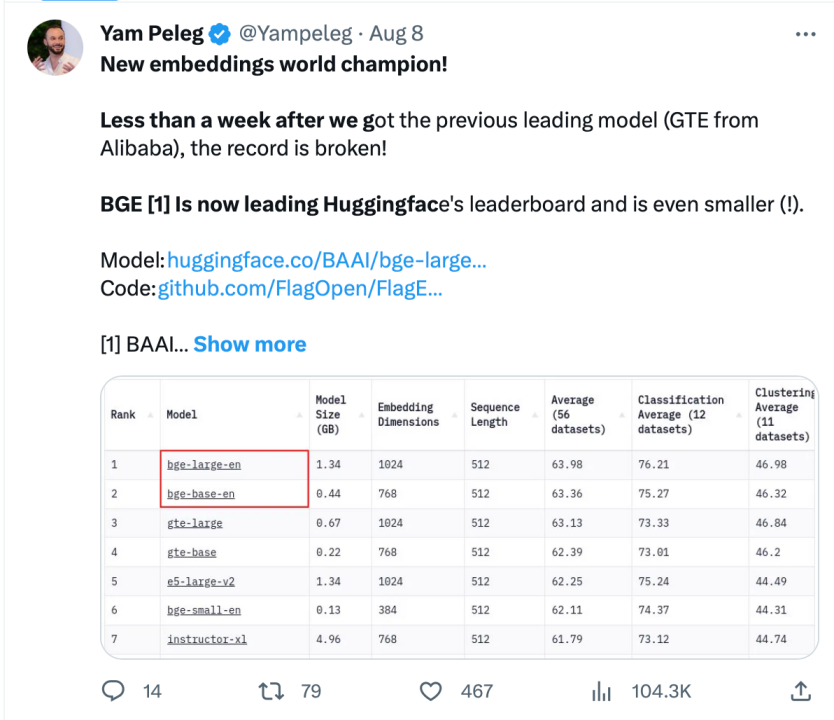
Langchain 官方、LangChain 聯合創始人兼首席執行官Harrison Chase、Deep trading 創辦人Yam Peleg 等社區大V 對BGE 表示關切。
堅持開源開放,促進協同創新,智源大模型技術開體系 FlagOpen BGE 新增 FlagEmbedding 新版塊,專注於 Embedding 技術和模型,BGE 是其中備受矚目的開源專案之一。 FlagOpen 致力於建構大模型時代的人工智慧技術基礎設施,未來將繼續向學術界和產業界開放更完整的大模型全端技術
#以上是智源開放3億個語意向量模型訓練數據,BGE模型持續進行迭代更新的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















