

近年來,自動摘要技術取得了長足的進步,這主要歸功於範式的轉變——從在標註資料集上進行有監督微調轉變為使用大語言模型(LLM)進行零樣本提示,例如GPT-4。無需額外訓練,精心設計的提示就能實現對摘要長度、主題、風格等方面特徵的精細控制
但一個方面常常被忽略:摘要的資訊密度。從理論上講,作為另一個文本的壓縮,摘要應該比原始檔案更密集,也就是包含更多的資訊。考慮到 LLM 解碼的高延遲,用更少的字數涵蓋更多的資訊非常重要,尤其是對於即時應用而言。
然而,資訊量密度是一個開放式的問題:如果摘要包含的細節不足,那麼相當於沒有資訊量;如果包含的資訊過多,又不增加總長度,就會變得難以理解。要在固定的詞彙預算內傳遞更多訊息,就需要將抽象、壓縮、融合三者結合起來
在最近的一項研究中,來自Salesforce、MIT 等機構的研究者試圖透過徵求人類對GPT-4 產生的一組密度越來越高的摘要的偏好來確定這一限制。對於提升 GPT-4 等大語言模型的「表達能力」,此方法提供了許多啟發。

論文連結:https://arxiv.org/pdf/2309.04269.pdf
數據集合位址:https://huggingface.co/datasets/griffin/chain_of_density
具體來說,他們的方法是將每個標記的平均實體數量作為密度的代表,生成一個初始的、實體稀少的摘要。然後,在不增加總長度(總長度為原摘要的5倍)的情況下,反覆識別並融合前一個摘要中缺失的1-3個實體,使得每個摘要中實體與標記的比例都高於前一個摘要。透過人類偏好資料的分析,作者最終確定了一種幾乎與人類編寫的摘要一樣密集的摘要形式,比普通GPT-4 prompt 生成的摘要更加密集
該研究的整體貢獻包括:
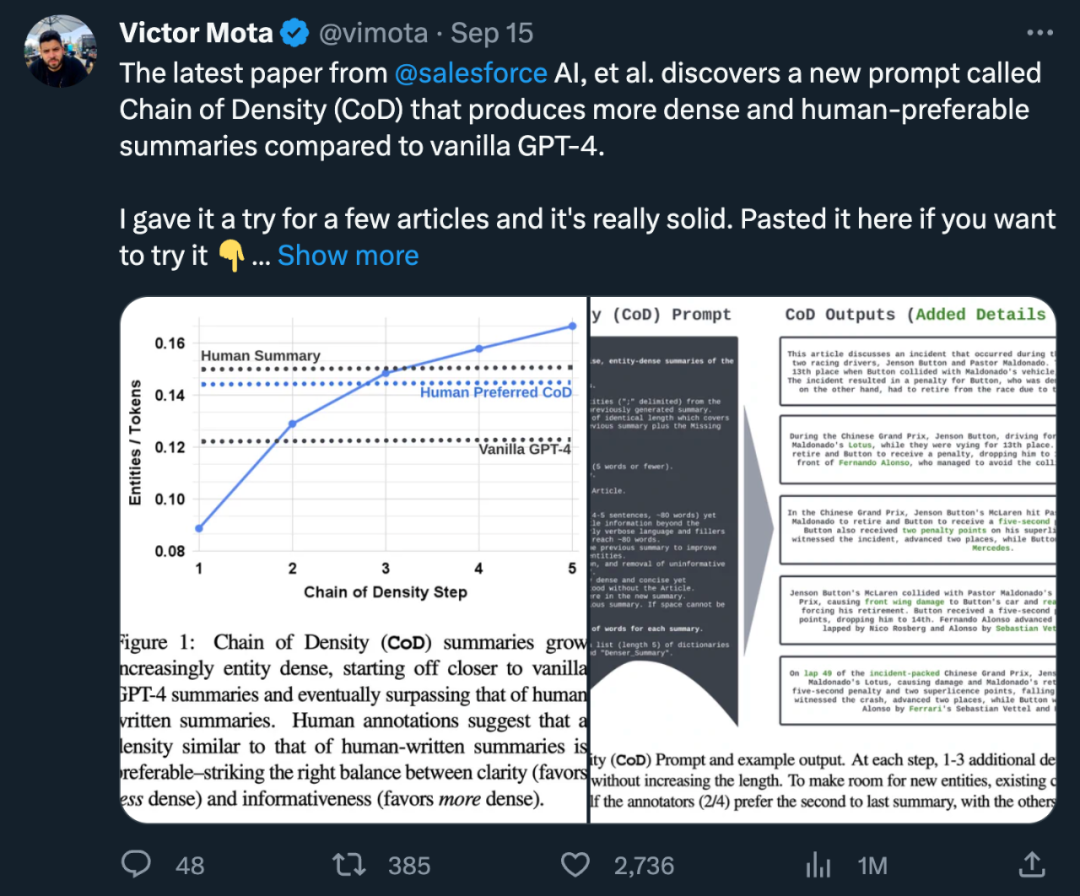
作者設定了一個名為"CoD"(密度鏈)的提示,用於產生初始摘要並逐漸增加其實體密度。具體而言,在固定的交互次數內,源文本中的一組獨特突出實體被識別出來,並在不增加長度的情況下融合到先前的摘要中
在圖2中,展示了Prompt和輸出範例。作者並沒有明確規定實體的類型,而是將缺少的實體定義為:
 具體:描述性的但簡潔(5 個字或更少);
具體:描述性的但簡潔(5 個字或更少);
新穎:未出現在先前的摘要中;
任何地方:位於文章的任何地方。
###########################作者從CNN/DailyMail 摘要測試集中隨機抽取了100 篇文章,為其產生CoD 摘要。為便於參考,他們將CoD 摘要統計數據與人類撰寫的要點式參考摘要以及GPT-4 在普通Prompt 下生成的摘要進行比較:「寫一篇非常簡短的文章摘要。請勿超過70 個字。」 ############統計量############在研究中,作者從直接統計資料和間接統計資料兩方面進行了總結。直接統計資料(token、實體、實體密度)由 CoD 直接控制,而間接統計資料則是密集化的預期副產品。 ######重寫後的內容如下:根據統計數據顯示,透過刪除冗長摘要中的不必要詞語,第二步驟的平均長度減少了5個標記(從72個減少到67個)。初始實體密度為0.089,低於人類和Vanilla GPT-4(0.151和0.122),經過5個密集化步驟後,最終上升至0.167
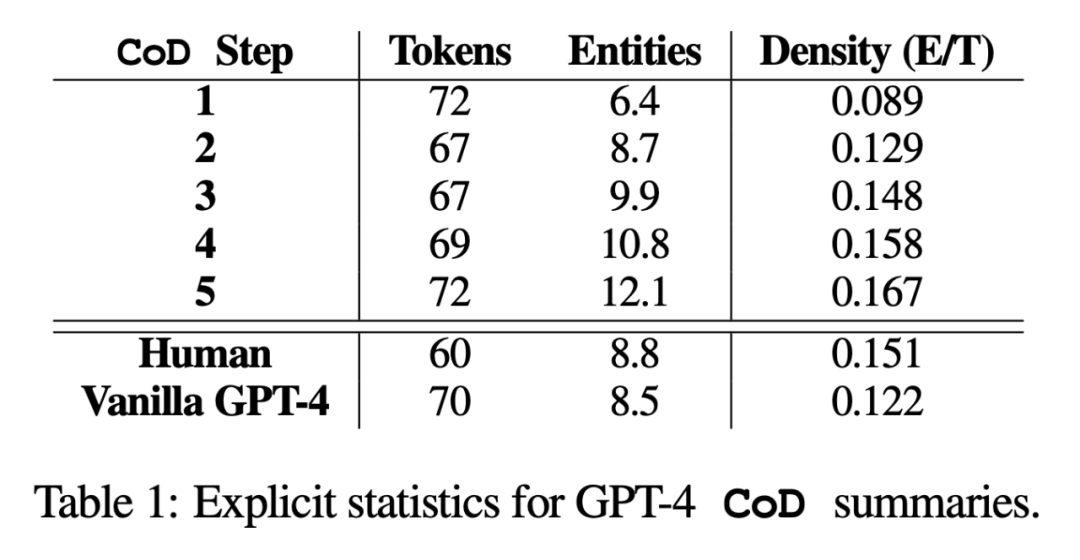
#間接統計。抽象度應該會隨著每一步 CoD 的進行而增加,因為每增加一個實體,摘要就會被反覆改寫以騰出空間。作者以萃取密度來衡量抽象性:萃取片段的平均平方長度 (Grusky et al., 2018)。同樣,隨著實體被添加到固定長度的摘要中,概念融合度也應隨之單調增加。作者用與每個摘要句子對齊的來源句子的平均數量來表示融合度。在對齊上,作者使用相對 ROUGE 增益法 (Zhou et al., 2018),,該方法將源句與目標句對齊,直到額外句子的相對 ROUGE 增益不再為正。他們也預期內容分佈(Content Distribution),也就是摘要內容所來源的文章中位置,會有所改變。
具體來說,作者預期《決勝時刻》(CoD)摘要最初會表現出強烈的「引導偏向」,即在文章的開頭部分會更多地引入實體。然而,隨著文章的發展,這種引導偏向會逐漸減弱,開始從文章的中間和結尾引入實體。為了衡量這一點,研究者使用了融合中的對齊結果,並測量了所有對齊源句的平均句子等級
圖3 證實了這些假設:隨著重寫步驟的增加,抽象性也隨之增加(左側提取密度較低),融合率上升(中圖),摘要開始納入文章中間和末尾的內容(右圖)。有趣的是,與人類撰寫的摘要和基準摘要相比,所有CoD 摘要都更具抽象性
#為了更好地理解CoD摘要的權衡,作者進行了一項基於偏好的人類研究,並利用GPT-4進行了基於評級的評估
人類偏好。具體來說,對於同樣的 100 篇文章(5 個 step *100 = 總共 500 篇摘要),作者向論文的前四位作者隨機展示了經過“重新創作”的 CoD 摘要以及文章。根據 Stiennon et al. (2020) 對「好摘要」的定義,每位註釋者都給出了自己最喜歡的摘要。表 2 報告了各註釋者在 CoD 階段的第一名得票情況,以及各註釋者的總結情況。總的來說,61% 的第一名摘要(23.0 22.5 15.5)涉及≥3 個緻密化步驟。首選 CoD 步數的中位數位於中間(3),預期步數為 3.06。
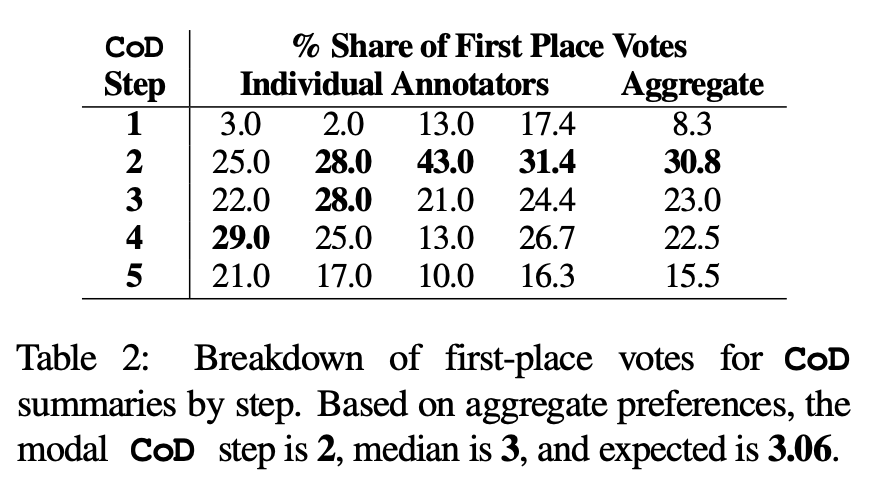
根據Step 3 摘要的平均密度,可以大致推斷所有CoD 候選者的首選實體密度為∼ 0.15 。從表 1 可以看出,此密度與人類所寫的摘要(0.151)一致,但明顯高於以普通 GPT-4 Prompt 所寫的摘要(0.122)。
自動度量。作為人工評估的補充(如下),作者以 GPT-4 從 5 個維度對 CoD 摘要進行評分(1-5 分):資訊量、品質、連貫性、可歸屬性和整體性。如表 3 所示,密集度與資訊量相關,但有一個限度,在步驟 4(4.74)時得分達到頂峰。
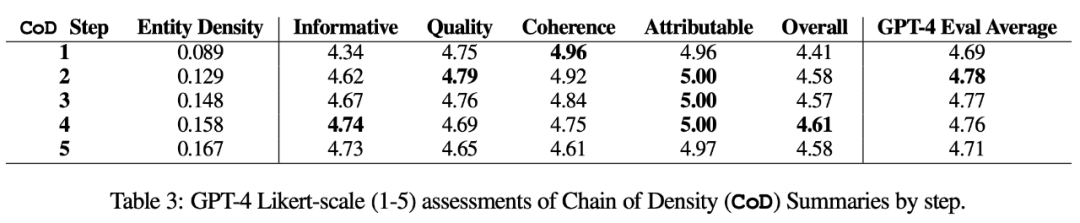
從各維度的平均分數來看,CoD 的第一個和最後一個步驟得分最低,而中間三個步驟得分接近(分別為4.78、4.77 和4.76)。
定性分析。摘要的連貫性 / 可讀性與資訊量之間有明顯的權衡。圖4展示了兩個CoD步驟:一個步驟的摘要因為更多細節而改善,而另一個步驟的摘要則受到了損害。整體而言,中間的CoD摘要能夠實現這種平衡,但這種權衡仍需要在今後的工作中進行精確定義和量化

更多論文細節,可參考原論文。
以上是「字少資訊量大」,Salesforce、MIT 研究者教 GPT-4「改稿」,資料集已開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















