

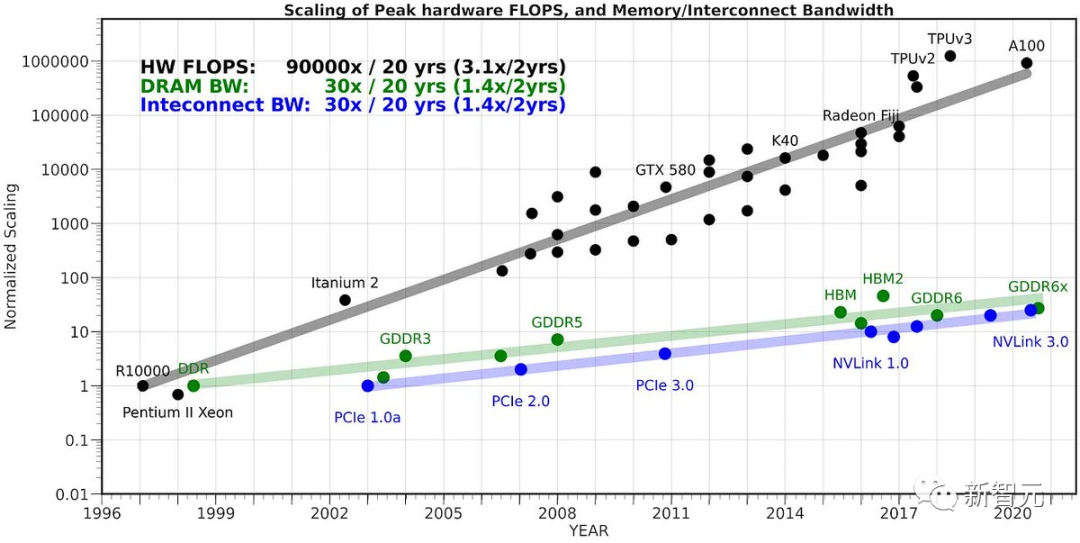
開源社群的一位開發者Georgi Gerganov發現,自己可以在M2 Ultra上運行全F16精度的34B Code Llama模型,而且推理速度超過了20 token/s。
M2 Ultra的頻寬達到了800GB/s,這在其他人通常需要使用4個高階GPU才能實現的情況下
而這背後真正的答案是:投機採樣(Speculative Sampling)。
喬治的發現立刻引發了人工智慧界大佬們的討論
#Karpathy轉發評論道,「LLM的投機執行是一種出色的推理時間優化」。

在這個例子中,Georgi借助Q4 7B quantum草稿模型(也就是Code Llama 7B)進行了投機解碼,然後在M2 Ultra上使用Code Llama34B進行產生。
簡單講,就是用一個「小模型」做草稿,然後用「大模型」來檢查修正,以此加速整個過程。

GitHub地址:https://twitter.com/ggerganov/status/1697262700165013689
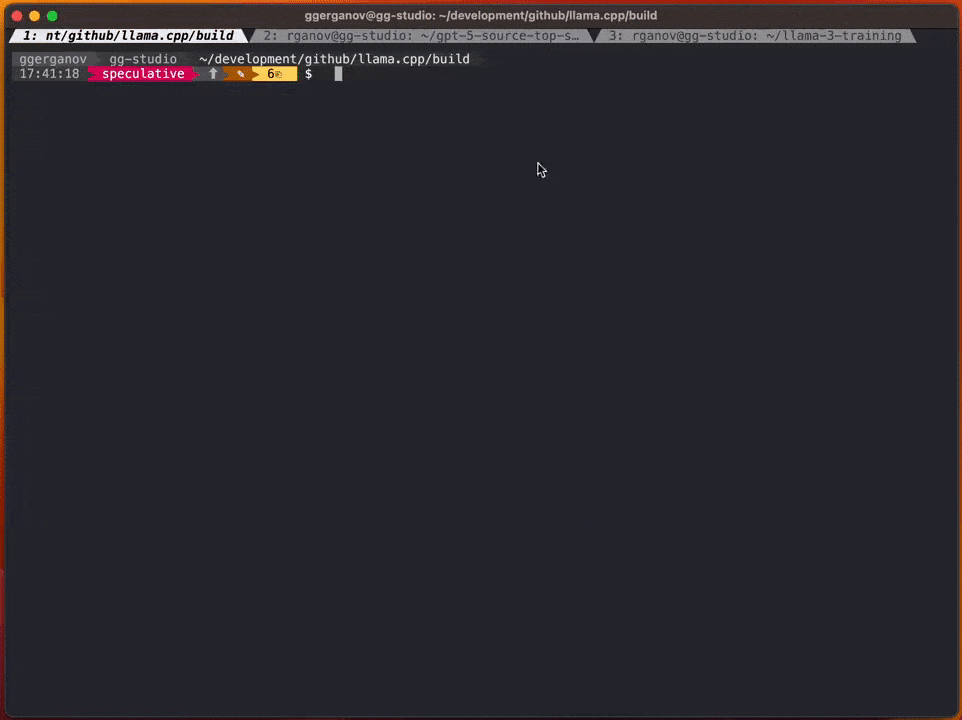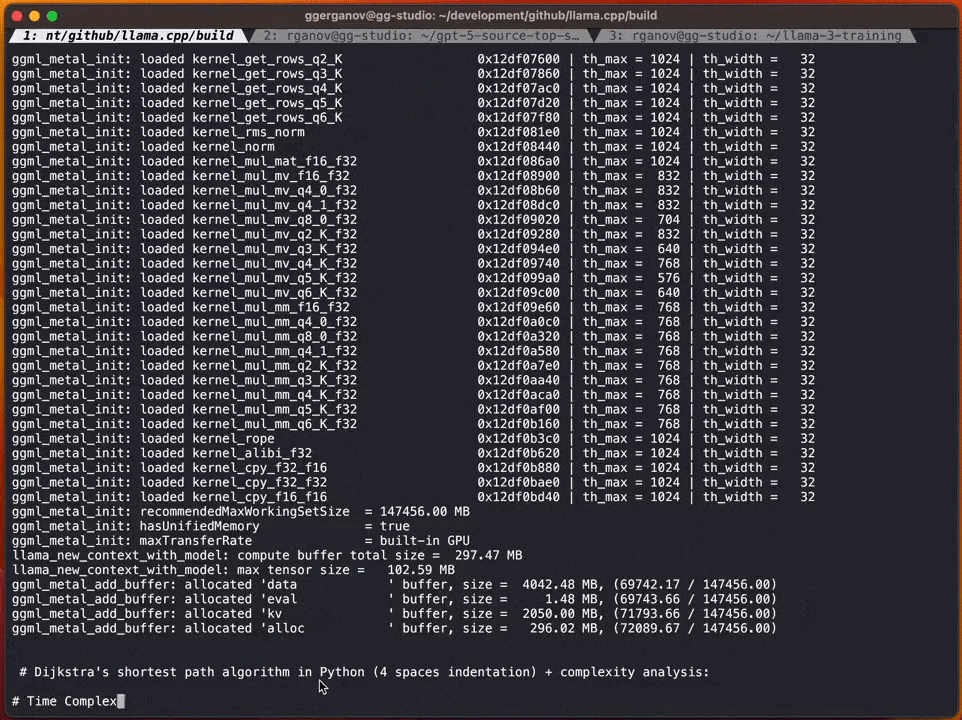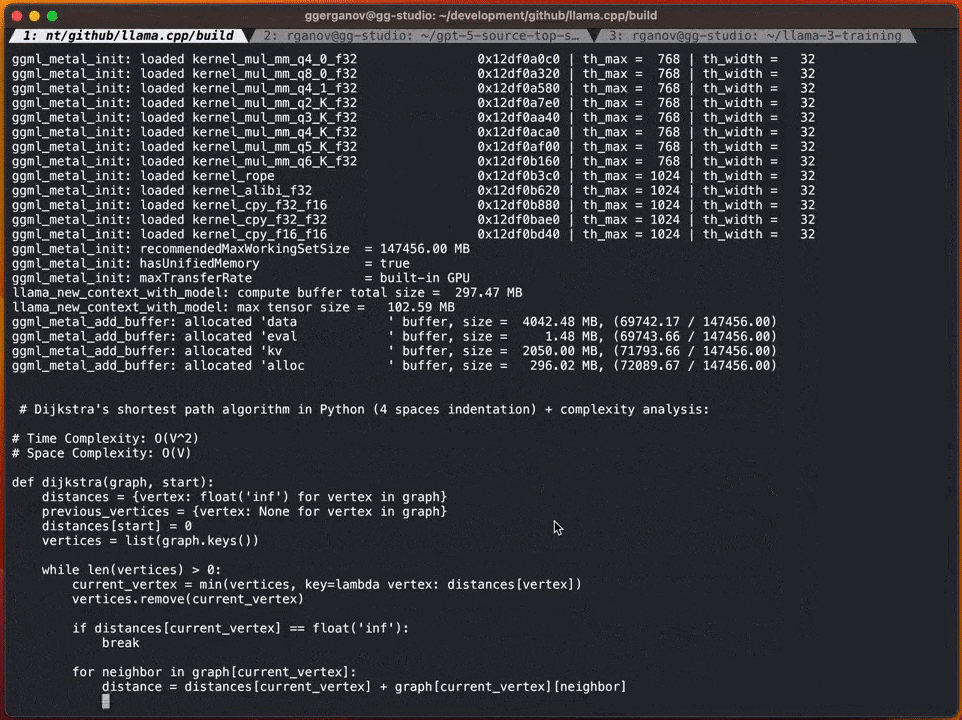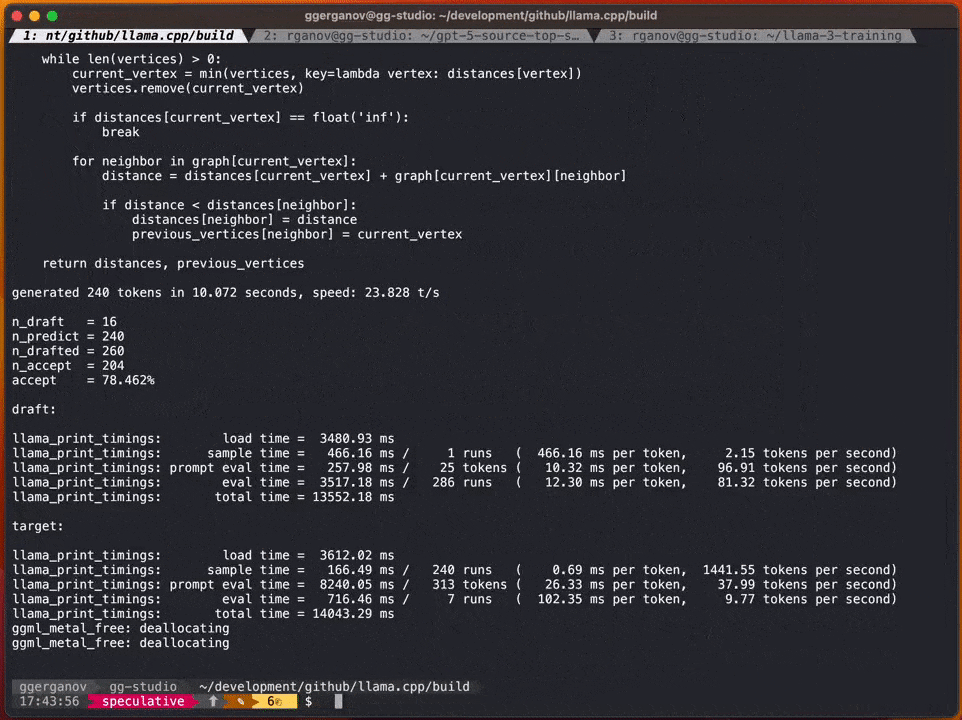
根據Georgi的介紹,這些模型的速度分別如下:
F16 34B:每秒約10個令牌
需要進行改寫的內容是:Q4 7B:每秒約80個令牌
##以下是一個沒有使用投機取樣的標準F16取樣範例:
在加入投機取樣策略之後,速度可以達到每秒約20個標記
根據Georgi的說法,產生內容的速度可能會有所不同。然而,這種方法在程式碼產生方面似乎非常有效,因為大多數詞庫都能被草稿模型正確猜測
#使用「語法取樣」的用例也有可能從中受益匪淺

投機取樣是如何實現快速推理的?
Karpathy根據先前谷歌大腦、UC伯克利、DeepMind的三項研究,做出了解釋。

請點擊以下連結查看論文:https://arxiv.org/pdf/2211.17192.pdf

#論文網址:https://arxiv.org/pdf/1811.03115.pdf

論文網址:https://arxiv.org/pdf/2302.01318.pdf
這取決於以下不直觀的觀察結果:
在單一輸入token上轉發LLM所需的時間,與在K個輸入token上批量轉發LLM所需的時間相同(K比你想像的要大)。
這個不直覺的事實是因為取樣受到記憶體的嚴重限制,大部分「工作」不計算,而是將Transformer的權重從VRAM讀取到晶片上快取進行處理。

#
為了完成讀取所有權重的任務,最好將它們應用於整個批次的輸入向量
我們之所以不能天真地利用這一事實,來一次採樣K個token,是因為每N個token都取決於,我們在第N-1步時採樣的token。這是一種串行依賴關係,因此基線實現只是從左到右逐個進行。
現在,一個巧妙的想法是使用一個小而便宜的草稿模型,首先產生一個由K個標記組成的候選序列-「草稿」。然後,我們將所有這些資訊一起批次送入大模型
根據上述方法,這與只輸入一個token的速度幾乎一樣快。
然後,我們從左到右檢查模型,以及樣本token預測的logits。任何與草稿一致的樣本都允許我們立即跳到下一個token。
如果存在分歧,我們將放棄草稿模型,並承擔進行一些一次性工作的成本(對草稿模型進行採樣,並對後續的標記進行前向傳遞)
這在實踐中行之有效的原因是,大多數情況下,draft token都會被接受,因為是簡單的token,所以即使是更小的草稿模型也能接受它們。
當這些簡單的token被接受時,我們就會跳過這些部分。大模型不同意的困難token會「回落」到原始速度,但實際上因為有額外的工作會慢一些。
所以,總而言之:這怪招之所以管用,是因為LLM在推理時是受記憶體限制。在「批次大小為1」的情況下,對感興趣的單一序列進行取樣,而大部分「本地 LLM」用例都屬於這種情況。而且,大多數token都很「簡單」。
HuggingFace的共同創辦人表示,340億參數的模型在一年半以前的資料中心之外,看起來非常龐大且難以管理。現在只需使用筆記型電腦就可以輕鬆處理了

#現在的LLM並不是單點突破,而是需要多個重要元件有效協同工作的系統。投機解碼就是一個很好的例子,可以幫助我們從系統的角度思考。
以上是不用4個H100!340億參數Code Llama在Mac可跑,每秒20個token,程式碼產生最拿手的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















