

在推動基於視覺的感知方法落地時,提高模型的泛化能力是一個重要的基礎。測試段訓練和適應(Test-Time Training/Adaptation)是透過在測試階段調整模型參數權重,使模型能夠適應未知的目標領域資料分佈。現有的TTT/TTA方法通常著重於提高在封閉環境中的目標域資料下的測試段訓練表現
#然而,在許多應用場景中,目標領域很容易受到強域外資料(Strong OOD )的污染,例如與語意無關的資料類別。在這種情況下,也被稱為開放世界測試段訓練(OWTTT),現有的TTT/TTA通常會將強域外資料強行分類為已知類別,最終幹擾對弱域外資料(Weak OOD)如受到噪音幹擾的圖像的識別能力
最近,華南理工大學和A*STAR團隊首次提出了開放世界測試段訓練的設定,並且推出了相應的訓練方法

論文:https://arxiv.org/abs/2308.09942
需要重寫的內容是:程式碼連結:https: //github.com/Yushu-Li/OWTTT
本文首先提出了一種自適應閾值的強域外資料樣本過濾方法,提高了自訓練TTT 方法的在開放世界的魯棒性。該方法進一步提出了一種基於動態擴展原型來表徵強域外樣本的方法,以改善弱 / 強域外資料分離效果。最後,透過分佈對齊來約束自訓練。
本文的方法在 5 個不同的 OWTTT 基準上實現了最優的性能表現,並為 TTT 的後續研究探索面向更加魯棒 TTT 方法的提供了新方向。研究已作為 Oral 論文被 ICCV 2023 接收。
引言
測試段訓練(TTT)可以僅在推理階段存取目標域數據,並對分佈偏移的測試數據進行即時推理。 TTT 的成功已經在許多人工選擇的合成損壞目標域數據上得到證明。然而,現有的 TTT 方法的能力邊界尚未得到充分探索。
為促進開放場景下的 TTT 應用,研究的重點已轉移到調查 TTT 方法可能失敗的場景。人們在更現實的開放世界環境下開發穩定和強大的 TTT 方法已經做出了許多努力。而在本文工作中,我們深入研究了一個很常見但被忽略的開放世界場景,其中目標域可能包含從顯著不同的環境中提取的測試資料分佈,例如與源域不同的語義類別,或者只是隨機噪音。
我們將上述測試資料稱為強分佈外資料(strong OOD)。而在本工作中稱為弱 OOD 數據則是分佈偏移的測試數據,例如常見的合成損壞。因此,現有工作缺乏對這種現實環境的研究促使我們探索提高開放世界測試段訓練(OWTTT)的穩健性,其中測試數據被強OOD 樣本污染
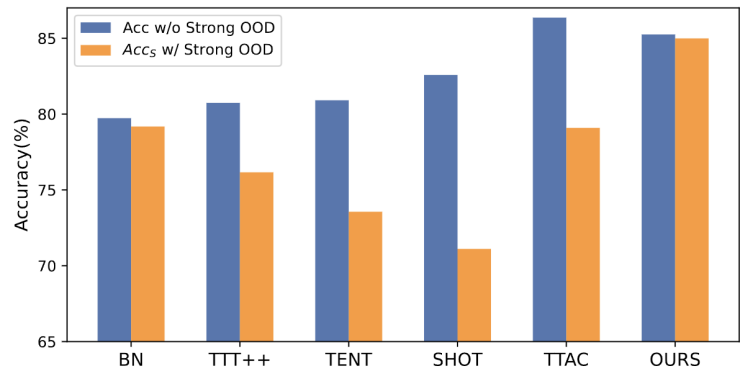
需要重寫的內容是:圖1:在OWTTT設定下,對現有的TTT方法進行評估的結果
根據圖1所示,我們首先對現有的OWTTT設定下的TTT方法進行了評估,發現透過自訓練和分佈對齊的TTT方法都會受到強OOD樣本的影響。這些結果表明,在開放世界中應用現有的TTT技術無法實現安全的測試訓練。我們將它們的失敗歸因於以下兩個原因
基於自訓練的 TTT 很難處理強 OOD 樣本,因為它必須將測試樣本分配給已知的類別。儘管可以透過應用半監督學習中採用的閾值來過濾掉一些低置信度樣本,但仍不能保證濾除所有強 OOD 樣本。
當計算強 OOD 樣本來估計目標域分佈時,基於分佈對齊的方法將會受到影響。全域分佈對齊 [1] 和類別分佈對齊 [2] 都可能受到影響,並導致特徵分佈對齊不準確。
為了提高自訓練框架下開放世界TTT 的穩健性,我們考慮了現有TTT 方法失敗的潛在原因,並提出了兩種技術相結合的解決方案
首先,我們將在自訓練的變體上建立TTT的基線,即在目標域中使用源域原型作為聚類中心進行聚類。為了減輕自訓練受到錯誤偽標籤的強OOD影響,我們提出了一種無超參數的方法來拒絕強OOD樣本
為了進一步分離弱OOD 樣本和強OOD 樣本的特徵,我們允許原型池透過選擇孤立的強OOD 樣本擴展。因此,自訓練將允許強 OOD 樣本圍繞新擴展的強 OOD 原型形成緊密的聚類。這將有利於源域和目標域之間的分佈對齊。我們進一步提出透過全域分佈對齊來規範自我訓練,以降低確認偏誤的風險
最後,為了綜合開放世界的TTT 場景,我們採用CIFAR10-C、CIFAR100-C、ImageNet-C、VisDA-C、ImageNet-R、Tiny-ImageNet、MNIST 和SVHN 資料集,並透過利用一個資料集為弱OOD,其他為強OOD 建立基準資料集。我們將此基準稱為開放世界測試段訓練基準,並希望這能鼓勵未來更多的工作關注更現實場景中測試段訓練的穩健性。
方法
論文分了四個部分來介紹所提出的方法。
1)概述開放世界下測試段落訓練任務的設定。
2)介紹如何透過原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式識別和影像處理等領域中廣泛應用實現 TTT 以及如何擴展原型以進行開放世界測試時訓練。
3)介紹如何利用目標域資料進行需要進行重寫的內容是:動態原型擴充。
4)引入分佈對齊與原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式識別和影像處理等領域廣泛應用相結合,以實現強大的開放世界測試時訓練。
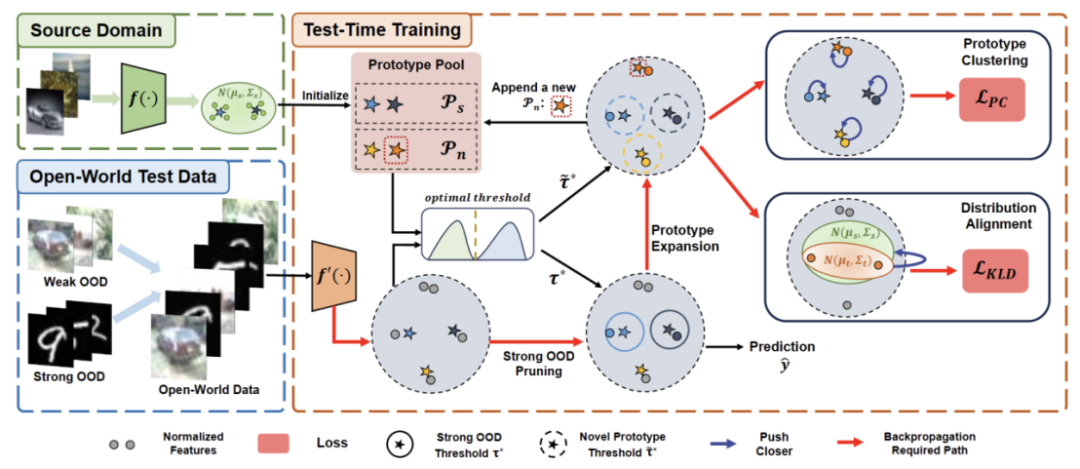
需要重新寫作的內容是:圖2:方法概覽圖
任務設定
TTT的目標是使源域預訓練模型適應目標域,其中目標域可能相對於源域存在分佈遷移。在標準的封閉世界TTT中,源域和目標域的標籤空間是相同的。然而,在開放世界TTT中,目標域的標籤空間包含源域的目標空間,也就是說目標域具有未見過的新語意類別
為了避免TTT 定義之間的混淆,我們採用TTAC [2] 中提出的順序測試時間訓練(sTTT)協定進行評估。在 sTTT 協議下,測試樣本被順序測試,並在觀察到小批量測試樣本後進行模型更新。到達時間戳記 t 的任何測試樣本的預測不會受到任何到達 t k(其 k 大於 0)的測試樣本的影響。
原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式辨識和影像處理等領域中廣泛應用
受到域適應任務中使用聚類的工作啟發[3,4],我們將測試段訓練視為發現目標域資料中的簇結構。透過將代表性原型識別為聚類中心,在目標域中識別聚類結構,並鼓勵測試樣本嵌入到其中一個原型附近。原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式辨識和影像處理等領域廣泛應用的目標定義為最小化樣本與聚類中心餘弦相似度的負對數似然損失,如下式所示。
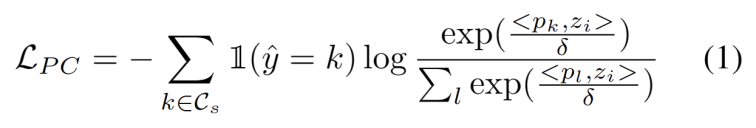
我們發展了一個無超參數的方法來濾除強 OOD 樣本,以避免調整模型權重的負面影響。具體來說,我們為每個測試樣本定義一個強 OOD 分數 os 作為與源域原型的最高相似度,如下式所示。
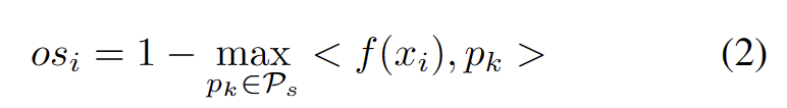
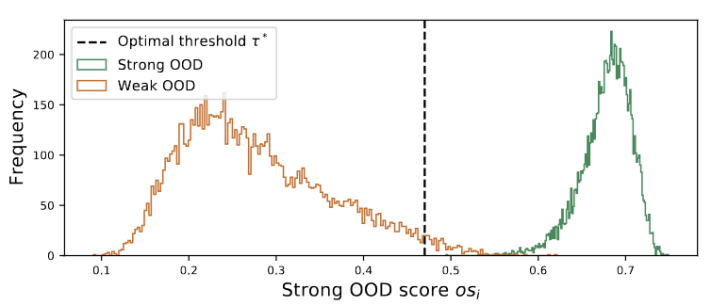
圖3 離群值呈雙峰分佈
我們觀察到離群值服從雙峰分佈,如圖3 所示。因此,我們沒有指定固定閾值,而是將最佳閾值定義為分離兩種分佈的最佳值。具體來說,問題可以表述為將離群值分為兩個簇,最佳閾值將最小化中的簇內方差。最佳化下式可以透過以 0.01 的步長窮舉搜尋從 0 到 1 的所有可能閾值來有效實現。
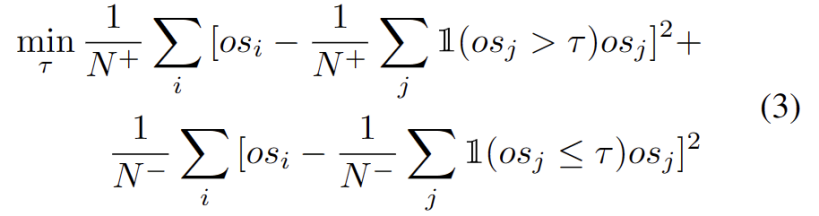
需要進行重寫的內容是:動態原型擴展
擴展強OOD 原型池需要同時考慮源域和強OOD 原型來評估測試樣本。為了從數據中動態估計簇的數量,先前的研究了類似的問題。確定性硬聚類演算法 DP-means [5] 是透過測量資料點到已知聚類中心的距離而開發的,當距離高於閾值時將初始化一個新聚類。 DP-means 已被證明相當於優化 K-means 目標,但對簇的數量有額外的懲罰,為需要重寫的內容是:動態原型擴展提供了一個可行的解決方案。
為了減輕估計額外超參數的難度,我們首先定義一個測試樣本,其具有擴展的強 OOD 分數作為與現有源域原型和強 OOD 原型的最近距離,如下式。因此,測試高於此閾值的樣本將建立一個新的原型。為了避免添加附近的測試樣本,我們增量地重複此原型擴展過程。
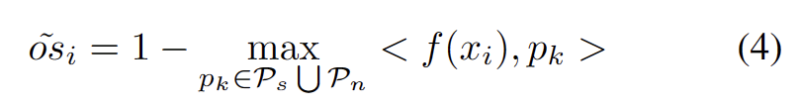
隨著其他強OOD 原型的確定,我們定義了用於測試樣本的原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式識別和影像處理等領域廣泛應用損失,並考慮了兩個因素。首先,分類為已知類別的測試樣本應該嵌入到更靠近原型的位置並遠離其他原型,這定義了 K 類分類任務。其次,被分類為強 OOD 原型的測試樣本應該遠離任何源域原型,這定義了 K 1 類分類任務。考慮到這些目標,我們將原型聚類是一種無監督學習演算法,用於將資料集中的樣本聚類成不同的類別。在原型聚類中,每個類別由一個或多個原型表示,這些原型可以是資料集中的樣本或根據某種規則生成的。原型聚類的目標是透過最小化樣本與其所屬類別原型之間的距離來實現聚類。常見的原型聚類演算法包括K均值聚類和高斯混合模型。這些演算法在資料探勘、模式識別和影像處理等領域中廣泛應用損失定義為下式。
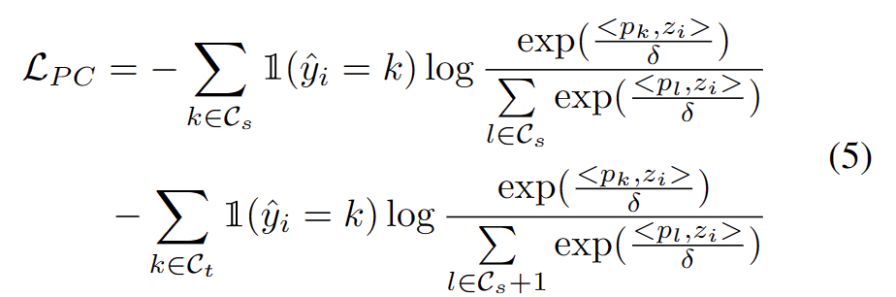
分佈對齊約束
眾所周知,自訓練容易受到錯誤偽標籤的影響。目標域由 OOD 樣本組成時,情況會更加惡化。為了降低失敗的風險,我們進一步將分佈對齊 [1] 作為自我訓練的正規化,如下式。
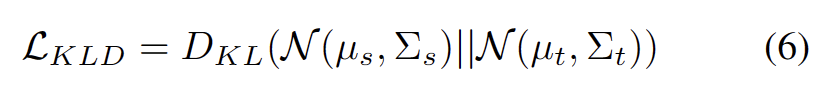


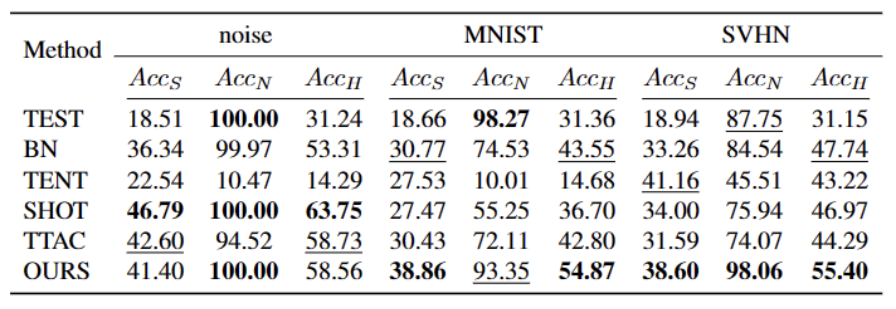
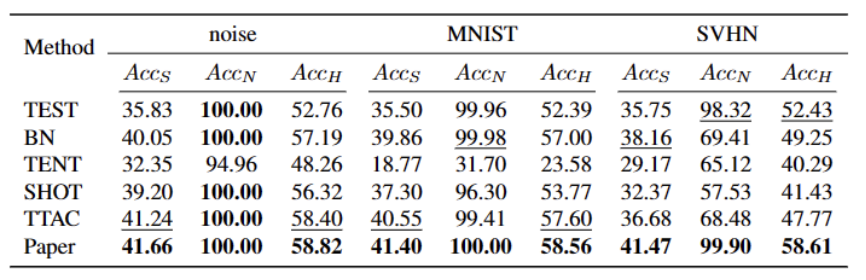
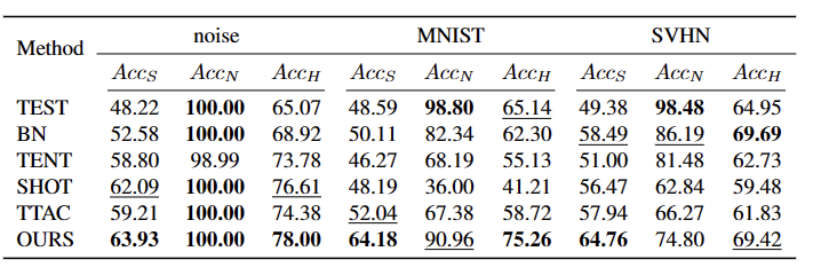 如上表所示,我們的方法在幾乎所有資料集上相較於目前最優秀的方法都有比較大的提升,可以有效地識別強OOD 樣本,並減小其對弱OOD 樣本分類的影響。我們的方法可以在開放世界的場景下實現更穩健的 TTT。
如上表所示,我們的方法在幾乎所有資料集上相較於目前最優秀的方法都有比較大的提升,可以有效地識別強OOD 樣本,並減小其對弱OOD 樣本分類的影響。我們的方法可以在開放世界的場景下實現更穩健的 TTT。 [1] Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt : When does self-supervised test-time training fail or thrive? In Advances in Neural Information Processing Systems, 2021.
[2] Yongyi Su, Xun Xu, and Kui Jia.##[2] Yongyi Su, Xun Xu, and Kui Jia.
##[2] Yongyi Su, Xun Xu, and Kui Jia.##[2] Yongyi Su, Xun Xu, and Kui Jia.
##[2] Yongyi Su, Xun Xu, and Kui Jia.##[2] Yongyi Su, Xun Xu, and Kui Jia.
##[2] Yongyi Su, Xun Xu, and Kui Jia.##[2] Yongyi Su, Xun realistic test-time training: Sequential inference and adaptation by anchored clustering. In Advances in Neural Information Processing Systems, 2022.
[3] 唐輝和賈奎。區分性對抗域適應。在人工智慧AAAI會議論文集中,卷34,頁5940-5947,2020年
[4] Kuniaki Saito, Shohei Yamamoto, Yoshitaka Ushiku, and Tatsuya Harada. Open set domain adaptation by backpropagation. In European Conference on Computer Vision, 2018.
######[5] Brian Kulis和Michael I Jordan。重新審視k-means:透過貝葉斯非參數方法的新演算法。在機器學習國際會議上,2012年######以上是ICCV 2023 Oral | 如何在開放世界進行測試段訓練?基於動態原型擴展的自訓練方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!


![PHP實戰開發極速入門: PHP快速創建[小型商業論壇]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)



















