


首先介紹知識圖譜的一些基礎概念。
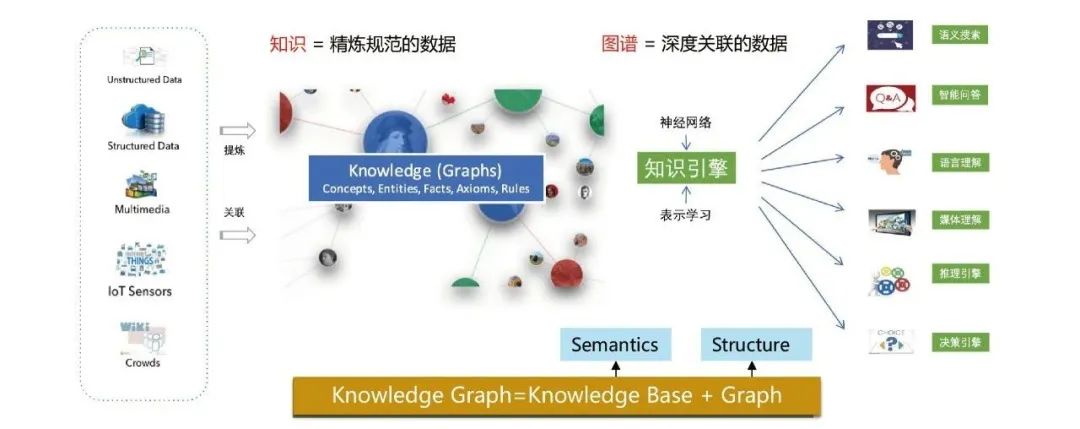
#知識圖譜旨在利用圖結構建模、辨識與推論事物之間的複雜關聯關係與沉澱領域知識,是實現認知智慧的重要基石, 已廣泛應用於搜尋引擎、智慧問答、語言語意理解、大數據決策分析等眾多領域。
知識圖譜同時建模了資料之間的語意關係和結構關係,結合深度學習技術可以把這兩者關係更好得融合和表徵。
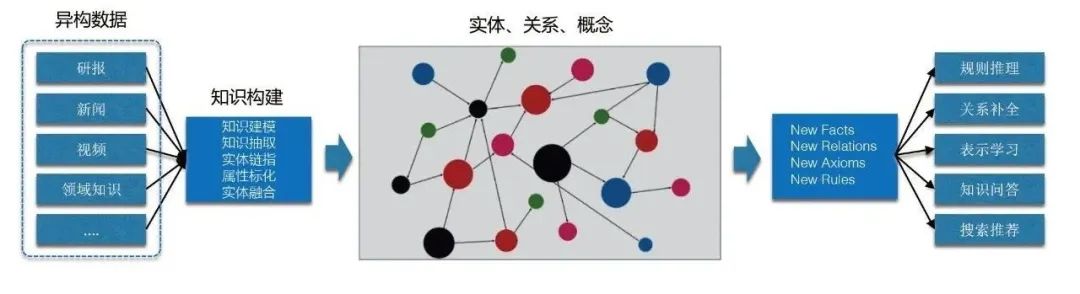
#我們要建立知識圖譜主要從如下兩點出發考慮:一方面是螞蟻本身的資料來源背景特點,另一方面是知識圖譜能帶來的好處。
[1] 資料來源本身是多元且異質的,缺乏一套統一的知識理解系統。
[2] 知識圖譜能帶來多個好處,包括:
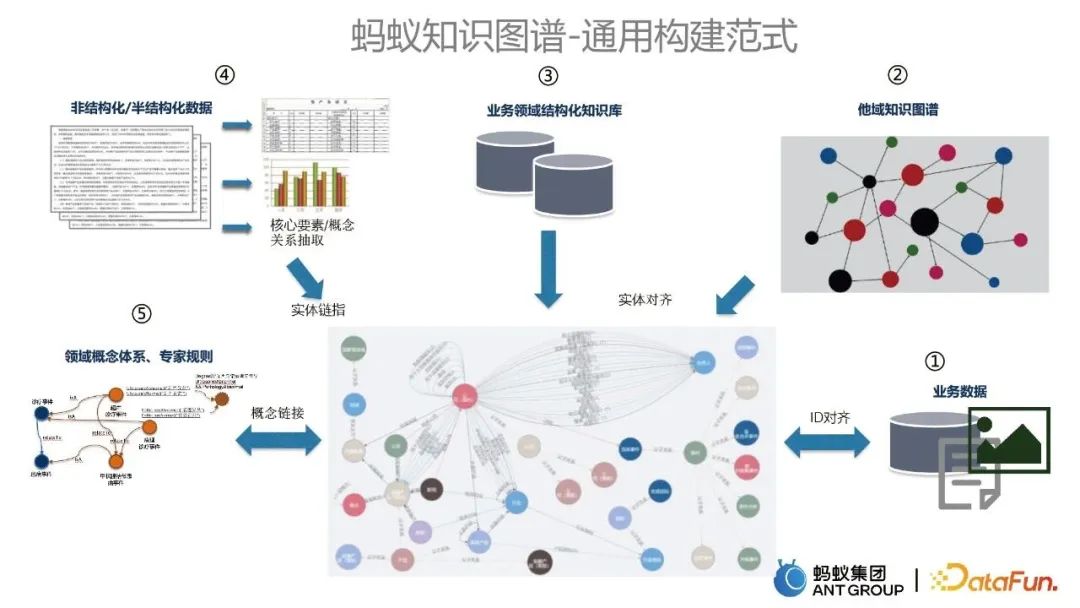
#在建構各類業務知識圖譜的過程中,我們沉澱出了一套螞蟻知識圖譜的通用建構範式,主要分為如下五個部分:
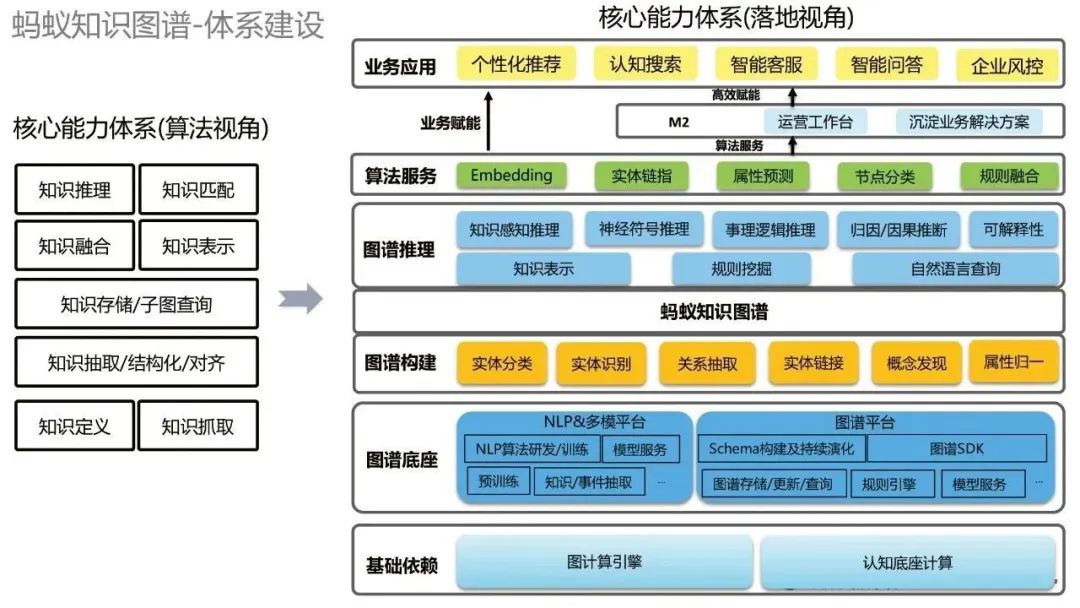
有了通用的建構範式後,就需要進行體系化的建構。從兩個視角來看螞蟻知識圖譜的體系化建構。首先是從演算法角度來看,有各種演算法能力,例如知識推理、知識匹配等等。從落地視角來看,自下而上,最下面的基礎依賴包括圖計算引擎和認知底座計算;其上是圖譜底座,包括NLP&多模平台以及圖譜平台;往上是各種圖譜構建技術,基於此我們就可以建立螞蟻知識圖譜;在知識圖譜的基礎上,我們可以做一些圖譜推理;再往上,我們提供一些通用的演算法能力;最上面是業務應用。
二、圖譜建構接下來分享螞蟻集團建構知識圖譜的一些核心能力,包括圖譜建構、圖譜融合、圖譜認知三個面向。
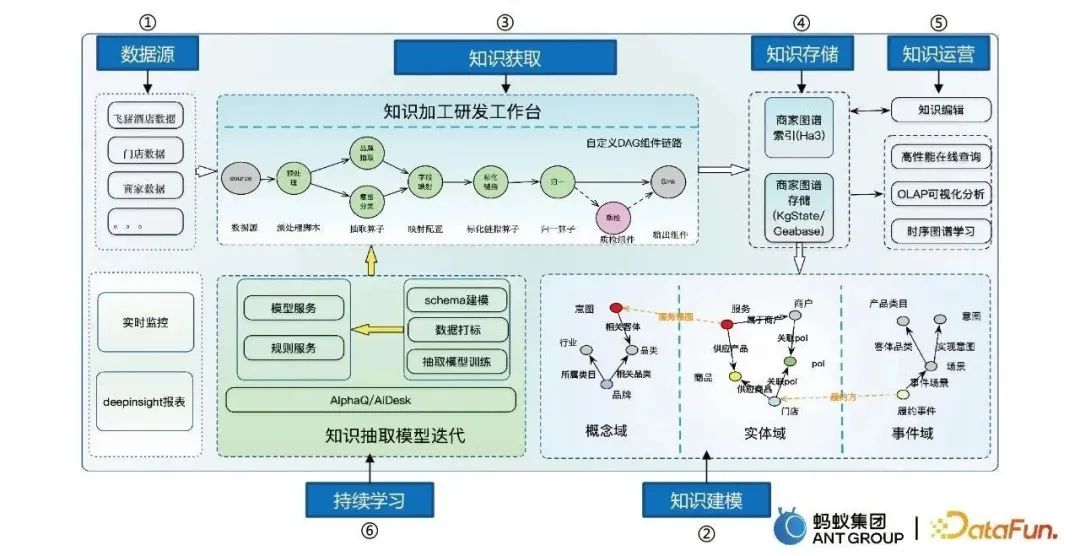
圖譜建構的流程主要包括六個步驟:
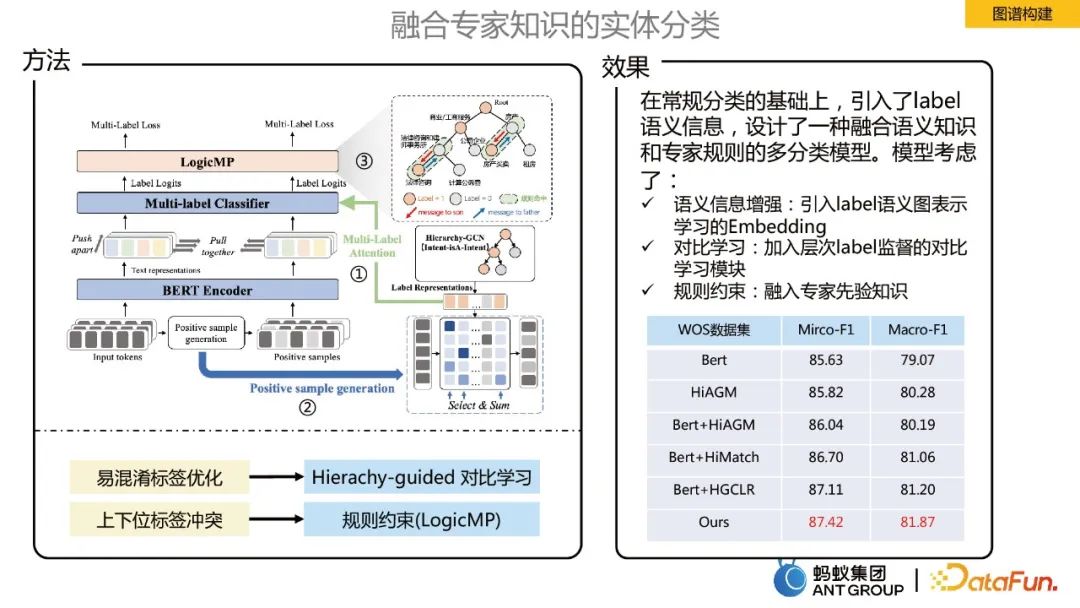
#在建立知識圖譜中,需要對輸入的實體進行分類,在螞蟻場景下是一個大規模多標籤分類的任務。為了融合專家知識來進行實體分類,主要做如下三點最佳化:
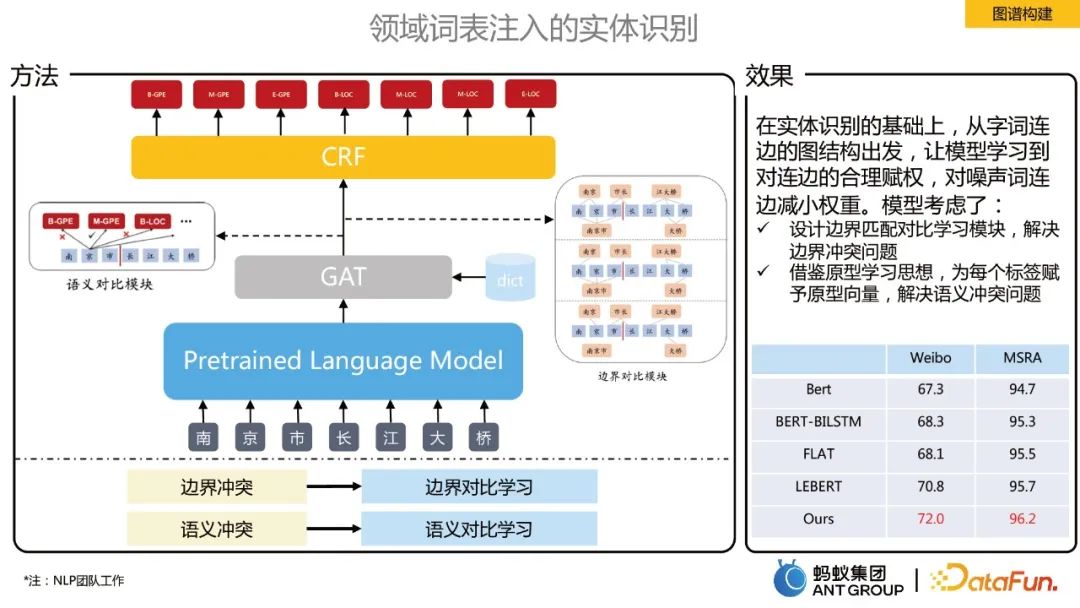
#在實體辨識的基礎上,從字詞連邊的圖結構出發,讓模型學習到對連邊的合理賦權,對噪音詞連邊減少權重。提出了邊界對比學習和語意對比學習兩個模組:
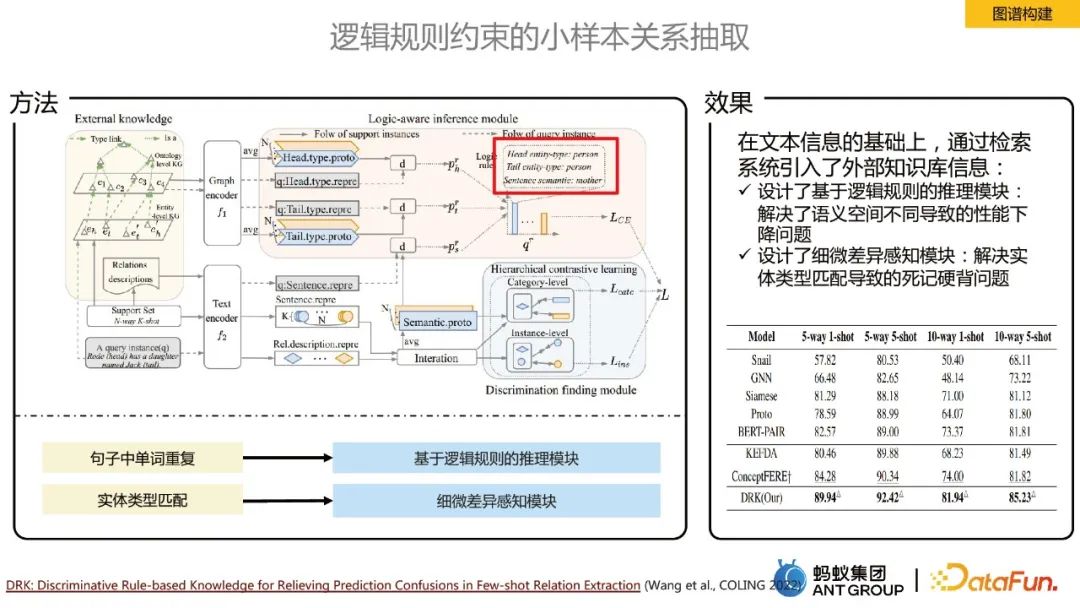
#在領域問題上我們的標註樣本很少,會面臨few-shot或zero-shot的場景,在這種情況下進行關係抽取的核心思想就是引入外部知識庫,為了解決語義空間不同導致的性能下降問題,設計了基於邏輯規則的推理模組;為了解決實體類型匹配導致的死記硬背問題,設計了細微差異感知模組。
圖譜融合是指不同業務領域下圖譜之間的資訊融合。
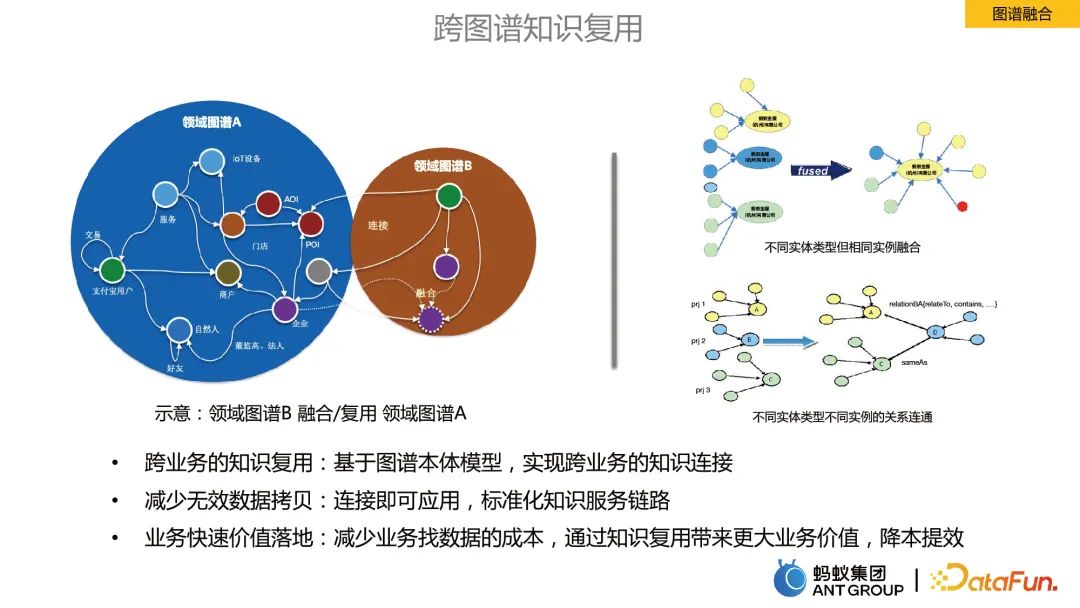
圖譜融合的好處:
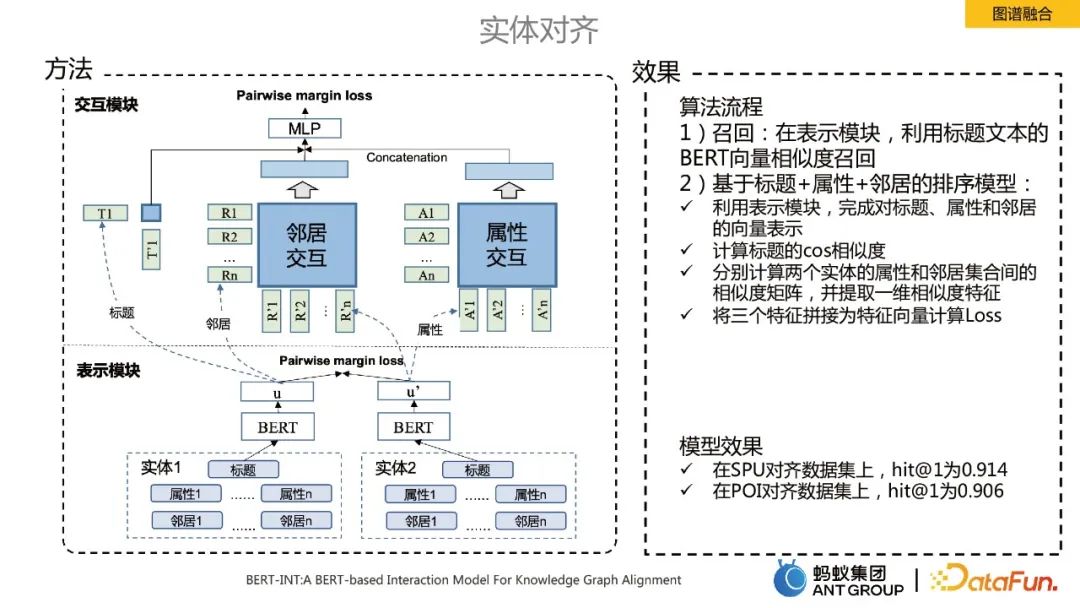
知識圖譜融合過程中一個核心技術點就是實體對齊,這裡我們採用了SOTA演算法BERT-INT,主要包含兩個模組,一個是表示模組,另一個是互動模組。
演算法的實作流程主要包括召回和排序:
#回想:在表示模組,利用標題文字的BERT向量相似度召回。
基於標題屬性鄰居的排序模型:ü 利用表示模組,完成對標題、屬性和鄰居的向量表示:
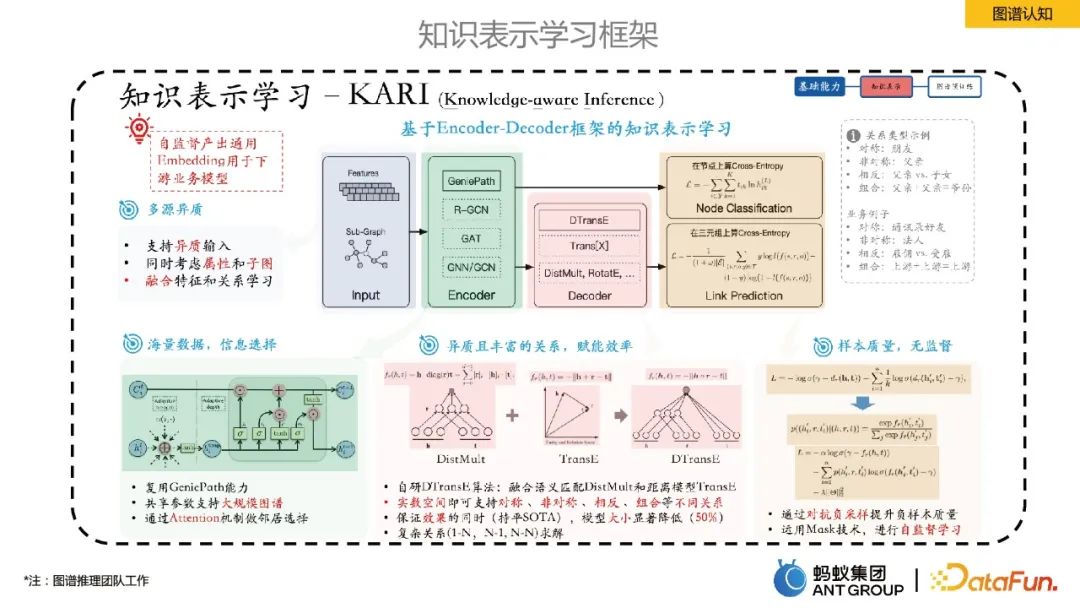
#這部分,主要介紹螞蟻內部的知識表示學習框架。
螞蟻提出了一個基於Encoder-Decoder框架的知識表示學習。其中Encoder是一些圖神經的學習方法,Decoder是一些知識表示的學習,例如連結預測。這套表示學習框架可以自監督產出通用的實體/關係Embedding,有幾個好處:1)Embedding Size遠小於原始特徵空間,降低了儲存成本;2)低維向量更稠密,有效緩解資料稀疏問題;3)同一向量空間學習,對多源異質資料的融合更自然;4)Embedding具有一定的普適性,方便下游業務使用。
接下來分享幾個在螞蟻群組中知識圖譜的典型應用案例。
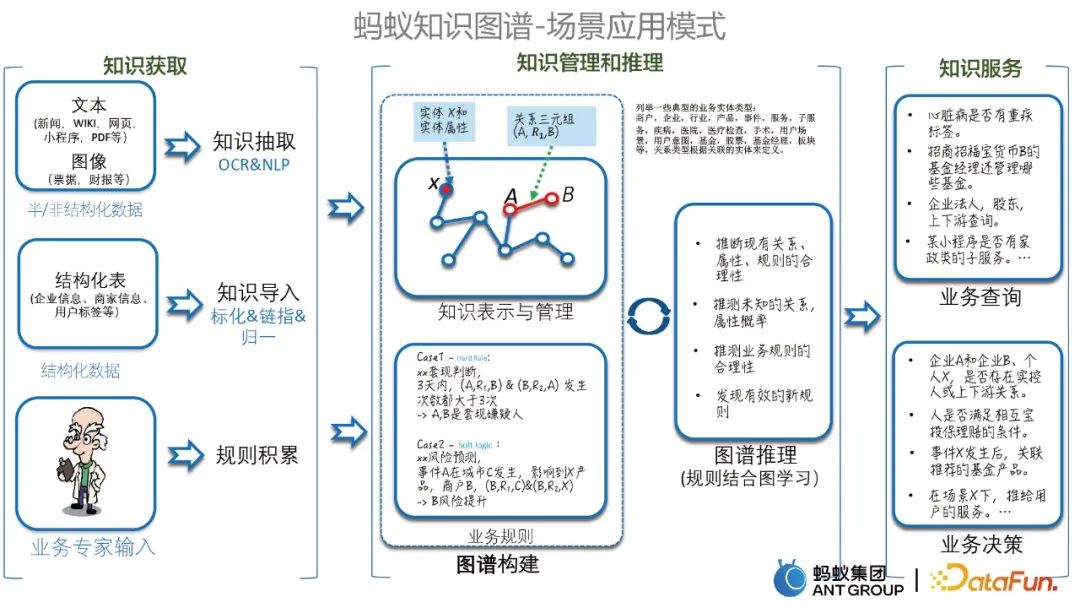
在介紹具體案例前,先來介紹一下螞蟻知識圖譜場景應用的幾種模式,主要包括知識獲取、知識管理和推理,以及知識服務。如下圖所示。
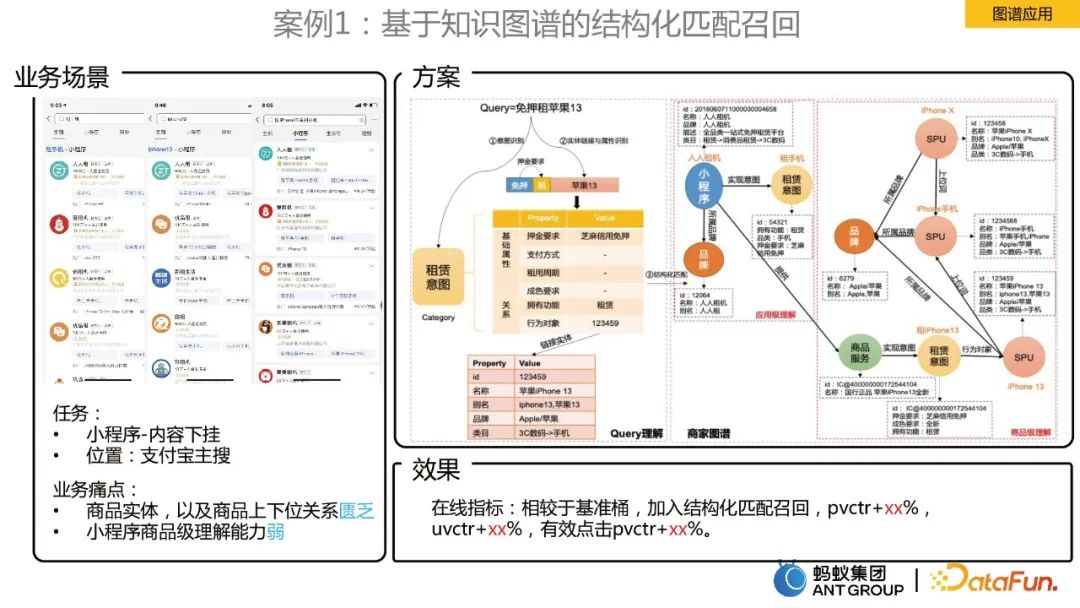
業務場景是支付寶主搜裡面的小程式的內容下掛,要解決的業務痛點是:
解決方案是,建立了商家知識圖譜。結合商家圖譜的商品關係,實現對使用者query商品層級的結構化理解。
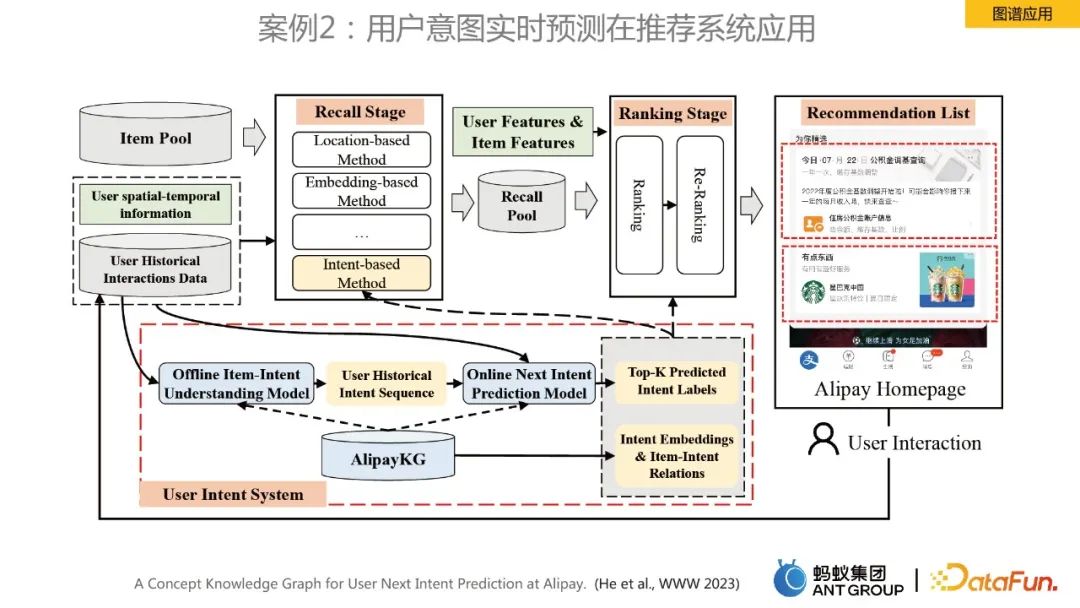
#此案例是針對首頁推薦進行使用者意圖即時預測,建構了AlipayKG,框架如上圖所示。相關工作也發表在頂會www 2023上,可以參考論文做更進一步的理解。
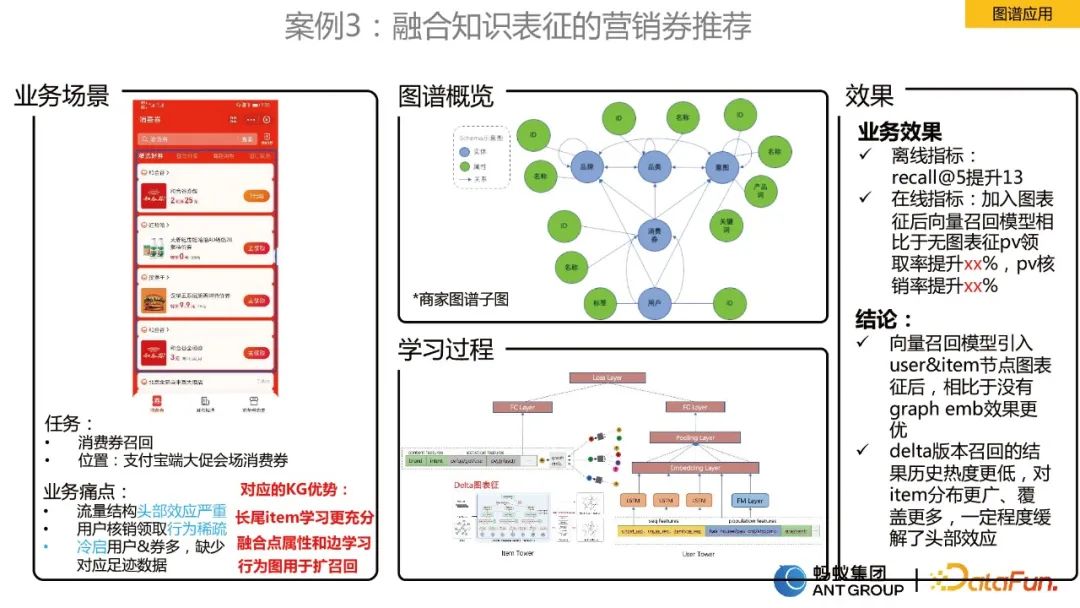
#這個場景是消費券推薦的一個場景,業務面臨的痛點為:
為了解決上述問題,我們設計了融合動態圖表徵的深度向量召回演算法。因為我們發現使用者消費券的行為是有週期性的,靜態的單一邊是無法建模這種週期性行為的。為此我們先建構了動態圖,接著採用團隊自研的動態圖演算法來學習Embedding表徵,得到表徵之後再放到雙塔模型中去,進行向量召回。
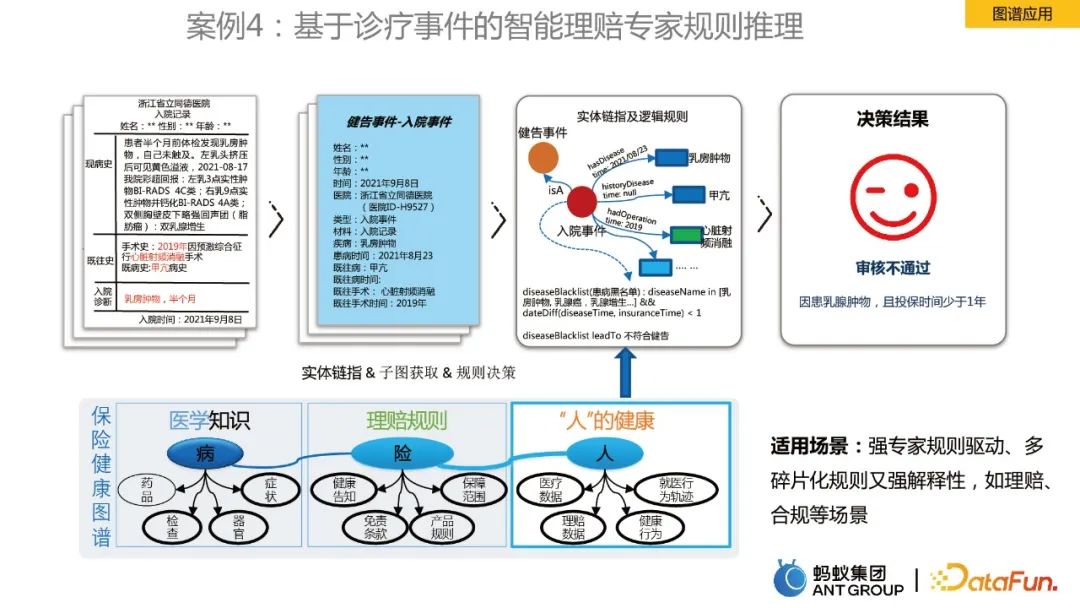
#最後一個案例是關於圖譜規則推理。以醫療保險健康圖譜為例,包括醫學知識、理賠規則、「人」的健康的信息,進行實體鏈指,再加上邏輯規則,來作為決策的依據。透過圖譜實現了專家理賠效率的提升。
最後簡單探討在目前大模型快速發展的脈絡下知識圖譜的機會。
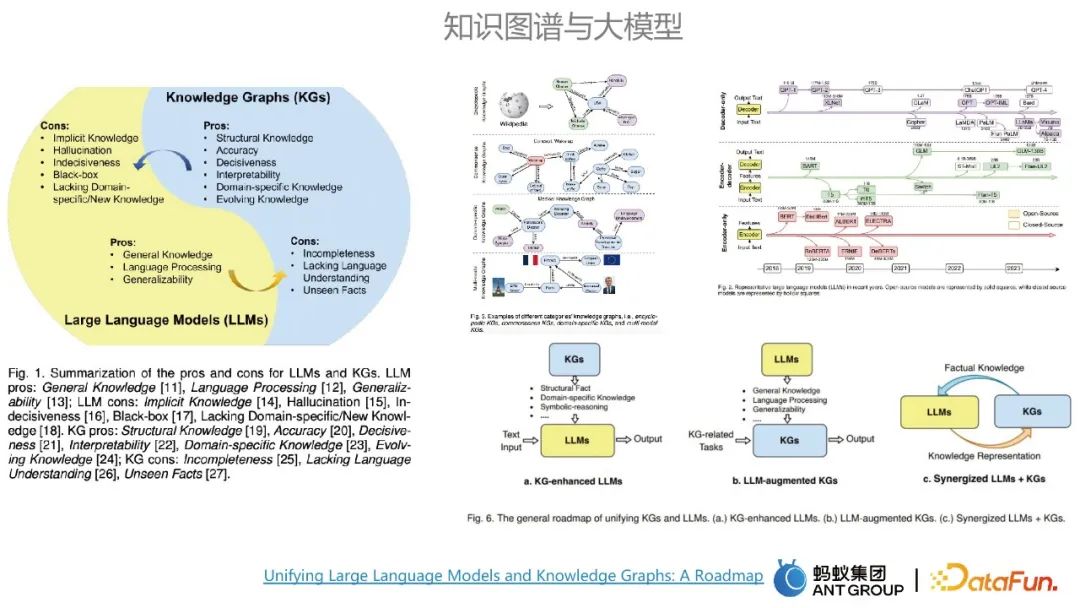
#知識圖與大模型各有優缺點,大模型的主要有通用知識建模和普適性等優點,而大模型的缺點正好是知識圖譜的優點所能彌補的。圖譜的優點包括準確度很高、可解釋性強等。大模型和知識圖譜是能夠相互影響的。
圖譜和大模型的融合通常有三種路線,一種是利用知識圖譜來增強大模型;第二種是利用大模型來增強知識圖譜;第三種是大模型和知識圖譜協同並進,優勢互補,大模型可以認為是一種參數化的知識庫,知識圖譜可以認為是一種顯示化的知識庫。
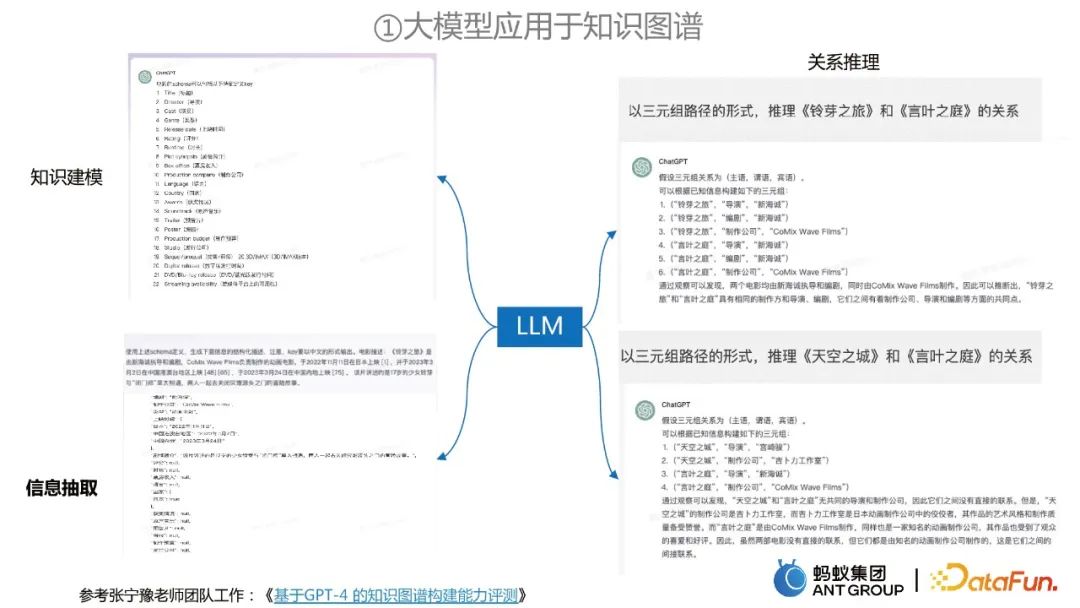
在知識圖譜建構的過程中,可以利用大模型來進行資訊擷取、知識建模和關係推理。

#Dendmon的這個工作將資訊擷取問題分解成了兩個階段:
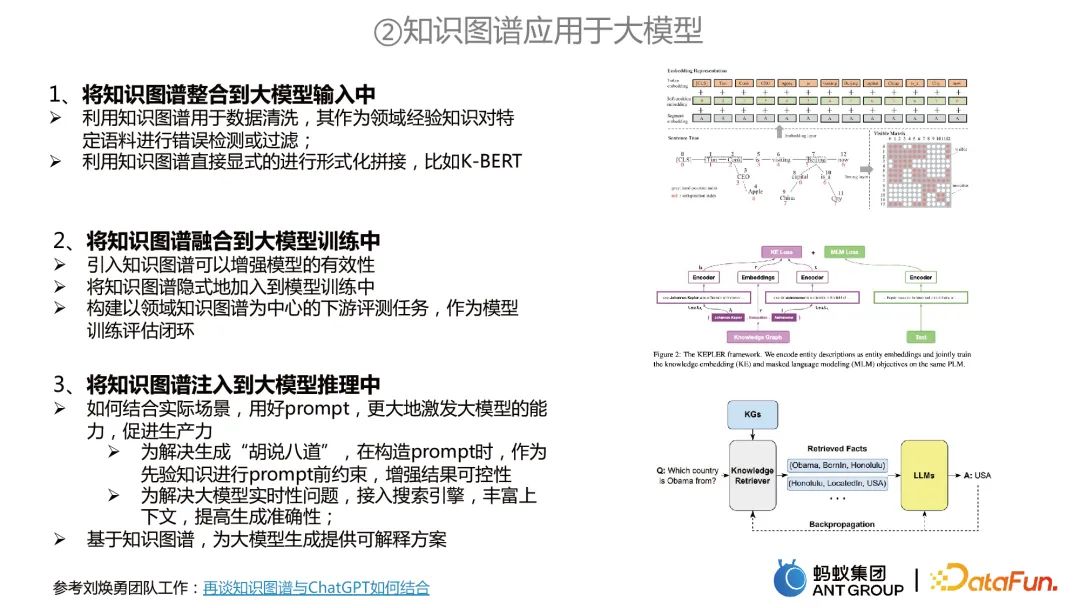
#將知識圖譜應用於大模型主要包含三個面向:
將知識圖譜整合到大模型輸入中。可以利用知識圖譜來進行資料清洗,或利用知識圖譜直接明確地進行形式化拼接。
將知識圖譜整合到大模型訓練中。例如同時進行兩個任務的訓練,知識圖譜可以做知識表示的任務,大模型做MLM的預訓練,兩者聯合建模。
將知識圖譜注入大模型推理中。首先可以解決大模型的兩個問題,一是將知識圖譜作為先驗約束,來避免大模型「胡說八道」;第二就是解決大模型時效性問題。另一方面,基於知識圖譜,可以為大模型產生提供可解釋方案。
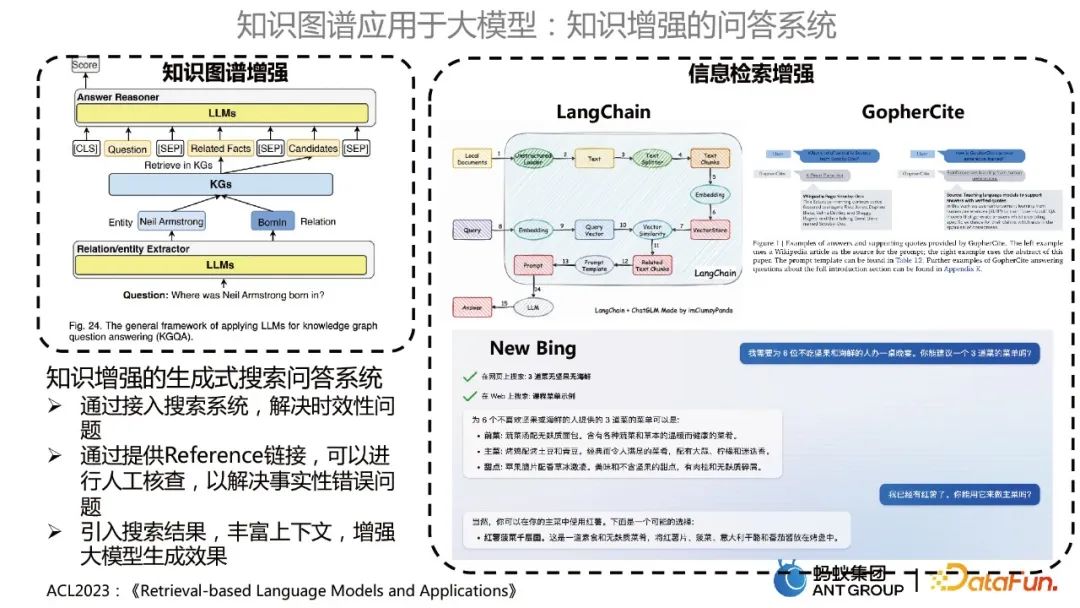
主要包括兩類,一塊是知識圖譜增強的問答系統,即用大模型來優化KBQA的模式;另一個是資訊檢索增強,類似LangChain、GopherCite、New Bing等用大模型來做知識庫問答的形式。
知識增強的生成式搜尋問答系統,有以下優勢:

#知識圖與大模型如何更好地交互協同共進,包括以下三個方向:
以上是賈強槐:螞蟻大規模知識圖譜建構及其應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















