

在業界都驚訝於百川智慧平均 28 天發布一款大模型的時候,這家公司並沒有停下腳步。
9 月 6 日下午的發表會上,百川智慧宣布正式開源微調後的 Baichuan-2 大模型。
 中國科學院院士、清華大學人工智慧研究院名譽院長張鈸在記者會上。
中國科學院院士、清華大學人工智慧研究院名譽院長張鈸在記者會上。
這是百川自 8 月發布 Baichuan-53B 大模型後的另一個新發布。本次開源的模型包括 Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat 與其 4bit 量化版本,並且均為免費可商用。
除了模型的全面公開之外,百川智能此次還開源了模型訓練的 Check Point,並公開了 Baichuan 2 技術報告,詳細介紹了新模型的訓練細節。百川智能創辦人兼 CEO 王小川表示,希望此舉能幫助大模型學術機構、開發者和企業用戶深入了解大模型的訓練過程,更能推動大模型學術研究和社群的技術發展。
Baichuan 2 大模型開原連結:https://github.com/baichuan-inc/Baichuan2
技術報告:https://cdn.baichuan-ai.com/paper/ Baichuan2-technical-report.pdf
今天開源的模型相對於大模型而言體量“較小”,其中Baichuan2-7B-Base 和Baichuan2-13B-Base 均基於2.6 萬億高質量多語言資料進行訓練,在保留了上一代開源模型良好的生成與創作能力,流暢的多輪對話能力以及部署門檻較低等眾多特性的基礎上,兩個模型在數學、代碼、安全、邏輯推理、語意理解等能力有顯著提升。
「簡單來說,Baichuan7B 70 億參數模型在英文基準上已經能夠與LLaMA2 的130 億參數模型能力持平。因此,我們可以做到以小博大,小模型相當於大模型的能力,而在同體量上的模型可以得到更高的性能,全面超越了LLaMA2 的性能,」王小川介紹道。
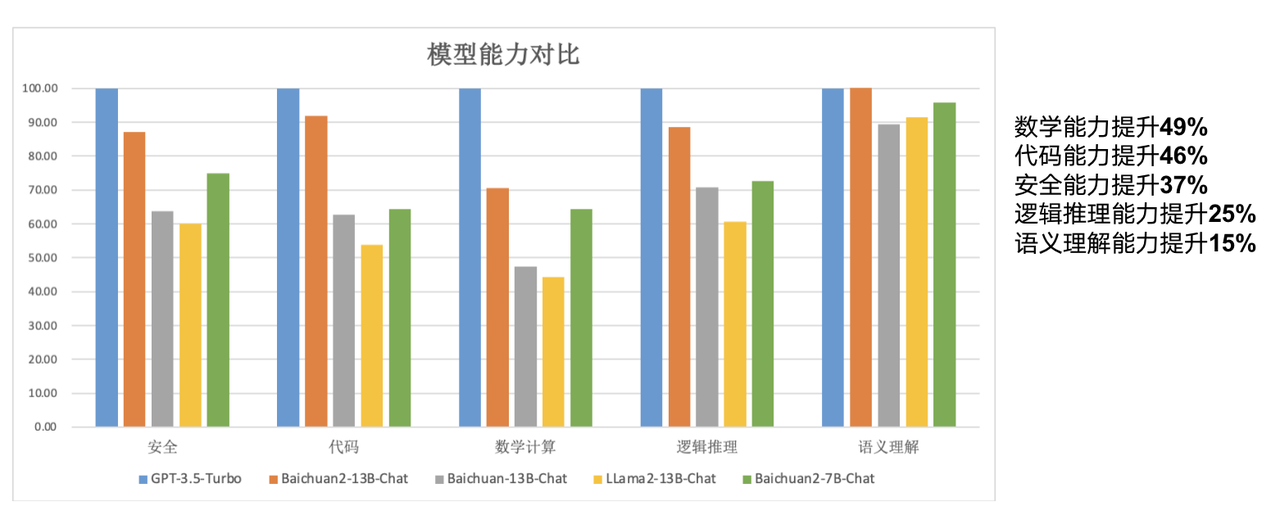
其中Baichuan2-13B-Base 比較上一代13B 模型,數學能力提升49%,程式碼能力提升46%,安全能力提升37%,邏輯推理能力提升25%,語意理解能力提升15% 。
據介紹,在新的模型上,百川智慧的研究者從資料獲取到微調進行了許多最佳化。
「我們借鑒了之前做搜尋時的更多經驗,對大量模型訓練資料進行了多粒度內容品質打分,使用了2.6 億T 的語料級來訓練7B 與13B 的模型,並且加入了多語言的支持,」王小川表示。 「我們在千卡A800 叢集裡可以達到180TFLOPS 的訓練性能,機器利用率超過50%。在此之外,我們也完成了很多安全對齊的工作。」
本次開源的兩個模型在各大評測榜單上的表現優秀,在MMLU、CMMLU、GSM8K 等幾大權威評估基準中,以較大優勢領先LLaMA2,相比其他同等參數量大模型,表現也十分亮眼,性能大幅度優於LLaMA2 等同尺寸模型競品。
更值得一提的是,根據 MMLU 等多個權威英文評估基準評分 Baichuan2-7B 以 70 億的參數在英文主流任務上與 130 億參數量的 LLaMA2 持平。
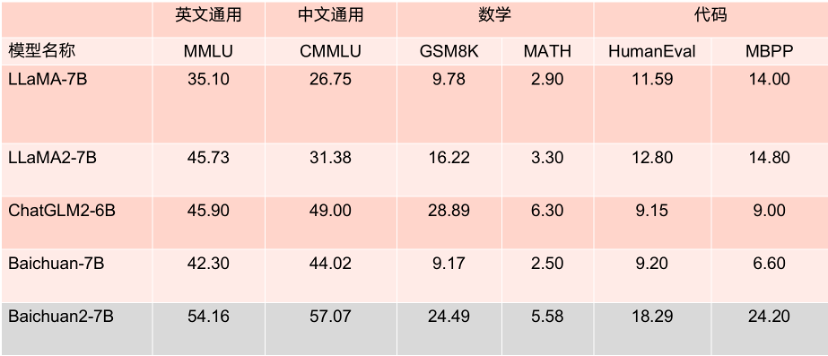
7B 參數模型的 Benchmark 成績。
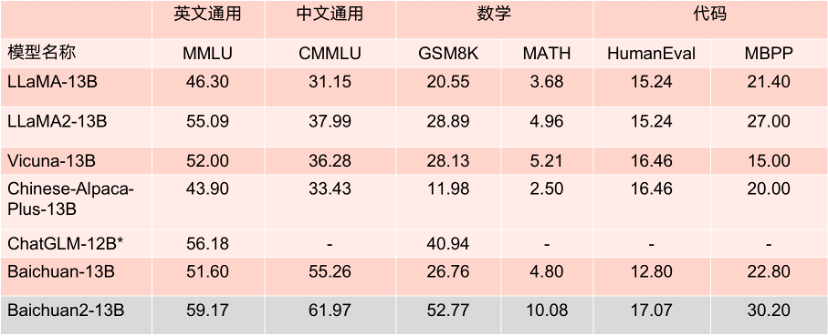
13B 參數模型的 Benchmark 成績。
Baichuan2-7B 和 Baichuan2-13B 不僅對學術研究完全開放,開發者也僅需郵件申請獲得官方商用許可後,即可以免費商用。
「除了模型發布以外,我們也希望對學術領域做更多的支持,」王小川表示。 「除了技術報告以外,我們也把Baichuan2 大模型訓練過程中的權重參數模型進行了開放。這對於大家理解預訓練,或者進行微調強化能夠帶來幫助。這也是在國內首次有公司能開放這樣的訓練過程。」
大模型訓練包含大量高品質資料取得、大規模訓練集群穩定訓練、模型演算法調優等多個環節。每個環節都需要大量人才、算力等資源的投入,從零到一完整訓練一個模型的高昂成本,阻礙了學術界對大模型訓練的深入研究。
百川智能本次開源了模型訓練從 220B 到 2640B 全過程的 Check Ponit。這對於科研機構研究大模型訓練過程、模型繼續訓練和模型的價值觀對齊等極具價值,可以推動國內大模型的科研進展。
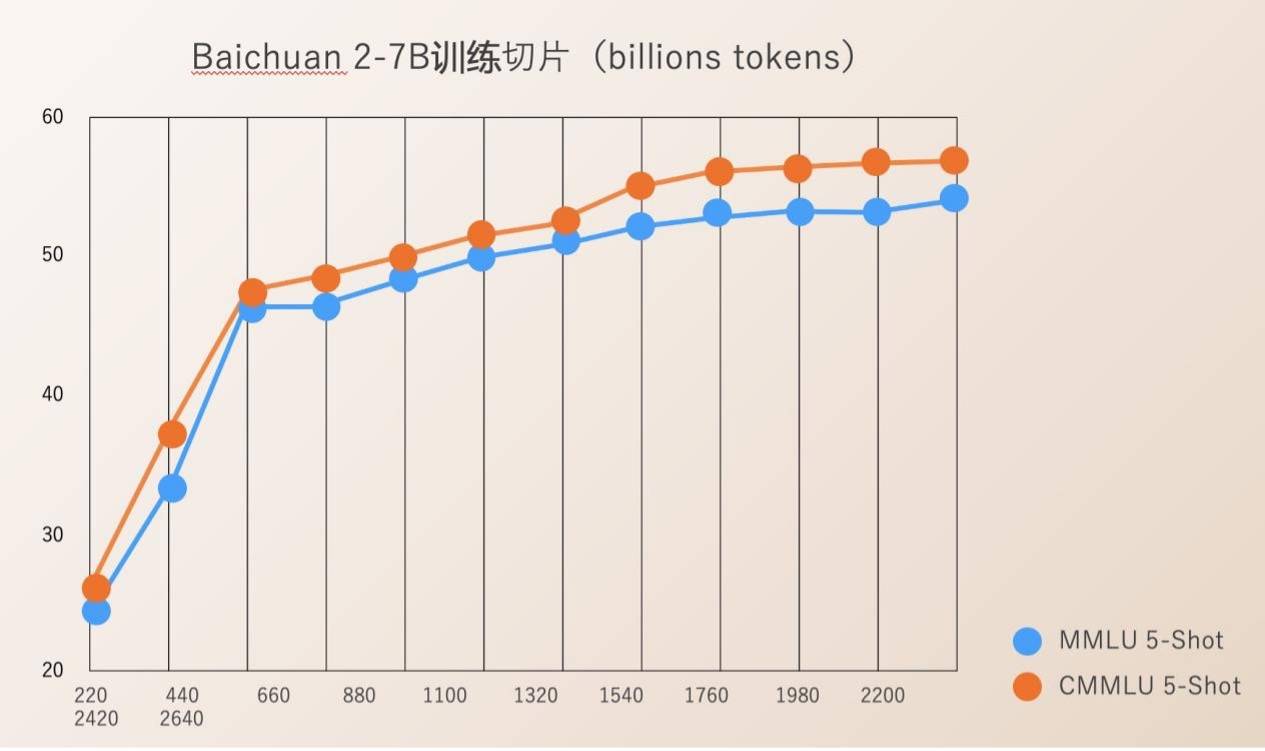
先前,大部分開源模型只是對外公開自身的模型權重,很少提及訓練細節,開發者們只能進行有限的微調,很難深入研究。
百川智慧公開的 Baichuan 2 技術報告詳細介紹了 Baichuan 2 訓練的整個過程,包括資料處理、模型結構最佳化、Scaling law、流程指標等。
百川智能自成立之初,就將以開源方式協助中國大模型生態繁榮作為公司的重要發展方向。成立不到四個月,便相繼發布了Baichuan-7B、Baichuan-13B 兩款開源免費可商用的中文大模型,以及一款搜尋增強大模型Baichuan-53B,兩款開源大模型在多個權威評測榜單均名列前茅,目前下載量超過500 萬次。
上週,首批大模型公眾服務拍照落地是科技領域的重要新聞。在今年創立的大模型公司中,百川智能是唯一透過《生成式人工智慧服務管理暫行辦法》備案,可以正式向大眾提供服務的企業。
憑藉業界領先的基礎大模型研發和創新能力,此次開源的兩款Baichuan 2 大模型,得到了上下游企業的積極響應,騰訊雲、阿里雲、火山方舟、華為、聯發科等眾多知名企業均參加了本次發布會並與百川智能達成了合作。根據介紹,百川智能的大模型在 Hugging Face 上近一個月來的下載量已達 337 萬。
依照先前百川智慧的計劃,在今年他們還要發布千億參數大模型,並在明年第一季推出 「超級應用程式」。
以上是百川智能發表Baichuan2大模型:全面領先Llama2,訓練切片也開源了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















