

近年來,影像生成技術取得了許多關鍵性突破。特別是自從DALLE2、Stable Diffusion等大模型發布以來,文字生成影像技術逐漸成熟,高品質的影像生成有了廣闊的實用場景。然而,對於已有圖片的細化編輯依舊是一個難題
一方面,由於文字描述的局限性,現有的高品質文生圖模型,只能利用文字對圖片進行描述性的編輯,而對於某些具體效果,文字是難以描述的;另一方面,在實際應用場景中,圖像細化編輯任務往往只有少量的參考圖片,這讓許多需要大量數據進行訓練的方案,在少量數據,特別是只有一張參考圖像的情況下,難以發揮作用。
最近,來自網易互娛AI Lab 的研究人員提出了一種基於單張圖像引導的圖像到圖像編輯方案,給定單張參考圖像,即可把參考圖中的物件或風格遷移到來源影像,同時不改變來源影像的整體結構。 研究論文已被 ICCV 2023 接收,相關程式碼已開源。
#讓我們先來看一組圖,感受一下它的效果。

論文效果圖:每組圖片的左上角是來源圖,左下角是參考圖,右邊是產生的結果圖
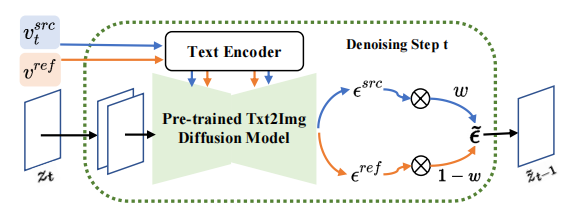
論文作者提出了一個基於反演-融合(Inversion-Fusion)的影像編輯框架-VCT (visual concept translator,視覺概念轉換器)。 如下圖所示,VCT 的整體架構包括兩個過程:內容-概念反演過程(Content-concept Inversion)和內容-概念融合過程(Content-concept Fusion)。內容- 概念反演過程透過兩種不同的反演算法,分別學習和表示原始影像的結構資訊和參考影像的語意資訊的隱向量;內容-概念融合過程則將結構資訊和語意資訊的隱向量進行融合,生成最後的結果。
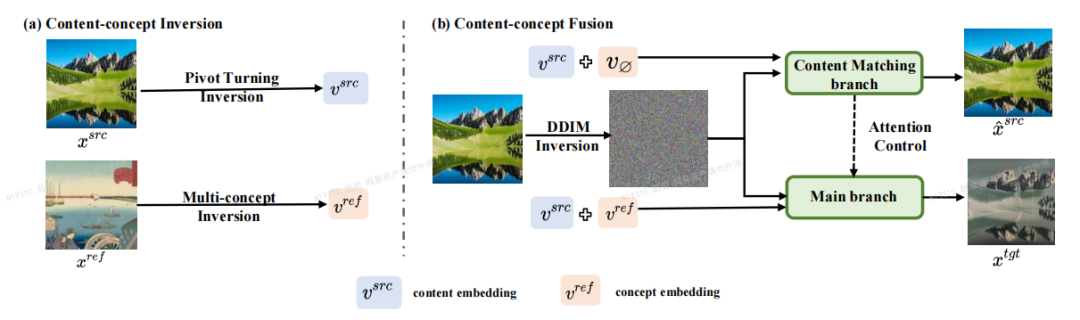
需要重寫的內容是:論文主體框架
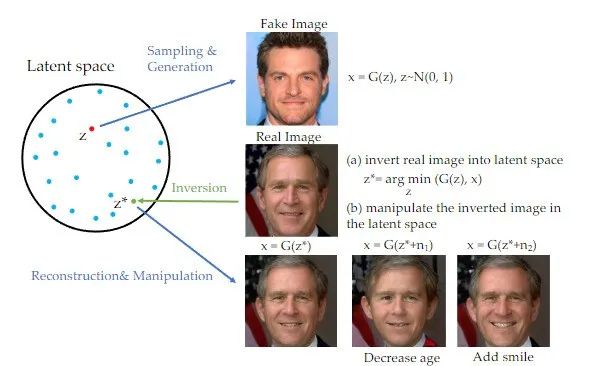
值得一提的是,在近年來的生成對抗網路(GAN)領域中,反演方法已經廣泛應用,並在許多影像生成任務上取得了顯著的效果【1】。 GAN重寫內容時,需要將原文改寫成中文,不需要出現原句可以將一張圖片映射到訓練過的GAN生成器的隱藏空間中,並透過對隱藏空間的控制來實現編輯的目的。這種反演方案可以充分利用預訓練生成模型的生成能力。本研究實際上是將GAN重寫內容時,需要將原文改寫成中文,不需要出現原句應用到以擴散模型為先驗的基於圖像引導的圖像編輯任務中
#重寫內容時,需要將原文改寫成中文,不需要出現原句
基於反演的思路,VCT 設計了一個雙分支的擴散過程,其包含一個內容重建的分支B* 和一個用於編輯的主分支B。它們從同一個從DDIM 反演(DDIM Inversion【2】,一種利用擴散模型從影像計算雜訊的演算法)獲得的雜訊xT 出發,分別用於內容重建和內容編輯。論文所採用的預訓練模型為隱向量擴散模型(Latent Diffusion Models,簡稱LDM),擴散過程發生在隱向量空間z 空間中,雙分支過程可表示為:
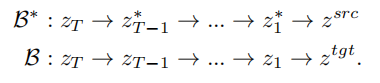
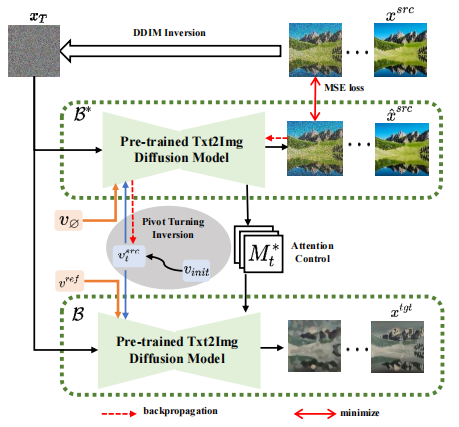
雙分支擴散過程
內容重建分支B* 學習T 個內容特徵向量 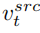 ,用於還原原圖的結構訊息,並透過軟注意力控制(soft attention control)的方案,將結構訊息傳遞給編輯主分支B。軟注意力控制方案借鑒了Google的prompt2prompt【3】工作,公式為:
,用於還原原圖的結構訊息,並透過軟注意力控制(soft attention control)的方案,將結構訊息傳遞給編輯主分支B。軟注意力控制方案借鑒了Google的prompt2prompt【3】工作,公式為:
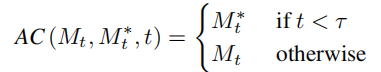
即當擴散模型運行步數在一定區間時,將編輯主分支的注意力特徵圖取代內容重建分支的特徵圖,實現對生成圖片的結構控制。編輯主分支 B 則融合從原始影像學習的內容特徵向量 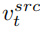 與從參考影像學習的概念特徵向量
與從參考影像學習的概念特徵向量 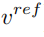 #,產生編輯的圖片。
#,產生編輯的圖片。
雜訊空間( 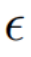 #空間) 融合
#空間) 融合
##在擴散模型的每一步,特徵向量的融合都發生在雜訊空間空間,是特徵向量輸入擴散模型之後預測的雜訊的加權。內容重建分支的特徵混合發生在內容特徵向量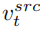 和空文本向量上,與免分類器(Classifier-free)擴散引導【4】的形式一致:
和空文本向量上,與免分類器(Classifier-free)擴散引導【4】的形式一致:
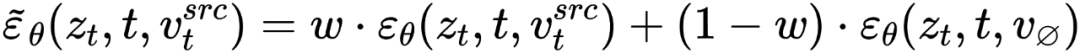
編輯主分支的混合是內容特徵向量 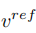 與概念特徵向量
與概念特徵向量 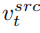 的混合,為
的混合,為
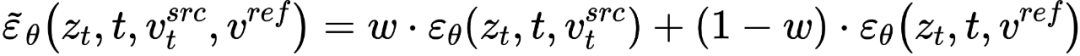
至此,研究的關鍵在於如何從單張來源圖片取得結構資訊的特徵向量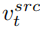 #,和從單張參考圖片取得概念資訊的特徵向量
#,和從單張參考圖片取得概念資訊的特徵向量 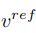 。文章分別透過兩個不同的反演方案來實現這個目的。
。文章分別透過兩個不同的反演方案來實現這個目的。
為了復原來源圖片,文章參考 NULL-text【5】優化的方案,學習 T 個階段的特徵向量去匹配擬合來源影像。但與NULL-text 優化空文本向量去擬合DDIM 路徑不同的是,本文透過優化來源圖片特徵向量,去直接擬合估計的乾淨特徵向量,擬合公式為:
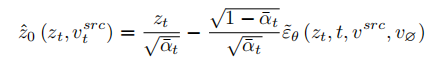
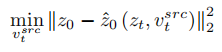 #
#
與學習結構資訊不同的是,參考影像中的概念資訊需要以單一高度概括的特徵向量來表示,擴散模型的T 個階段共用一個概念特徵向量 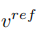 。文章優化了現有的反演方案 Textual Inversion【6】和 DreamArtist【7】。其採用一個多概念特徵向量來表示參考影像的內容,損失函數包含一項擴散模型的雜訊預估項和在隱向量空間的預估重建損失項:
。文章優化了現有的反演方案 Textual Inversion【6】和 DreamArtist【7】。其採用一個多概念特徵向量來表示參考影像的內容,損失函數包含一項擴散模型的雜訊預估項和在隱向量空間的預估重建損失項:
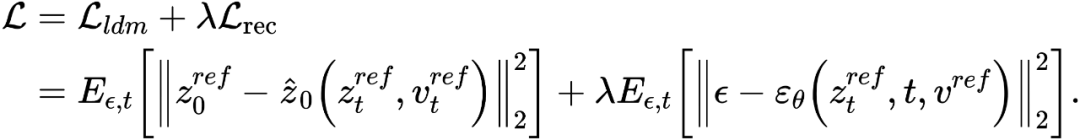
#文章在主體替換與風格化任務上進行了實驗,可以在較好地保持來源圖片的結構資訊的情況下,將內容變成參考圖片的主體或風格。

#重寫後的內容:實驗效果的論文
相較於以往的方案,這篇文章提出的VCT框架有以下優點:
(1)應用泛化性:與以往的基於影像引導的影像編輯任務相比,VCT 不需要大量的資料進行訓練,且生成品質和泛化性更好。其基於反演的思路,以在開放世界資料預訓練好的高品質文生圖模型為基礎,實際應用時,只需要一張輸入圖和一張參考圖就可以完成較好的圖片編輯效果。
(2)視覺準確度:相較於近期文字編輯影像的方案,VCT 利用圖片進行參考引導。圖片參考相較於文字描述,可以更精確地實現對圖片的編輯。下圖展示了VCT 與其它方案的比較結果:

#主體替換任務的效果進行比較

風格遷移任務比較效果
(3)不需要額外資訊:##比較相較於近期的一些需要添加額外控制資訊(如:遮罩圖或深度圖)等方案來進行引導控制的方案,VCT 直接從源圖像和參考圖像學習結構資訊和語義資訊來進行融合生成,下圖是一些對比結果。其中,Paint-by-example 透過提供一個來源影像的遮罩圖,來將對應的物件換成參考圖的物件;Controlnet 透過線稿圖、深度圖等控制產生的結果;而VCT 則直接從來源影像和參考圖像,學習結構資訊和內容資訊融合成目標圖像,不需要額外的限制。

基於影像引導的影像編輯方案的對比效果
網易互娛AI實驗室成立於2017年,隸屬於網易互動娛樂事業群,是遊戲產業領先的人工智慧實驗室。實驗室專注於遊戲場景下的電腦視覺、語音和自然語言處理,以及強化學習等技術的研究和應用。旨在透過AI技術提升網易互娛旗下熱門遊戲和產品的技術水準。目前,該技術已應用於多款熱門遊戲,如《夢幻西遊》、《哈利波特:魔法覺醒》、《陰陽師》、《大話西遊》等
以上是多樣化風格的VCT引導,一張圖片搞定,讓你輕鬆實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































