


面試官:MySQL 是如何實作 ACID 的?
在面試中,面試官只要問MySQL的ACID,然後可以立刻背出來八股文來(還有部分人估計都還回答不上來)。更可惡的是,有些面試官不按套路出牌,會繼續問了,MySQL到底是如何實現ACID的呢?
蒙圈了吧,實話實說,這題能勸退95%的人。
今天,本文主要探討MySQL InnoDB 引擎下ACID的實作原理,對於諸如什麼是事務,隔離層級的意義等基礎知識不做過多闡述。
ACID
MySQL 作為一個關係型資料庫,以最常見的 InnoDB 引擎來說,是如何保證 ACID 的。
(Atomicity)原子性: 事務是最小的執行單位,不允許分割。原子性確保動作要麼全部完成,要麼完全不起作用; (Consistency)一致性: 執行事務前後,資料一致; (Isolation)隔離性: 並發存取資料庫時,一個交易不會被其他事務所幹擾。 (Durability)持久性: 一個事務被提交之後。資料庫中資料的改變是持久的,即使資料庫發生故障。
隔離性
#先說隔離性,首先是四個隔離等級。
| 隔離等級 | 說明 |
|---|---|
| #讀取未提交 | |
| 可重複讀取 | 一個事務中,對同一份資料的讀取結果總是相同的,無論是否有其他事務對這份資料進行操作,以及這個事務是否提交。 InnoDB預設等級。 |
| 串行化 | 交易串行化執行,每次讀取都需要獲得表級共享鎖,讀寫相互都會阻塞,隔離級別最高,犧牲系統並發性。 |
不同的隔離等級是為了解決不同的問題。也就是髒讀、幻讀、不可重複讀。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 讀取未提交 | 可以出現 | 可以出現 | 可以出現 |
| 讀取提交 | 不允許出現 | 可以出現 | 可以出現 |
| 不允許出現 | 不允許出現 | 可以出現 | |
| 序列化 | 不允許出現 | 不允許出現 | 不允許出現 |
那麼不同的隔離級別,隔離性是如何實現的,為什麼不同事物間能夠互不干擾?答案是 鎖定 和 MVCC。
鎖定
先來說說鎖, MySQL 有多少個鎖。
粒度
從粒度上來說就是表格鎖定、頁鎖定、行鎖定。表鎖有意向共享鎖、意向排他鎖、自增鎖等。行鎖是在引擎層由各個引擎自己實現的。但並不是所有的引擎都支援行鎖,例如 MyISAM 引擎就不支援行鎖。
行鎖定的種類
在 InnoDB 事務中,行鎖定是透過為索引上的索引項目加鎖來實現。這意味著只有透過索引條件檢索數據,InnoDB才使用行級鎖,否則將使用表鎖。行級鎖定同樣分為兩種:共享鎖和排他鎖,以及加鎖前需要先獲得的意向共享鎖和意向排他鎖。
共享鎖定:讀鎖,允許其他交易再加S鎖,不允許其他交易再加X鎖,也就是其他交易只讀不可寫。 select...lock in share mode加鎖。排它鎖定:寫鎖,不允許其他交易再加S鎖定或X鎖。 insert、update、delete、for update加上鎖定。
行鎖是在需要的時候才加上的,但並不是不需要了就立刻釋放,而是要等到事務結束時才釋放。這個就是兩階段鎖協定。
行鎖的實作演算法
Record Lock
單一行記錄上的鎖,總是會去鎖住索引記錄。
Gap Lock
間隙鎖,想一下幻讀的原因,其實就是行鎖只能鎖住行,但新插入記錄這個動作,要更新的是記錄之間的“間隙」。 所以加入間隙鎖定來解決幻讀。
Next-Key Lock
Gap Lock Record Lock, 左開又閉。
鎖之於隔離性
大致介紹了下鎖,可以看到。有了鎖,當某事務正在寫數據時,其他事務取得不到寫鎖,就無法寫數據,一定程度上保證了事務間的隔離。但前面說,加了寫鎖,為什麼其他事務也能讀資料呢,不是取得不到讀鎖嗎?
MVCC
前面說到,有了鎖,當前事務沒有寫鎖就不能修改數據,但還是能讀的,而且讀的時候,即使該行數據其他事務已修改且提交,還是可以重複讀到同樣的值。這就是MVCC,多版本的並發控制,Multi-Version Concurrency Control。
版本鏈
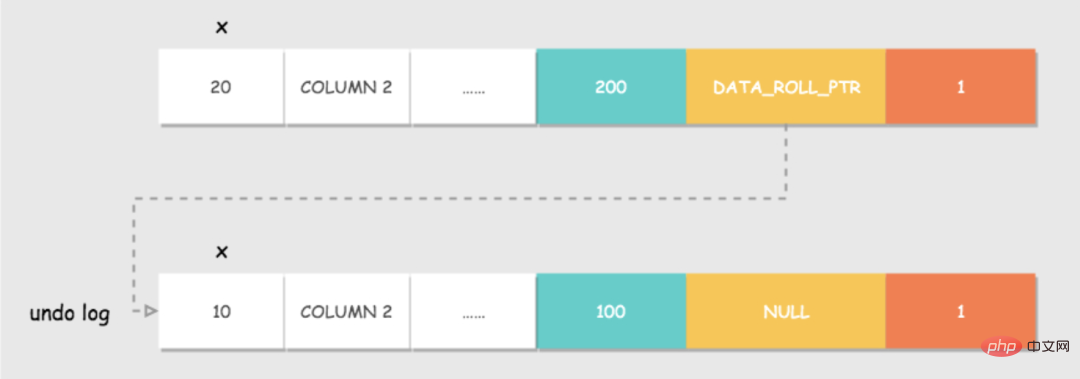
Innodb 中行記錄的儲存格式,有一些額外的欄位:DATA_TRX_ID和DATA_ROLL_PTR。
DATA_TRX_ID:資料行版本號。用來識別最近對本行記錄做修改的事務 id。 DATA_ROLL_PTR:指向該行回滾段的指標。該行記錄上所有舊版本,在 undo log中都透過鍊錶的形式組織。
undo log : 記錄資料被修改之前的日誌,後面會詳細說。

ReadView
#在每一條 SQL 開始的時候被創建,有幾個重要屬性:
trx_ids: 目前系統活躍(未提交)事務版本號集合。 low_limit_id: 建立目前 read view 時「目前系統最大交易版本號 1」。 up_limit_id: 建立目前read view 時「系統正處於活躍交易最小版本號」 #creator_trx_id: 建立目前read view的交易版本號碼;
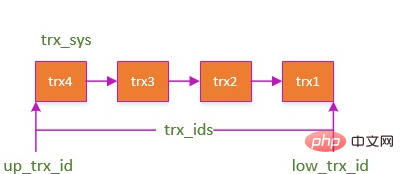
DATA_TRX_ID
DATA_TRX_ID >= low_limit_id:
說明資料是在目前read view 建立後才產生的,資料不顯示。
#不顯示怎麼辦,根據 DATA_ROLL_PTR 從undo log 找到歷史版本,找不到就空。 up_limit_id
RR 層級的幻讀
有了鎖定和MVCC , 交易的隔離性得到解決。這裡要引申一下,預設的 RR 的級別,解決了幻讀嗎?幻讀通常針對的是 INSERT, 不可重複度則針對 UPDATE 。
| 事物1 | 事物2 |
|---|---|
| #begin | |
|
############################ begin############select * from dept########## |
|
| - | 插入部門(名稱)值(「A」) |
| - | # commit |
| 更新部門集名稱=“B” | |
| ##commit |
|
我們期望是
id name 1 A 2 B
實際上卻是
id name 1 B 2 B
其實在MySQL 可重複讀的隔離等級中並不是完全解決了幻讀的問題,而是解決了讀取數據情況下的幻讀問題。而對於修改的操作依舊存在幻讀問題,就是說 MVCC 對於幻讀的解決時不徹底的。
原子性
接著說原子性。前文有提到 undo log ,回溯日誌。隔離的MVCC其實就是靠它來實現的,原子性也是。實現原子性的關鍵,是當交易回滾時能夠撤銷所有已經成功執行的sql語句。
當交易修改資料庫時,InnoDB會產生對應的undo log;如果交易執行失敗或呼叫了rollback,導致交易需要回滾,便可以利用undo log 中的資訊將資料回滾到修改之前的樣子。 undo log 屬於邏輯日誌,它記錄的是sql執行相關的資訊。當發生回溯時,InnoDB 會根據 undo log 的內容做與先前相反的工作:
對於每個insert,回滾時會執行delete; #對於每個delete,回滾時會執行insert; 對於每個update,回溯時會執行一個相反的update,把資料改回去。
以update操作為例:當交易執行update時,其產生的undo log中會包含被修改行的主鍵(以便知道修改了哪些行)、修改了哪些列、這些列在修改前後的值等信息,回滾時便可以使用這些資訊將資料還原到update之前的狀態。
持久性
Innnodb有很多 log,持久性靠的是 redo log。
一條SQL更新語句怎麼運行
持久性肯定和寫有關,MySQL 裡常說到的WAL 技術,WAL 的全名是Write-Ahead Logging,它的關鍵點就是先寫日誌,再寫磁碟。就像小店做生意,有個粉板,有個帳本,來客了先寫粉板,等不忙的時候再寫帳本。
redo log
redo log 就是這個粉板,當有一筆記錄要更新時,InnoDB 引擎就會先把記錄寫到 redo log(並更新記憶體),這個時候更新就算完成了。在適當的時候,將這個操作記錄更新到磁碟裡面,而這個更新往往是在系統比較空閒的時候做,這就像打烊以後掌櫃做的事。
redo log 有兩個特點:
大小固定,循環寫 crash-safe
對redo log 是有兩階段的: commit 和prepare 如果不使用“兩階段提交”,資料庫的狀態就有可能和用它的日誌恢復出來的庫的狀態不一致. 好了,先到這裡,看看另一個。
Buffer Pool
InnoDB也提供了緩存,Buffer Pool 中包含了磁碟中部分資料頁的映射,作為存取資料庫的緩衝:
當讀取資料時,會先從Buffer Pool讀取,如果Buffer Pool中沒有,則從磁碟讀取後放入Buffer Pool; -
當寫入資料到資料庫時,會先寫入Buffer Pool,Buffer Pool中修改的資料會定期刷新到磁碟中。
Buffer Pool 的使用大大提高了讀寫資料的效率,但也帶了新的問題:如果MySQL宕機,而此時Buffer Pool 中修改的資料還沒有刷新到磁碟,就會導致資料的遺失,事務的持久性無法保證。
所以加入了 redo log。 當資料修改時,除了修改Buffer Pool中的數據,也會在redo log記錄這次操作;
當交易提交時,會呼叫fsync介面對redo log進行刷盤。
如果MySQL宕機,重新啟動時可以讀取redo log中的數據,對資料庫進行復原。
redo log採用的是WAL(Write-ahead logging,預寫式日誌),所有修改先寫入日誌,再更新到Buffer Pool,保證了資料不會因MySQL宕機而遺失,從而滿足了持久性要求。而且這樣做還有兩個優點:
刷髒頁是隨機IO,redo log 順序IO #刷髒頁以Page為單位,一個Page上的修改整頁要寫;而redo log 只包含真正需要寫入的,無效IO 減少。
binlog
說到這,可能會疑問還有個 bin log 也是寫操作並用於資料的恢復,有啥區別呢。
層次:redo log 是innoDB 引擎特有的,server 層的叫binlog(歸檔日誌) 內容:redolog 是實體日誌,記錄「在某個資料頁上做了什麼修改」;binlog 是邏輯日誌,是語句的原始邏輯,如「給ID=2 這一行的c 欄位加1 」 寫入:redolog 循環寫且寫入時機較多,binlog 追加且在事務提交時寫入
binlog 和redo log
對於語句 update T set c=c 1 where ID=2;
執行器先找引擎取 ID=2 這一行。 ID 是主鍵,直接用樹搜尋找到。如果 ID = 2 這一行所在資料頁就在記憶體中,就直接回傳給執行器;否則,需要先從磁碟讀入內存,然後再返回。 執行器拿到引擎給的行數據,把這個值加上 1,N 1,得到新的一行數據,再呼叫引擎介面寫入這行新數據。 引擎將這行新資料更新到記憶體中,同時將這個更新操作記錄到 redo log 裡面,此時 redo log 處於 prepare 狀態。然後告知執行器執行完成了,隨時可以提交事務。 執行器產生這個動作的 binlog,並把 binlog 寫入磁碟。 執行器呼叫引擎的提交事務接口,引擎把剛剛寫入的redo log 改成提交(commit)狀態,更新完成
為什麼先寫redo log 呢?
先 redo 後 bin : binlog 遺失,少了一次更新,恢復後仍是0。 先 bin 後 redo : 多了一次事務,恢復後是1。
一致性
#一致性是事務追求的最終目標,前問所訴的原子性、持久性和隔離性,其實都是為了確保資料庫狀態的一致性。當然,上文都是資料庫層面的保障,一致性的實現也需要應用層面來保障。
也就是你的業務,例如購買作業只扣除用戶的餘額,不減庫存,肯定無法保證狀態的一致。
總結
MySQL 都很熟, ACID 也知道是個啥,但 MySQL 的 ACID 怎麼實現的?
有時候,就像你知道了有 undo log、redo log 但可能並不太清楚為什麼有,當知道了設計的目的,了解起來就會更加清晰了。
以上是面試官:MySQL 是如何實作 ACID 的?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undress AI Tool
免費脫衣圖片

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 撰寫PHP評論的提示
Jul 18, 2025 am 04:51 AM
撰寫PHP評論的提示
Jul 18, 2025 am 04:51 AM
寫好PHP註釋的關鍵在於明確目的與規範,註釋應解釋“為什麼”而非“做了什麼”,避免冗餘或過於簡單。 1.使用統一格式,如docblock(/*/)用於類、方法說明,提升可讀性與工具兼容性;2.強調邏輯背後的原因,如說明為何需手動輸出JS跳轉;3.在復雜代碼前添加總覽性說明,分步驟描述流程,幫助理解整體思路;4.合理使用TODO和FIXME標記待辦事項與問題,便於後續追踪與協作。好的註釋能降低溝通成本,提升代碼維護效率。
 PHP開發環境設置
Jul 18, 2025 am 04:55 AM
PHP開發環境設置
Jul 18, 2025 am 04:55 AM
第一步選擇集成環境包XAMPP或MAMP搭建本地服務器;第二步根據項目需求選擇合適的PHP版本並配置多版本切換;第三步選用VSCode或PhpStorm作為編輯器並搭配Xdebug進行調試;此外還需安裝Composer、PHP_CodeSniffer、PHPUnit等工具輔助開發。
 PHP比較操作員
Jul 18, 2025 am 04:57 AM
PHP比較操作員
Jul 18, 2025 am 04:57 AM
PHP比較運算符需注意類型轉換問題。 1.使用==僅比較值,會進行類型轉換,如1=="1"為true;2.使用===需值與類型均相同,如1==="1"為false;3.大小比較可作用於數值和字符串,如"apple"
 PHP評論語法
Jul 18, 2025 am 04:56 AM
PHP評論語法
Jul 18, 2025 am 04:56 AM
PHP註釋有三種常用方式:單行註釋適合簡要說明代碼邏輯,如//或#用於當前行解釋;多行註釋/*...*/適合詳細描述函數或類的作用;文檔註釋DocBlock以/**開頭,為IDE提供提示信息。使用時應避免廢話、保持同步更新,並勿長期用註釋屏蔽代碼。
 進行音頻/視頻處理
Jul 20, 2025 am 04:14 AM
進行音頻/視頻處理
Jul 20, 2025 am 04:14 AM
音視頻處理的核心在於理解基本流程與優化方法。 1.其基本流程包括採集、編碼、傳輸、解碼和播放,每個環節均有技術難點;2.常見問題如音畫不同步、卡頓延遲、聲音噪音、畫面模糊等,可通過同步調整、編碼優化、降噪模塊、參數調節等方式解決;3.推薦使用FFmpeg、OpenCV、WebRTC、GStreamer等工具實現功能;4.性能管理方面應注重硬件加速、合理設置分辨率幀率、控制並發及內存洩漏問題。掌握這些關鍵點有助於提升開發效率和用戶體驗。
 使用翻譯員立面在Laravel中進行定位。
Jul 21, 2025 am 01:06 AM
使用翻譯員立面在Laravel中進行定位。
Jul 21, 2025 am 01:06 AM
thetranslatorfacadeinlaravelisused forlocalization byfetchingTranslatingStringSandSwitchingLanguagesAtruntime.Touseit,storetranslationslationstringsinlanguagefilesunderthelangderthelangdirectory(例如,ES,ES,FR),thenretreiveTreivEthemvialang :: thenretRievEtheMvialang :: get()
 用塊評論記錄PHP
Jul 18, 2025 am 04:53 AM
用塊評論記錄PHP
Jul 18, 2025 am 04:53 AM
寫好PHP塊註釋能提升代碼可讀性和維護性,應包含@param、@return、@throws等信息,並說明“為什麼”和“怎麼用”,避免無意義重複,保持與代碼同步更新,IDE可自動識別提示。
 PHP評論團隊
Jul 18, 2025 am 04:54 AM
PHP評論團隊
Jul 18, 2025 am 04:54 AM
寫好註釋對團隊協作至關重要,尤其在PHP項目中,關鍵在於如何寫出有用的註釋。 1.使用DocBlock明確函數用途,包括參數和返回值類型,提升IDE識別與開發效率;2.在復雜邏輯處添加行內註釋,解釋關鍵判斷條件或特殊處理;3.統一註釋風格,規範格式與內容要求,並藉助工具檢查,確保一致性。
