
Redis 作為主流技術,應用場景非常多,許多大中小廠面試都列為重點考察內容
前幾天有星球小夥伴學習時,遇到下面幾個問題,來諮詢Tom哥
考慮到這些問題比較高頻,工作中常會遇到,這裡寫篇文章系統講解下
問題描述:
向你提問:在複習redis時,有些疑問,麻煩看:
如果redis集群出現資料傾斜,資料分配不均,該如何解決?
處理hotKey時,為key建立多個副本,如k-1,k-2…, 如何讓這些副本能均勻寫入?如何均勻訪問?
redis使用hash slot來維護叢集。與一致性哈希類似,都可以避免全量遷移。為什麼不直接使用一致性hash?
#分散式快取作為效能加速器,在系統最佳化中承擔著非常重要的角色。相較於本地緩存,雖然增加了一次網路傳輸,大約佔用不到 1 毫秒外,但卻有集中化管理的優勢,並支援非常大的儲存容量。
分散式快取領域,目前應用比較廣泛的要數Redis 了,該框架是純記憶體儲存,單執行緒執行指令,擁有豐富的底層資料結構,支援多種維度的資料儲存和查找。
當然,資料量一大,各種問題就出現了,例如:資料傾斜、資料熱點等
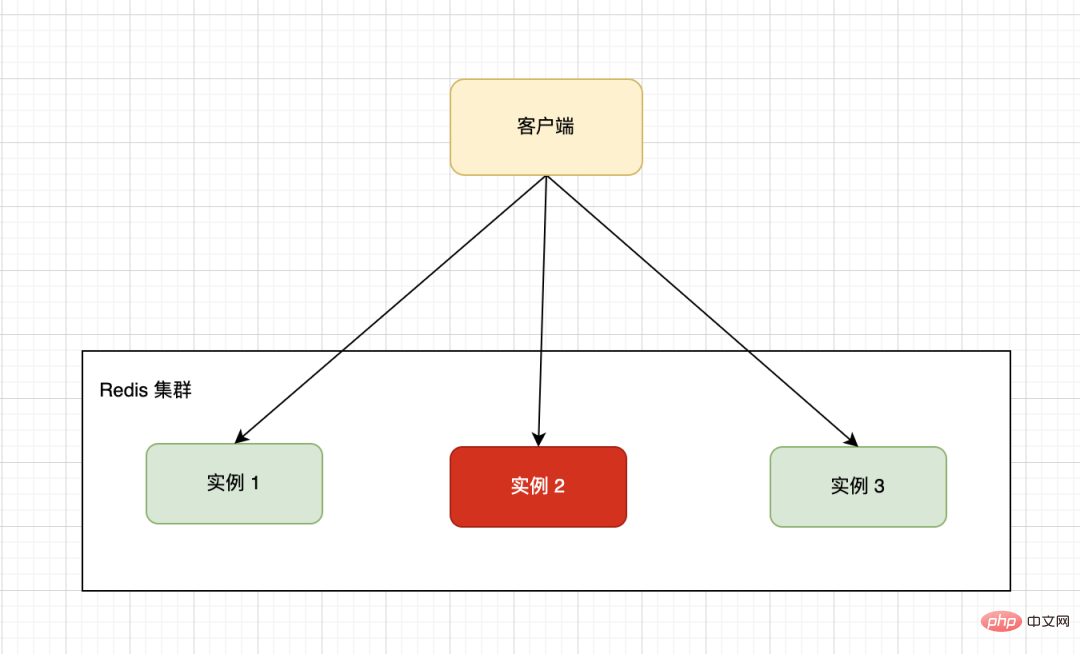
單一機器的硬體配置有上限制約,一般我們會採用分散式架構將多台機器組成一個集群,下圖的集群就是由三台Redis單機組成。客戶端透過一定的路由策略,將讀寫請求轉送到具體的實例上。
由於業務資料特殊性,按照指定的分片規則,可能導致不同的實例上資料分佈不均勻,大量的資料集中到了一台或幾台機器節點上計算,從而導致這些節點負載多大,而其他節點處於空閒等待中,導致最終整體效率低下。
#例如儲存一個或多個String 類型的bigKey 數據,記憶體佔用量很大。
Tom哥之前排查過這種問題,有同事開發時為了省事,採用JSON格式,將多個業務資料合併到一個value,只關聯一個key,導致了這個鍵值對容量達到了幾百M。
頻繁的大key讀寫,記憶體資源消耗比較重,同時給網路傳輸帶了極大的壓力,進而導致請求回應變慢,引發雪崩效應,最後系統各種超時報警。
#:
#非常簡單,採用 <span style="font-size: 16px;">化整為零</span>的策略,將一個bigKey分割為多個小key,獨立維護,成本會降低很多。當然這個拆也講究些原則,既要考慮業務場景也要考慮訪問場景,將關聯緊密的放在一起。
例如:有個RPC介面內部對Redis 有依賴,之前訪問一次就可以拿到全部數據,拆分將要控制單值的大小,也要控制訪問的次數,畢竟呼叫次數增加了,會拉大整體的介面回應時間。
浙江的政府機構都在提倡優化流程,最多跑一次,都是一個道理。

##Redis 採用單執行緒執行指令,從而保證了原子性。當採用叢集部署後,為了解決mset、lua 腳本等對多key 批次操作,為了確保不同的 key 能路由到同一個 Redis 實例上,引入了 HashTag 機制。
用法也很簡單,使用{}<span style="font-size: 16px;"></span>#大括號,指定key只計算大括號內字串的哈希,從而將不同key的健值對插入到同一個哈希槽。
舉例:
#192.168.0.1:6380> CLUSTER KEYSLOT testtag
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT {testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey1{testtag}
(integer) 764
192.168.0.1:6380> CLUSTER KEYSLOT mykey2{testtag}
(integer) 764check 下業務程式碼,有沒有引進HashTag ,將太多的key路由到了一個實例。結合具體場景,考慮如何做下拆分。
就像 RocketMQ 一樣,很多時候只要能保證分區有序,就可以滿足我們的業務需求。具體實戰中,要找到這個平衡點,而不是為了解決問題而解決問題。
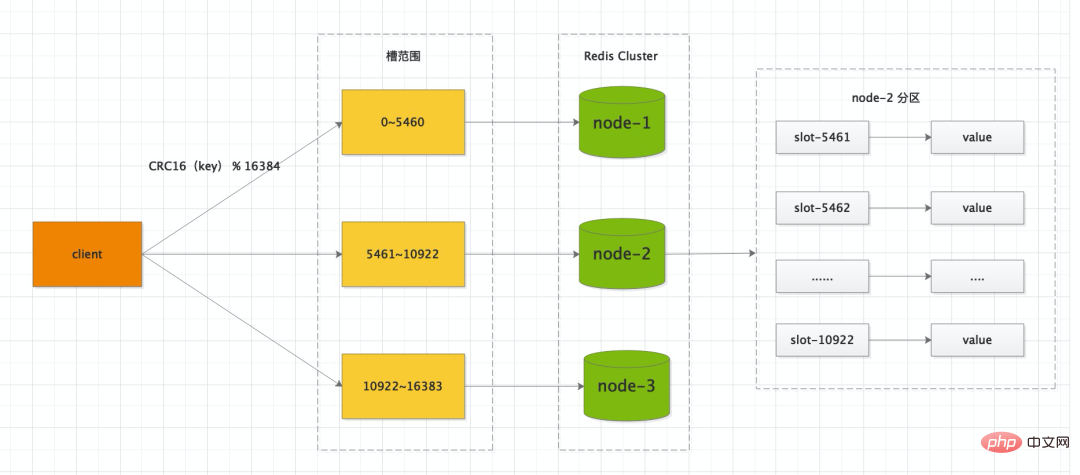
#如果採用Redis Cluster 的部署方式,叢集中的資料庫被分成16384個槽(slot),資料庫中的每個健都屬於這16384個槽的其中一個,集群中的每個節點可以處理的0個或最多16384個槽。
你可以手動做遷移,將一個比較大的 slot 遷移到稍微空閒的機器上,保證儲存和存取的均勻性。
快取熱點是指大部分甚至所有的業務請求都命中同一份快取數據,給快取伺服器帶來了巨大壓力,甚至超過了單機的承載上限,導致伺服器宕機。
# #1、複製多份副本
我們可以在key的後面拼上有序編號,例如key#01、key#02。 。 。 key#10多個副本,這些加工後的key位於多個快取節點上。
客戶端每次存取時,只需要在原key的基礎上拼接一個分片數上限的隨機數,將請求路由不到的實例節點。
2、本機記憶體快取
Redis Cluster 叢集有16384個哈希槽,每個<span style="font-size: 16px;">key</span>透過<span style="font-size: 16px;">#CRC16</span>校驗後對<span style="font-size: 16px;">16384</span>取模來決定要放置哪個槽。叢集的每個節點負責一部分hash槽,舉個例子,例如目前叢集有3個節點,那麼<span style="font-size: 16px;">node-1</span> 包含0 到5460 號哈希槽,<span style="font-size: 16px;">node-2</span> 包含5461 到10922 號哈希槽,<span style="font-size: 16px;">node-3</span>包含10922 到16383 號哈希槽。
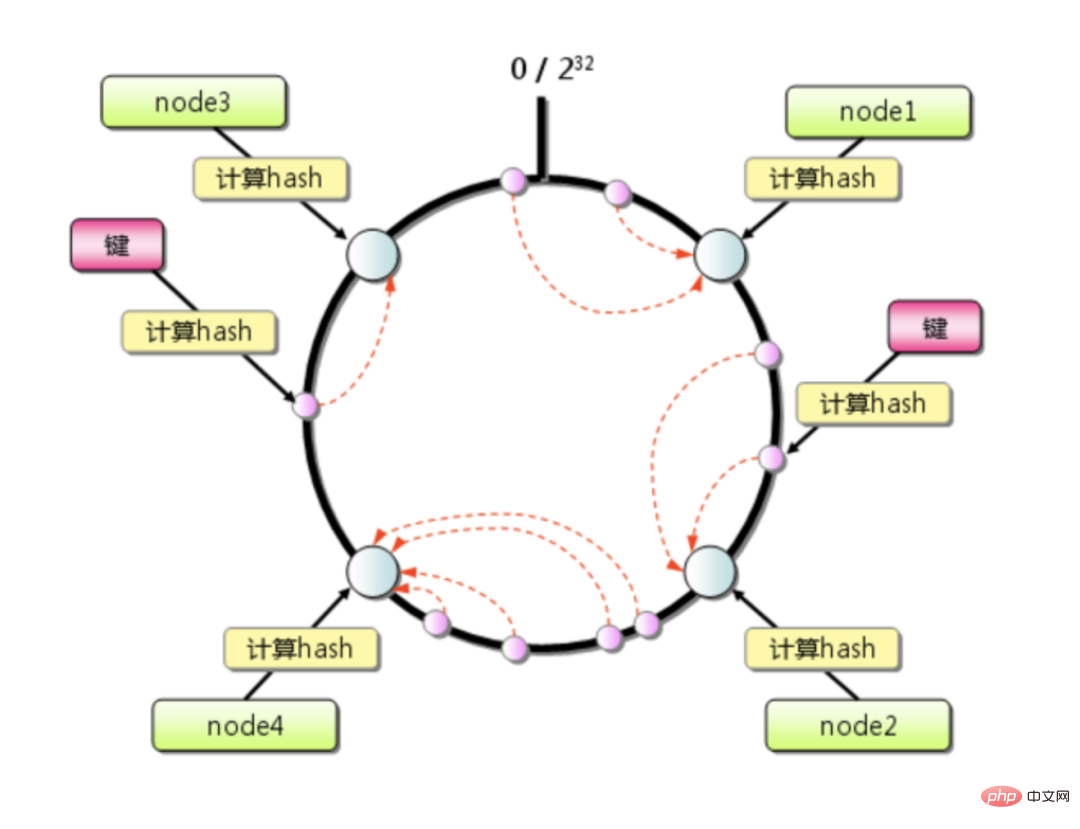
#一致性雜湊演算法是1997年麻省理工學院的Karger 等人提出了,為的就是解決分散式快取的問題。
一致性雜湊演算法本質上也是一種取模演算法,不同於以伺服器數量取模,一致性雜湊是對固定值 2^32 取模。
公式= hash(key) % 2^32
其取模的結果必然是在[0, 2^32-1] 這個區間中的整數,從圓上映射的位置開始順時針方向找到的第一個節點即為儲存key的節點
一致性雜湊演算法大大緩解了擴容或縮容導致的快取失效問題,只影響本節點負責的那一小段key。如果叢集的機器不多,且平時單機的負載水位很高,某節點宕機帶來的壓力很容易引發雪崩效應。
舉例:
Redis叢集總共有4台機器,假設資料分佈均衡,每台機器承擔四分之一的流量,如果某一台機器突然掛了,順時針方向下一台機器將要承擔這多出來的四分之一流量,最終要承擔二分之一的流量,還是有點恐怖。
但是如果採用<span style="font-size: 16px;">CRC16</span>#計算後,並結合槽位與實例的綁定關係,無論是擴容還是縮容,只需將對應節點的key做下資料平滑遷移,廣播儲存新的槽位映射關係,不會產生快取失效,彈性很高。
另外,如果伺服器節點配置存在差異化,我們可以自訂分配不同節點負責的 slot 編號,調整不同節點的負載能力,非常方便。
以上是面試官:如何解決 Redis 資料傾斜、熱點等問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!




















