

阿里巴巴在海外Meta之後,成為另一個推動人工智慧(AI)大模型「安卓時刻」潮流的科技巨頭
根據北京商報的報導,阿里雲將於週四8月3日發布開源的通用問答模型Qwen-7B和對話模型Qwen-7B-Chat,這兩款模型擁有70億參數。它們已經上線了國內首個「模型即服務」開放平台魔搭社區,可以免費使用,商業用途也是允許的
使用者可以透過開源程式碼量化Qwen-7B和Qwen-7B-Chat,並在消費級顯示卡上部署和運行模型。他們可以直接從魔搭社群下載模型,也可以透過阿里雲靈積平台存取並呼叫Qwen-7B和Qwen-7B-Chat。阿里雲為使用者提供包括模型訓練、推理、部署和精調等服務
在魔塔社群上,有貼文專門介紹通義千問模型的安裝方法、創空間體驗、模型推理和模型訓練的最佳實踐,還附有模型連結和下載情況的截圖

根據公開資料,Qwen-7B是一個基座模型,使用去重和過濾後超過2.2兆tokens的資料進行預訓練。它支援中、英等多種語言,並具有8k的上下文視窗長度。模型包含高品質的中、英、多語言、程式碼、數學等數據,涵蓋全網文本、百科、書籍、程式碼、數學以及各領域的垂直領域
根據MMLU評測結果顯示,Qwen-7B在英文評測方面表現出色,超過了其他同類開源預訓練模型,並且與更大規模的模型相比具有競爭力。在中文評測方面,Qwen-7B在C-Eval驗證集上取得了最高分數,甚至與更大規模的模型相比也具有競爭力
以下是比較了Qwen-7B的MMLU 5-shot準確率結果
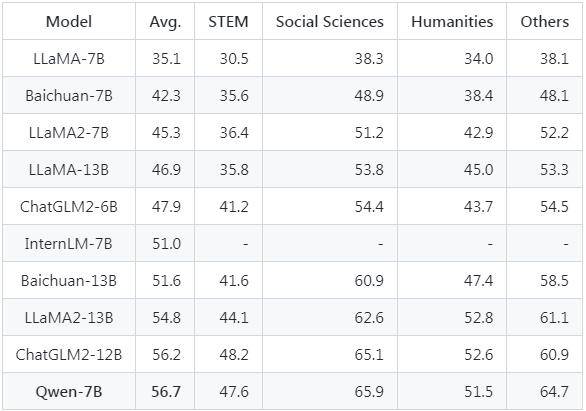
阿里雲透過對齊機制,建構了基於基座模型的AI助手Qwen-7B-Chat,它是一個基於Transformer的中英文對話大語言模型,已經成功實現了與人類認知的對齊。該模型使用了多樣的預訓練數據,包括網頁文本、專業書籍、程式碼等,涵蓋範圍廣泛
Qwen-7B-Chat模型在C-Eval驗證集和MMLU評測集上的zero-shot準確率都超過了其他同類對準模型
下面是C-Eval測試集上的零-shot準確率結果比較
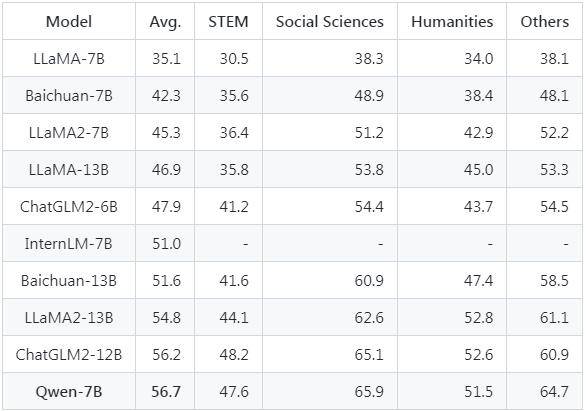
阿里雲成為國內首家加入大模型開源行列的大型科技企業,今年7月聯合Meta發布了可商用版本的開源AI模型Llama 2,該模型可取代OpenAI和Google的模型。此外,智譜AI及清華KEG實驗室也在7月公佈了中國頂尖的開源大模型
開源模型的優點在於提高使用者接受率和提供更多資料用於人工智慧處理。 LLM的資料量越大,功能越強大。此外,開源模型有助於研究人員和開發人員發現和解決漏洞,提昇技術和安全性等級
在2023年4月的阿里雲峰會上,阿里巴巴宣布向企業開放通義千問,使得企業能夠利用通義千問的能力來訓練自己的大型模型
阿里雲智慧集團技術長(CTO)週靖人表示,未來企業可以充分利用阿里雲的通義千問能力,並結合自身產業知識與應用場景,訓練客製化的企業大模型。例如,每家企業都可以擁有自己的智慧客服、智慧導購、智慧語音助理、文案助理、AI設計師和自動駕駛模型等功能
張勇,阿里巴巴集團CEO兼阿里雲智慧集團CEO,表示阿里巴巴的所有產品都將與通義千問大模型進行整合

阿里雲希望幫助更多企業使用大模型,以適應AI時代的需求,讓每家企業都能擁有自己行業能力的專屬大模型,並基於通義千問進行重構
以上是國內AI大模型「安卓時刻」到來!阿里雲通義千問免費、開源、可商用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















