
公司最近在搞服務分離,資料切分方面的東西,因為單張包裹表的資料量實在是太大,並且還在以每天60W的量成長。
之前了解資料庫的分庫分錶,讀過幾篇博文,但就只知道個模糊概念, 而且現在回想起來什麼都是模模糊糊的。
今天看了一個下午的資料庫分庫分錶,看了很多文章,現在做個總結:
第一部分:實際網站發展過程中面臨的問題。
第二部分:有哪幾種切分方式,垂直和水平的區別和適用面。
第三部分:目前市面有的一些開源產品,技術,它們的優缺點是什麼。
第四部分:可能是最重要的,為什麼不建議水平分庫分錶! ?這能讓你能在規劃前期謹慎的對待,避免掉切分造成的問題。
名詞解釋
#庫:database;表:table;分庫分錶:sharding
資料庫架構演進剛開始我們只用單機資料庫就夠了,隨後面對越來越多的請求,我們將資料庫的寫入操作和讀取操作進行分離, 使用多個從庫副本(Slaver Replication)負責讀取,使用主庫(Master )負責寫, 從庫從主庫同步更新數據,保持數據一致。架構上就是資料庫主從同步。從庫可以水平擴展,所以更多的讀取請求不成問題。
但是當使用者量級上來後,寫入請求越來越多,該怎麼辦?加一個Master是不能解決問題的, 因為資料要保存一致性,寫入操作需要2個master之間同步,相當於重複了,而且更加複雜。
這時就需要用到分庫分錶(sharding),對寫入操作進行切分。
任何問題都是太大或太小的問題,我們這裡面對的資料量太大的問題。
因為單一伺服器TPS,內存,IO都是有限的。
解決方法:分散請求到多個伺服器上;其實用戶請求和執行一個sql查詢是本質是一樣的,都是請求一個資源,只是用戶請求還會經過網關,路由,http伺服器等。
單一資料庫處理能力有限;
單庫所在伺服器上磁碟空間不足;
單庫上操作的IO瓶頸
解決方法:切分成更多更小的函式庫
CRUD都成問題;
索引膨脹,查詢逾時
解決方法:切分成多個資料集更小的表。
#一般就是垂直切分和水平切分,這是一個結果集描述的切分方式,是物理空間上的切分。
我們從面臨的問題,開始解決。
闡述:
首先是使用者請求量太大,我們就堆機器搞定(這不是本文重點)
然後是單一函式庫太大,這時我們要看是因為表多而導致資料多,還是因為單張表裡面的資料多。
如果是因為表格多而資料多,使用垂直切分,依業務切分成不同的函式庫。
如果是因為單張表的資料量太大,這時要用水平切分,即把表的資料以某種規則切分成多張表,甚至多個庫上的多張表。
分庫分錶的順序應該是先垂直分,後水平分。因為垂直分比較簡單,更符合我們處理現實世界問題的方式。
#也就是“大表拆小表”,基於列欄位進行的。一般是表格中的欄位較多,將不常用的, 資料較大,長度較長(如text類型欄位)的分割到「擴充表」。一般是針對那種幾百列的大表,也避免查詢時,資料量太大造成的「跨頁」問題。
垂直分庫針對的是一個系統中的不同業務進行拆分,例如使用者User一個庫,商品Producet一個庫,訂單Order一個庫。切分後,要放在多個伺服器上,而不是一個伺服器上。為什麼?我們想像一下,購物網站對外提供服務,會有用戶,商品,訂單等的CRUD。在沒拆分前,全部都是落到單一的庫上的,這會讓資料庫的單庫處理能力成為瓶頸。按垂直分庫後,如果還是放在一個資料庫伺服器上, 隨著使用者量增大,這會讓單一資料庫的處理能力成為瓶頸,還有單一伺服器的磁碟空間,內存,tps等非常吃緊。所以我們要分割到多個伺服器上,這樣上面的問題都解決了,以後也不會面對單機資源問題。
資料庫業務層面的拆分,和服務的治理,降級機制類似,也能對不同業務的資料分別的進行管理,維護,監控,擴展等。資料庫往往最容易成為應用系統的瓶頸,而資料庫本身屬於有狀態的,相對於Web和應用程式伺服器來講,是比較難實現橫向擴充的。資料庫的連線資源較寶貴且單機處理能力也有限,在高並發場景下,垂直分庫一定程度上能夠突破IO、連線數及單機硬體資源的瓶頸。
#針對資料量龐大的單張表(例如訂單表),依照某種規則(RANGE,HASH取模等),切分到多張表裡面去。但這些表還是在同一個庫中,所以庫層級的資料庫操作還是有IO瓶頸。不建議採用。
將單張表的資料切分到多個伺服器上去,每個伺服器具有對應的庫與表,只是表中資料集合不同。水平分庫分錶能夠有效的緩解單機和單庫的效能瓶頸和壓力,突破IO、連線數、硬體資源等的瓶頸。
RANGE
從0到10000一個表,10001到20000一個表;
HASH取模
一個商場系統,一般都是將用戶,訂單作為主表,然後將和它們相關的作為附表,這樣不會造成跨庫事務之類的問題。取用戶id,然後hash取模,分配到不同的資料庫。
地理區域
例如依照華東,華南,華北這樣來區分業務,七牛雲應該就是如此。
時間
依照時間切分,就是將6個月前,甚至一年前的資料切出去放到另外的一張表,因為隨著時間流逝,這些表的資料被查詢的機率變小,所以沒必要和「熱資料」放在一起,這個也是「冷熱資料分離」。
分庫分錶後,就成了分散式事務了。
如果依賴資料庫本身的分散式事務管理功能去執行事務,將付出高昂的效能代價;如果由應用程式去協助控制,形成程式邏輯上的事務,又會造成程式設計方面的負擔。
類似於group by,order by這樣的分組和排序語句無法使用
分庫分錶後表之間的關聯操作將受到限制,我們無法join位於不同分庫的表,也無法join分錶粒度不同的表, 結果原本一次查詢能夠完成的業務,可能需要多次查詢才能完成。粗略的解決方法:全局表:基礎數據,所有庫都拷貝一份。字段冗餘:這樣有些字段就不用join去查詢了。系統層組裝:分別查詢出所有,然後組裝起來,較複雜。
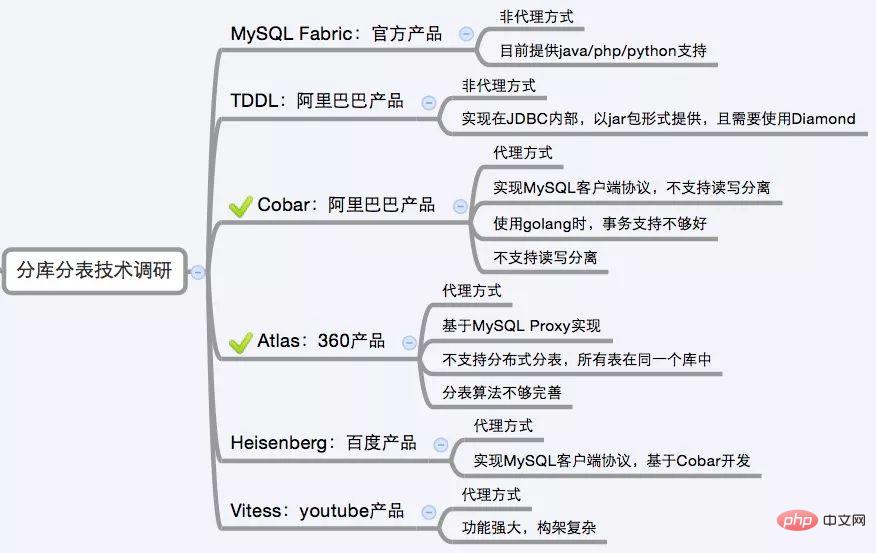
目前市面上的分庫分錶中間件相對較多,其中基於代理方式的有MySQL Proxy和Amoeba, 基於Hibernate框架的是Hibernate Shards,基於jdbc的有當當sharding-jdbc, 基於mybatis的類似maven插件式的有蘑菇街的蘑菇街TSharding, 透過重寫spring的ibatis template類別的Cobar Client。
還有一些大公司的開源產品:
我是程式設計師青戈,一個愛生活、愛分享的90後程式設計師。
本期關於Mysql分庫分庫分錶的介紹和解決方案介紹到這裡,希望能幫助到大家,後續更多Java面試類的文章請持續關注公眾號Java學習指南。
以上是今天終於把Mysql分庫分錶搞清楚了,面試可以吹牛了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!




































