

當大家不斷升級迭代自家大模型的時候,LLM(大語言模型)對上下文視窗的處理能力,也成為一個重要評估指標。
例如明星大模型GPT-4 支援32k token,相當於50 頁的文字;OpenAI 前成員創立的Anthropic 更是將Claude 處理token 能力提升到100k,約75,000 個單字,大概相當於一鍵總結《哈利波特》第一部。
在微軟最新的一項研究中,他們這次直接將 Transformer 擴展到 10 億 token。這為建模非常長的序列開闢了新的可能性,例如將整個語料庫甚至整個互聯網視為一個序列。
作為比較,普通人可以在 5 小時左右的時間內閱讀 100,000 個 token,並可能需要更長的時間來消化、記憶和分析這些資訊。 Claude 可以在不到 1 分鐘的時間內完成這些。要是換算成微軟的這項研究,將會是個驚人的數字。
 圖片
圖片
具體而言,研究提出了LONGNET,這是一種Transformer 變體,可以將序列長度擴展到超過10 億個token,而不會犧牲對較短序列的性能。文中也提出了 dilated attention,它能指數級擴展模型感知範圍。
LONGNET 有以下優點:
1)它具有線性計算複雜度;
2)它可以作為較長序列的分散式訓練器;
3)dilated attention 可以無縫取代標準注意力,並可以與現有基於Transformer 的最佳化方法無縫集成。
實驗結果表明,LONGNET 在長序列建模和一般語言任務上都表現出強烈的表現。
在研究動機方面,論文表示,最近幾年,擴展神經網路已經成為一種趨勢,許多表現良好的網路被研究出來。在這當中,序列長度作為神經網路的一部分,理想情況下,其長度應該是無限的。但現實卻往往相反,因而打破序列長度的限制將會帶來顯著的優勢:
然而,擴展序列長度面臨的主要挑戰是在計算複雜性和模型表達能力之間找到合適的平衡。
例如 RNN 風格的模型主要用於增加序列長度。然而,其序列特性限制了訓練過程中的並行化,而平行化在長序列建模中是至關重要的。
最近,狀態空間模型對序列建模非常有吸引力,它可以在訓練過程中作為 CNN 運行,並在測試時轉換為高效的 RNN。然而這類模型在常規長度上的表現不如 Transformer。
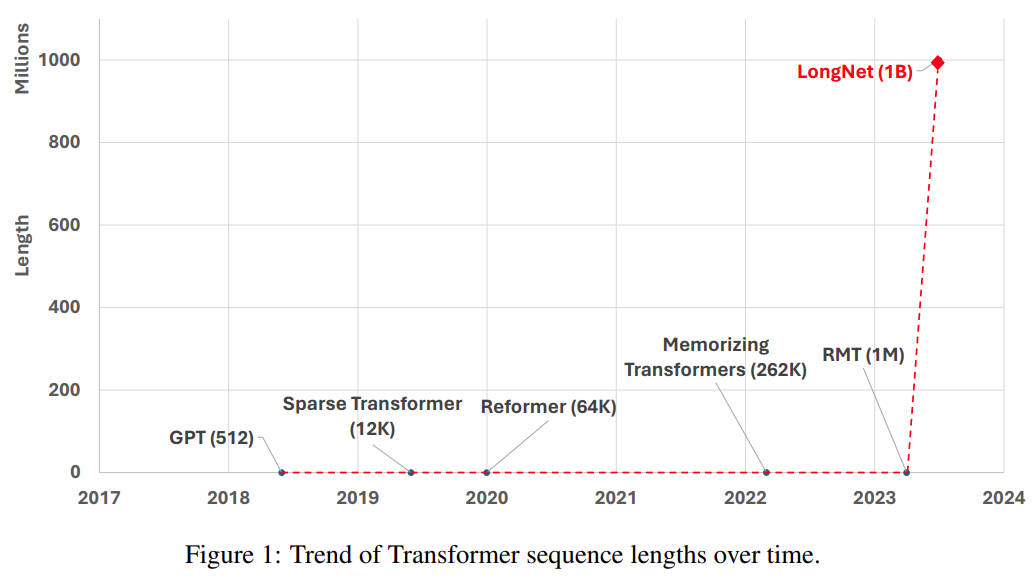
另一種擴展序列長度的方法是降低 Transformer 的複雜性,即自註意力的二次複雜性。現階段,一些高效率的基於 Transformer 的變體被提出,包括低秩注意力、基於核的方法、下採樣方法、基於檢索的方法。然而,這些方法尚未將 Transformer 擴展到 10 億 token 的規模(參見圖 1)。
 圖片
圖片
下表為不同計算方法的計算複雜度比較。 N 為序列長度,d 為隱藏維數。
 圖片
圖片
該研究的解決方案 LONGNET 成功地將序列長度擴展到 10 億個 token。具體來說,該研究提出一種名為 dilated attention 的新組件,並以 dilated attention 取代了 Vanilla Transformer 的注意力機制。通用的設計原則是注意力的分配隨著 token 和 token 之間距離的增加而呈指數級下降。該研究表明這種設計方法獲得了線性計算複雜度和 token 之間的對數依賴性。這解決了注意力資源有限和可訪問每個 token 之間的矛盾。
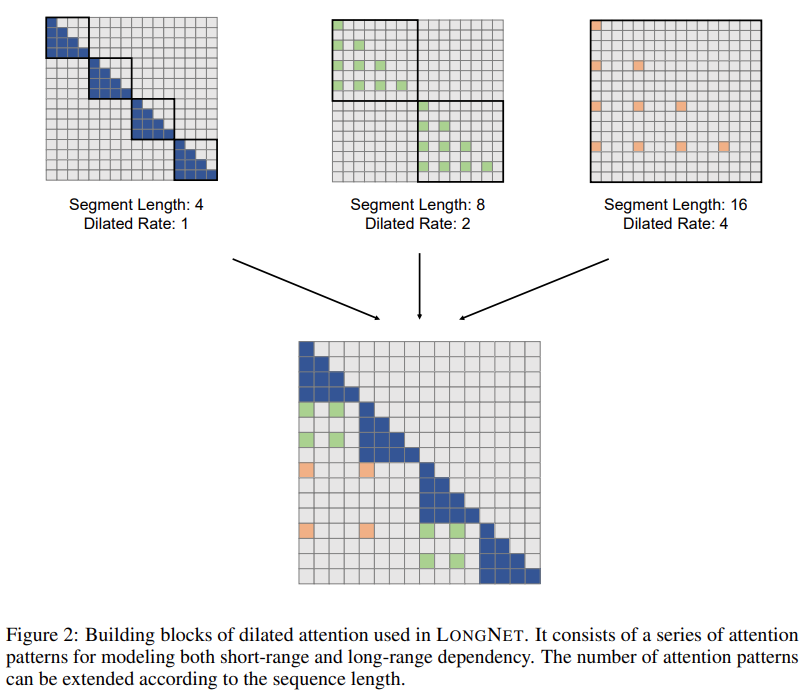 圖片
圖片
在實作過程中,LONGNET 可以轉換成一個密集Transformer,以無縫地支援針對Transformer 的現有最佳化方法(例如內核融合(kernel fusion)、量化和分佈式訓練)。利用線性複雜度的優勢,LONGNET 可以跨節點並行訓練,以分散式演算法打破計算和記憶體的限制。
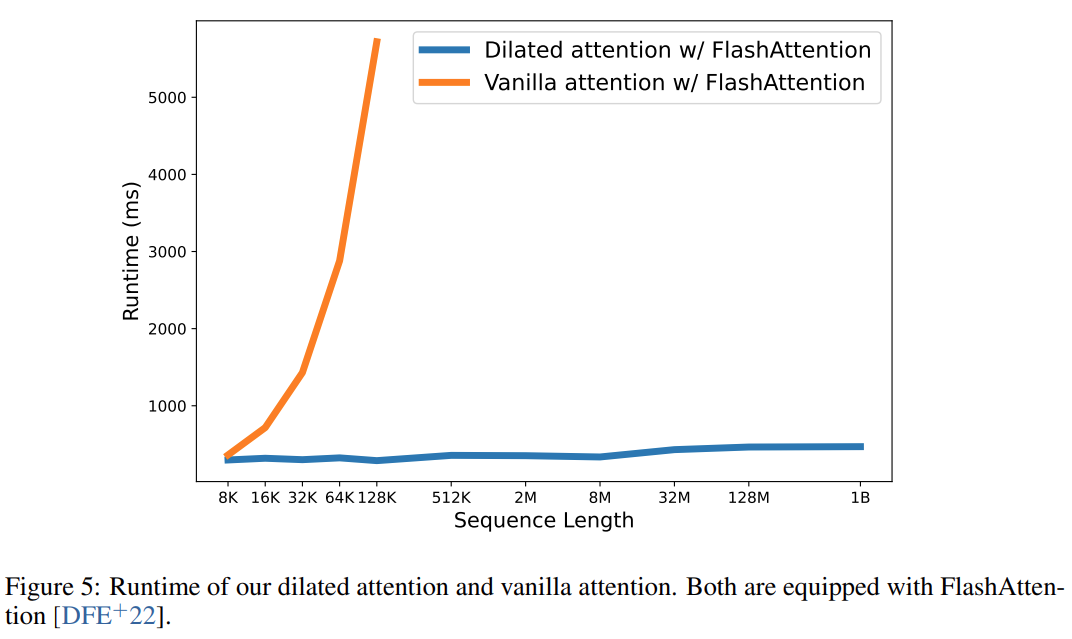
最終,該研究有效地將序列長度擴大到 1B 個 token,而且運行時(runtime)幾乎是恆定的,如下圖所示。相較之下,Vanilla Transformer 的運作時則會受到二次複雜度的影響。
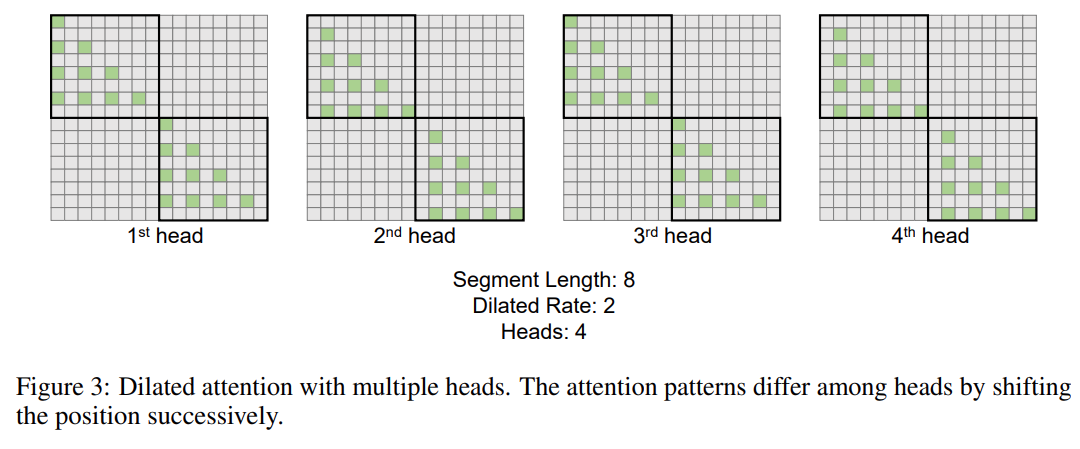
該研究進一步引入了多頭 dilated attention 機制。如下圖 3 所示,該研究透過對查詢 - 鍵 - 值對的不同部分進行稀疏化,在不同的頭之間進行不同的計算。
 圖片
圖片
分散式訓練
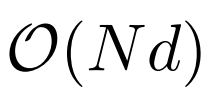 雖然dilated attention 的計算複雜度已經大幅降低到
雖然dilated attention 的計算複雜度已經大幅降低到
,但由於計算和內存的限制,在單個GPU 設備上將序列長度擴展到百萬級別是不可行的。有一些用於大規模模型訓練的分散式訓練演算法,如模型並行[SPP 19]、序列並行[LXLY21, KCL 22] 和pipeline 並行[HCB 19],然而這些方法對於LONGNET 來說是不夠的,特別是當序列維度非常大時。
本研究利用 LONGNET 的線性運算複雜度來進行序列維度的分散式訓練。下圖 4 展示了在兩個 GPU 上的分散式演算法,還可以進一步擴展到任意數量的裝置。 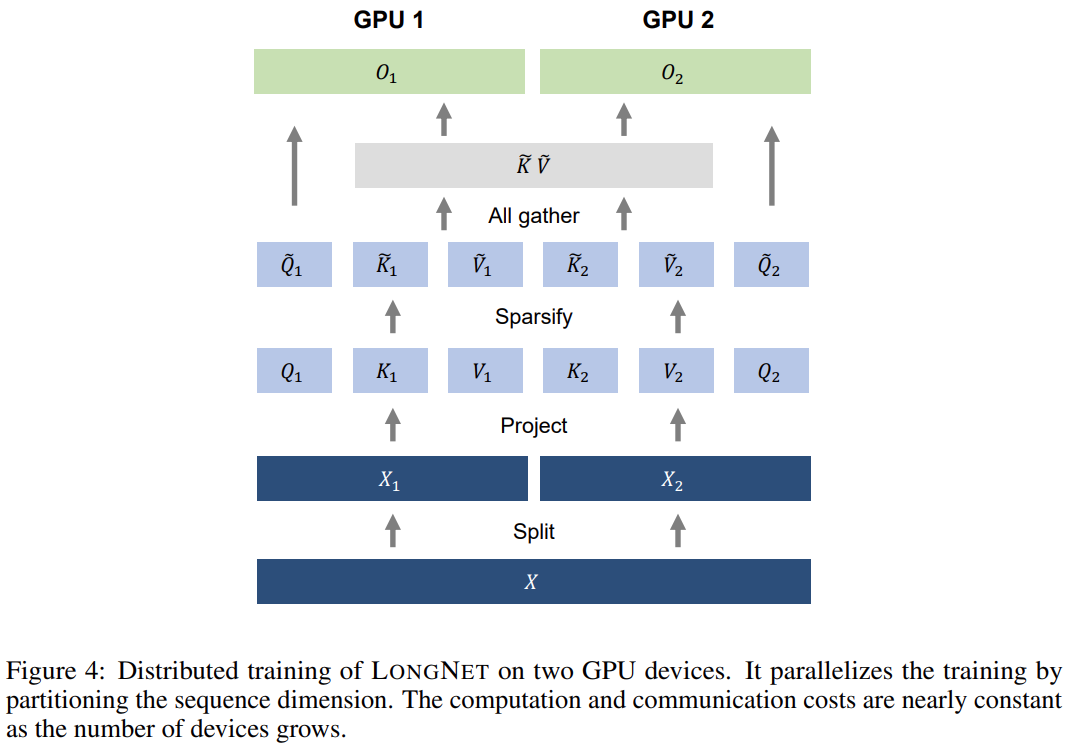
#該研究將LONGNET與vanilla Transformer 和稀疏Transformer 進行了比較。架構之間的差異是注意力層,而其他層保持不變。研究人員將這些模型的序列長度從 2K 擴展到 32K,同時減少 batch 大小,以確保每個 batch 的 token 數量不變。
表 2 總結了這些模型在 Stack 資料集上的結果。研究使用複雜度作為評估指標。這些模型使用不同的序列長度進行測試,範圍從 2k 到 32k 不等。當輸入長度超過模型支援的最大長度時,研究實現了分塊因果注意力(blockwise causal attention,BCA)[SDP 22],這是一種最先進的語言模型推理的外推方法。
此外,研究刪除了絕對位置編碼。首先,結果表明,在訓練過程中增加序列長度一般會得到更好的語言模型。其次,在長度遠大於模型支持的情況下,推理中的序列長度外推法並不適用。最後,LONGNET 一直優於基準模型,證明了其在語言建模中的有效性。 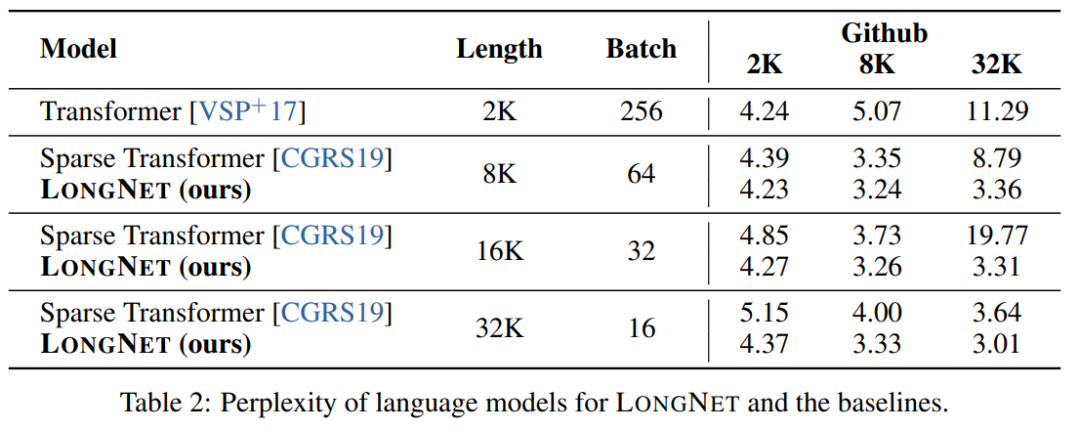
序列長度的擴展曲線
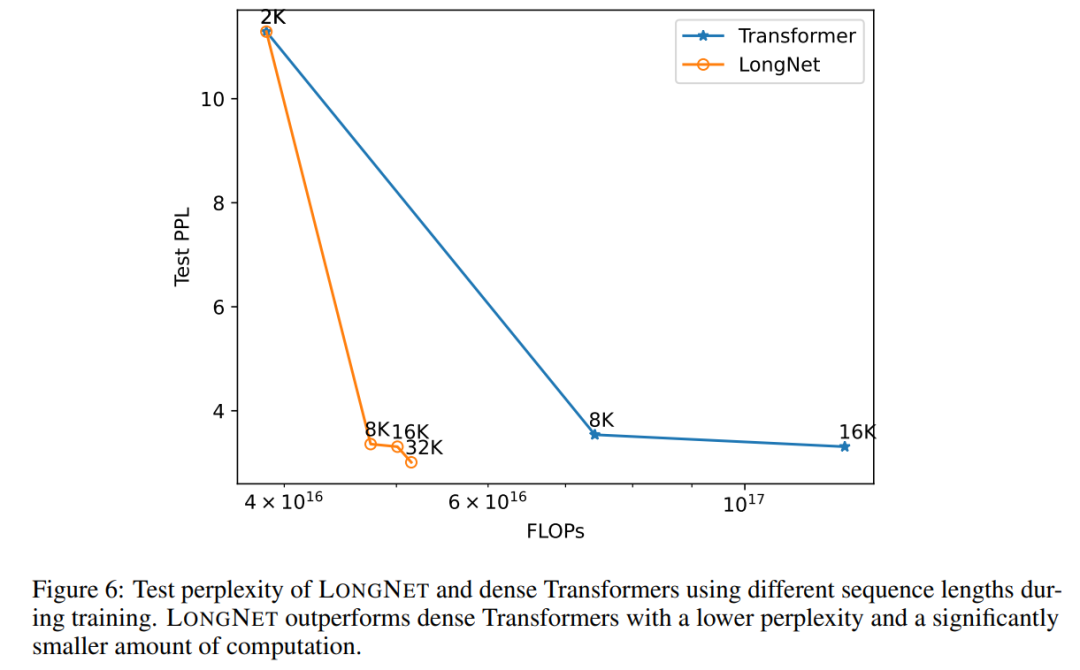
#########圖 6 繪製了 vanilla transformer 和 LONGNET 的序列長度擴展曲線。該研究透過計算矩陣乘法的總 flops 來估計計算量。結果表明,vanilla transformer 和 LONGNET 都能從訓練中獲得更大的上下文長度。然而,LONGNET 可以更有效地擴展上下文長度,以較小的計算量實現較低的測試損失。這證明了較長的訓練輸入比外推法更具優勢。實驗表明,LONGNET 是一種更有效的擴展語言模型中上下文長度的方法。這是因為 LONGNET 可以更有效地學習較長的依賴關係。
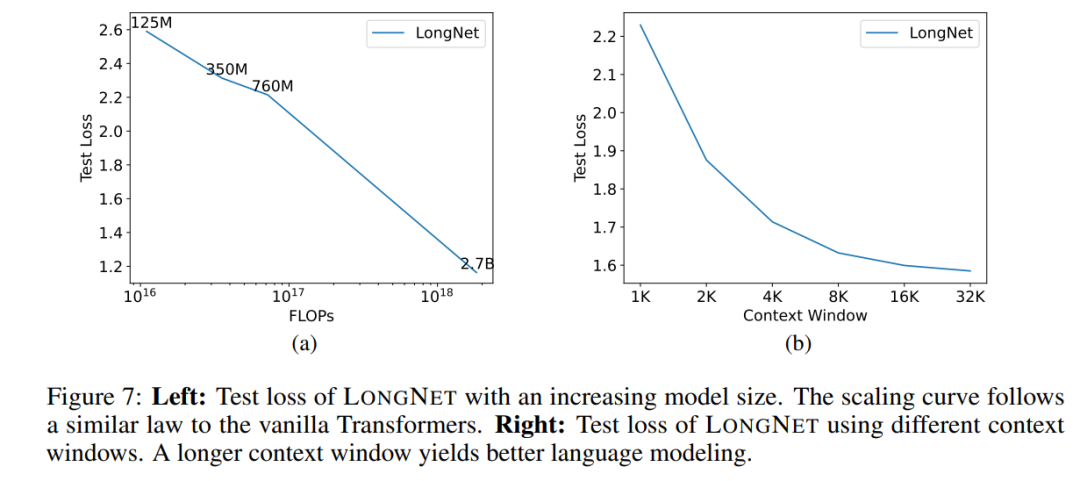
##大型語言模型的一個重要屬性是:損失隨著計算量的增加呈冪律擴展。為了驗證 LONGNET 是否仍遵循類似的擴展規律,該研究以不同的模型規模(從 1.25 億到 27 億個參數) 訓練了一系列模型。 27 億的模型是用 300B 的 token 訓練的,而其餘的模型則用到了大約 400B 的 token。圖 7 (a) 繪製了 LONGNET 關於計算的擴展曲線。該研究在相同的測試集上計算了複雜度。這證明了 LONGNET 仍然可以遵循冪律。這也意味著 dense Transformer 不是擴展語言模型的先決條件。此外,可擴展性和效率都是由 LONGNET 獲得的。
長上下文prompt
######Prompt 是引導語言模型並為其提供額外資訊的重要方法。該研究透過實驗來驗證 LONGNET 是否能從較長的上下文提示視窗中獲益。 ############研究保留了一段前綴(prefixes)作為 prompt,並測試其後綴(suffixes)的困惑度。並且,研究過程中,逐漸將 prompt 從 2K 擴展到 32K。為了進行公平的比較,保持後綴的長度不變,而將前綴的長度增加到模型的最大長度。圖 7 (b) 報告了測試集上的結果。它表明,隨著上下文視窗的增加,LONGNET 的測試損失逐漸減少。這證明了 LONGNET 在充分利用長語境來改進語言模型方面的優越性。 ######
以上是微軟新出熱乎論文:Transformer擴展到10億token的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















