

當前大語言模型 (Large Language Models, LLMs) 如 GPT4 在遵循給定圖像的開放式指令方面表現出了出色的多模態能力。然而,這些模型的性能嚴重依賴於對網路結構、訓練資料和訓練策略等方案的選擇,但這些選擇並沒有在先前的文獻中被廣泛討論。此外,目前也缺乏合適的基準 (benchmarks) 來評估和比較這些模型,限制了多模態 LLMs 的 發展。
 圖片
圖片
#在這篇文章中,作者從定量和定性兩個方面對此類模型的訓練進行了系統和全面的研究。設定了20 多種變體,對於網路結構,比較了不同的LLMs 主幹和模型設計;對於訓練數據,研究了數據和採樣策略的影響;在指令方面,探討了多樣化提示對模型指令跟隨能力的影響。對於 benchmarks ,文章首次提出包括影像和視訊任務的開放式視覺問答評估集 Open-VQA。
基於實驗結論,作者提出了 Lynx,與現有的開源GPT4-style 模型相比,它在表現出最準確的多模態理解能力的同時,也保持了最佳的多模態生成能力。
不同於典型的視覺語言任務,評估GPT4-style 模型的主要挑戰在於平衡文本生成能力和多模態理解準確度兩個面向的表現。為了解決這個問題,作者提出了一個包含視訊和圖像資料的新 benchmark Open-VQA,並對目前的開源模型進行了全面的評估。
具體來說,採用了兩種量化評估方案:
為了深入研究多模態LLMs 的訓練策略,作者主要從網路結構(前綴微調/ 交叉注意力)、訓練資料(資料選擇及組合比例)、指示(單一指示/ 多樣化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、影像像素(420/224)等多個面向設定了二十多種變體,透過實驗得出了以下主要結論:
作者提出了 Lynx(猞猁)—— 進行了兩階段訓練的prefix-finetuning 的GPT4-style 模型。在第一階段,使用大約 120M 圖像- 文字對來對齊視覺和語言嵌入(embeddings) ;在第二階段,使用20 個圖像或視頻的多模態任務以及自然語言處理(NLP ) 資料來調整模型的指令遵循能力。
 圖片
圖片
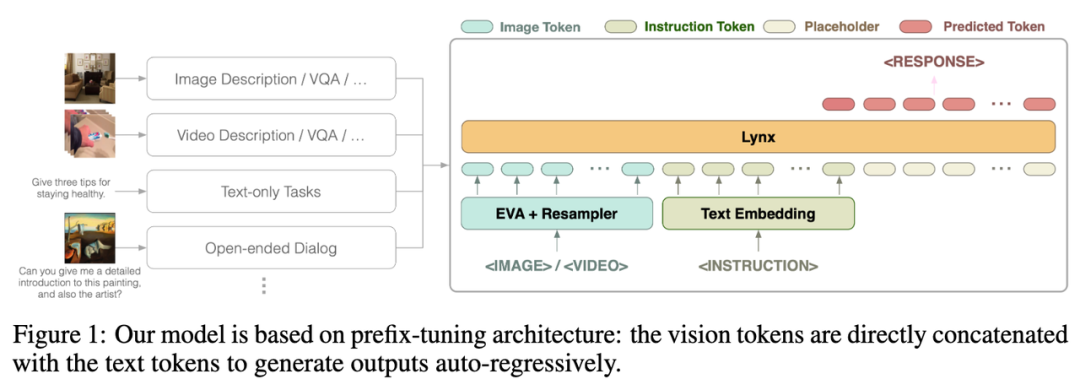
Lynx 模型的整體結構如上圖 Figure 1 所示。
視覺輸入經過視覺編碼器處理後得到視覺令牌(tokens) $$W_v$$,經過映射後與指令tokens $$W_l$$ 拼接作為LLMs 的輸入,在本文中將此結構稱為「prefix-finetuning」以區別於如Flamingo [3] 所使用的 cross-attention 結構。
此外,作者發現,透過在凍結 (frozen) 的 LLMs 某些層後添加適配器 (Adapter) 可以進一步降低訓練成本。
作者評估了現有的開源多模態LLMs 模型在 Open-VQA、Mme [4]及OwlEval 人工測評上的表現(結果見後文圖表,評估細節見論文)。可以看到 Lynx 模型在 Open-VQA 影像和視訊理解任務、OwlEval 人工測評及 Mme Perception 類別任務中都取得了最好的表現。 其中,InstructBLIP 在多數任務中也實現了高效能,但其回應過於簡短,相較而言,在大多數情況下Lynx 模型在給出正確的答案的基礎上提供了簡明的理由來支撐回复,這使得它對用戶更友好(部分cases 見後文Cases 展示部分)。
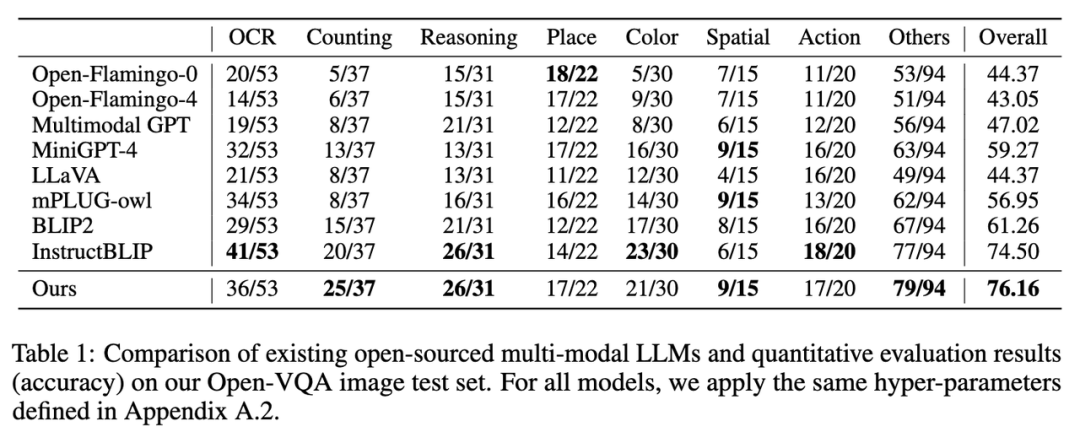
1. 在Open-VQA 影像測試集上的指標結果如下圖Table 1 所示:
 圖片
圖片
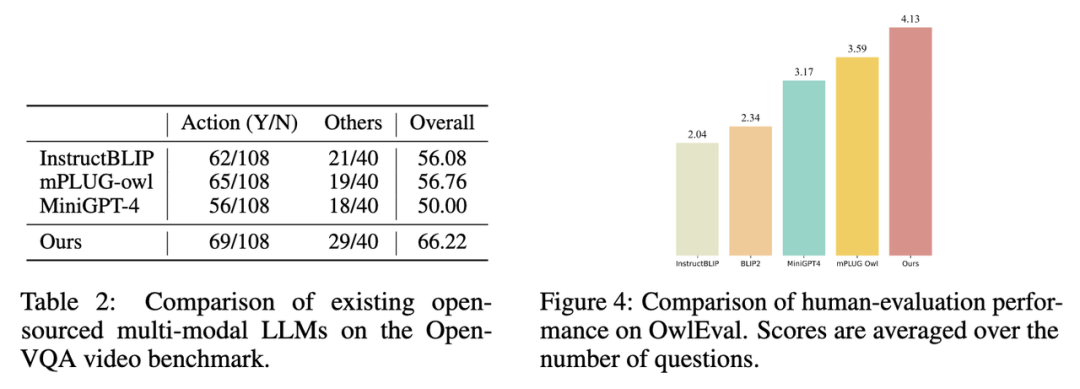
2. 在Open-VQA 影片測試集上的指標結果如下圖Table 2 所示。
 圖片
圖片
3. 選取 Open-VQA 中得分排名靠前的模型進行 OwlEval 評估集上的人工效果評估,其結果如上圖 Figure 4 所示。從人工評估結果可以看出 Lynx 模型具有最佳的語言生成效能。
 圖片
圖片
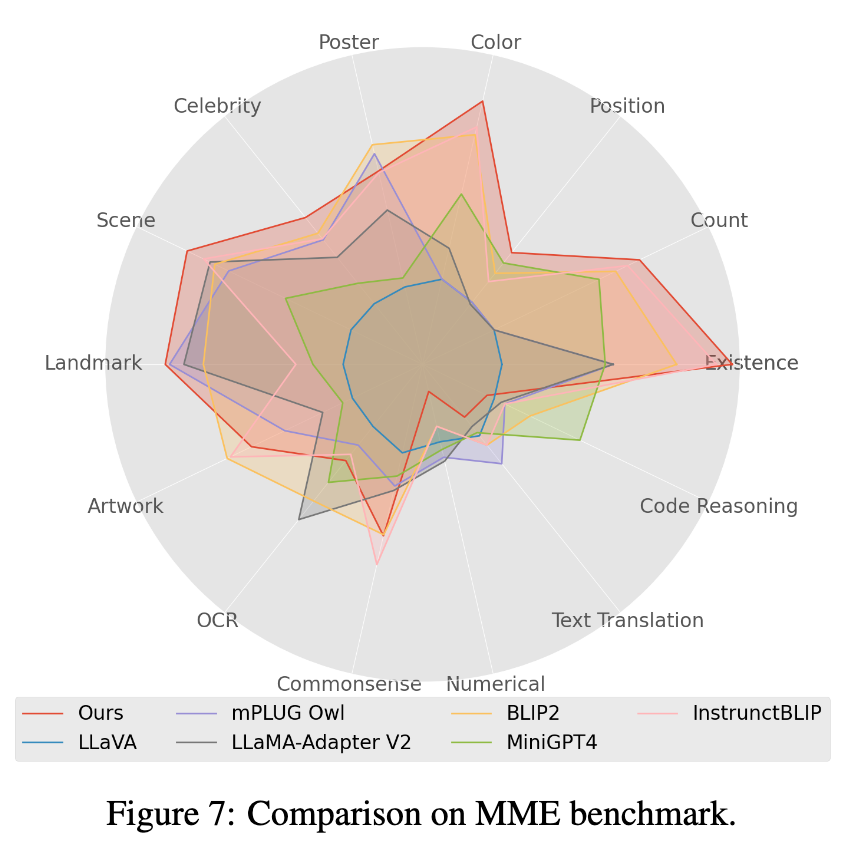
#4. 在Mme benchmark 測試中,Perception 類別任務獲得最好的表現,其中 14 類別子任務中有7 個表現最優。 (詳細結果請見論文附錄)
#Open-VQA 圖片cases

OwlEval cases

Open-VQA 影片case

在本文中,作者透過二十多種多模態LLMs 變種的實驗,確定了以prefix-finetuning 為主要結構的Lynx 模型並給出開放式答案的Open-VQA 評估方案。實驗結果顯示 Lynx 模型表現最準確的多模態理解準確度的同時,維持了最佳的多模態生成能力。
以上是位元組團隊提出猞猁Lynx模型:多模態LLMs理解認知生成類別榜單SoTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















