

6月14日,騰訊Robotics X機器人實驗室發表了智能體研究的最新進展,透過將前沿的預訓練AI模型和強化學習技術應用到機器人控制領域,讓機器狗Max 的靈活性和自主決策能力大幅提升。
讓機器狗像人類和動物一樣靈活且穩定的運動,是機器人研究領域長期追求的目標,深度學習技術的不斷進步,使得讓機器透過「學習」來掌握相關能力,學會應對複雜多變的環境變得可行。
引入預訓練與強化學習:讓機器狗更靈活
#騰訊Robotics X機器人實驗室透過引入預訓練模型和強化學習技術,可以讓機器狗分階段進行學習,有效的將不同階段的技能、知識累積並儲存下來,讓機器人在解決新的複雜任務時,不必重新學習,而是可以復用已經學會的姿態、環境感知、策略規劃多個層面的知識,進行“舉一反三”,靈活應對複雜環境


這一系列的學習分為三個階段:
第一階段透過遊戲技術中常使用動作捕捉系統,研究員收集真狗的運動姿態數據,包括走、跑、跳、站立等動作,並利用這些數據,在模擬器中構建了一個模仿學習任務,再將這些資料中的資訊抽象化並壓縮到深度神經網路模型中。這些模型不僅能夠準確地涵蓋收集的動物運動姿態訊息,而且具有相當高的可解釋性。
騰訊Robotics X機器人實驗室和騰訊遊戲合作,以遊戲技術提升了模擬引擎的準確和高效,同時遊戲製作和研發過程中累積了多元的動捕素材。這些技術和數據在基於物理模擬的智能體訓練和真實世界機器人策略部署中扮演了一定的輔助角色。
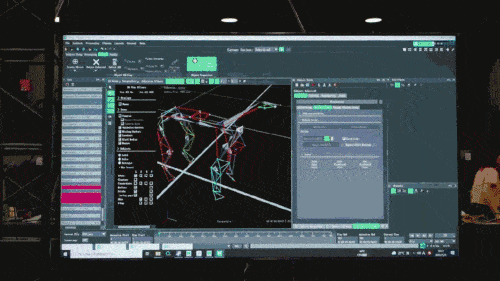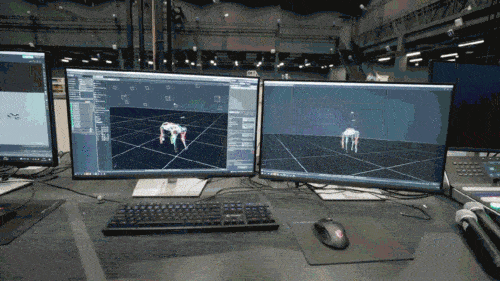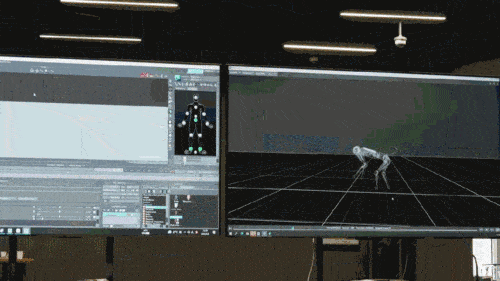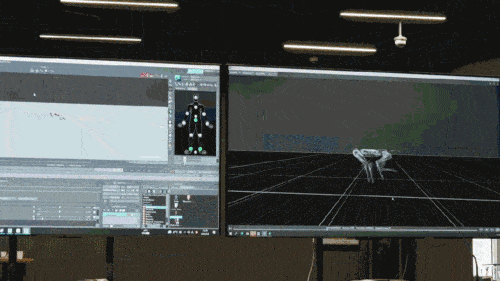

神經網路模型只接受機器狗的本體感知資訊(如馬達狀態)作為輸入,以模仿學習的方式進行訓練。在下一步中,模型會融合周圍環境的感知數據,例如利用其他感測器來探測腳底下的障礙物。
第二階段,透過額外的網路參數將第一階段掌握的機器狗靈動姿態與外界感知連結在一起,使得機器狗能夠透過已經學會的靈動姿態來應對外界環境。當機器狗適應了多種複雜的環境後,這些將靈動姿態與外界感知連結在一起的知識也會被固化下來,存在著神經網路結構中。



第三階段,利用上述兩個預訓練階段所獲得的神經網絡,機器狗才有前提和機會來聚焦解決最上層的策略學習問題,最終具備端到端解決複雜的任務的能力。在第三階段中,額外添加的網路將會收集與複雜任務相關的數據,例如在遊戲中獲取對手和旗幟的資訊。此外,透過綜合分析所有信息,負責策略學習的神經網路會學習出針對任務的高階策略,例如往哪個方向跑動,預判對手的行為來決定是否繼續追逐等等。
上述每一階段學習到的知識都可以擴充和調整,不需要重新學習,因此可以不斷積累,持續學習。
機器狗障礙追逐比賽 :擁有自主決策與控制能力
#為了測試Max所掌握的這些新技能,研究員受到障礙追逐比賽「World Chase Tag「的啟發,設計了一個雙狗障礙追逐的遊戲。 World Chase Tag是一個競技性障礙追逐賽組織,2014年創立於英國,由民間兒童追逐遊戲標準化而來。一般來說,障礙追逐比賽每輪次由兩名互為對手的運動員參加,一名是追擊者(稱為攻方),一名是躲避者(稱為守方),當一名運動員在整個追逐回合中(即20秒)成功躲避對手(即未發生觸碰)時,團隊將獲得一分。在預定的追逐回合數中得分最多的戰隊贏得比賽。
機器狗障礙追逐比賽的場地尺寸為4.5米 x 4.5米,上面分佈著一些障礙物。遊戲起始,兩個MAX機器狗會被放置在場地中的隨機位置,且隨機一個機器狗被賦予追擊者的角色,另一個為躲避者,同時,場地中會在隨機位置擺放一個旗子。
躲避者的目標是盡可能接近旗子,但要確保不被追擊者捉住。追擊者的任務則是抓住躲避者。如果躲避者在被抓到之前成功觸碰到旗子,則兩個機器狗的角色會瞬間發生互換,同時旗子會重新出現在另一個隨機的位置。當躲避者被當前的追擊者抓住並且此時扮演追擊者角色的機器狗獲勝時,遊戲即告結束。在所有遊戲中,兩隻機器狗的平均前進速度限制為0.5m/s。
從這個遊戲看來,在基於預訓練好的模型下,機器狗透過深度強化學習,已經具備一定的推理和決策能力:
例如,當追擊者意識到自己在躲避者碰到旗子之前已經無法追上它的時候,追擊者就會放棄追擊,而是在遠離躲避者的位置徘徊,目的是為了等待下一個重置的旗子出現。
另外,當追擊者即將抓到躲避者的最後時刻,牠喜歡跳起來向著躲避者做出一個"撲"的動作,非常類似動物捕捉獵物時候的行為,或者躲避者在快要接觸旗子的時候也會表現出同樣的行為。這些都是機器狗為了確保自己的勝利所採取的主動加速措施。
據介紹,遊戲中機器狗的所有控制策略都是神經網路策略,在模擬中進行學習並透過zero-shot transfer(零調整遷移),讓神經網路模擬人類的推理方式,來辨識從未見過的新事物,並把這些知識部署到真實機器狗上。例如下圖所示,機器狗在預訓練模型中學會的躲避障礙物的知識,被用在遊戲中,即使帶有障礙物的場景並未在Chase Tag Game的虛擬世界進行訓練(虛擬世界中僅訓練了平地下的遊戲場景),機器狗也能順利完成任務。
騰訊Robotics X機器人實驗室長期致力於機器人尖端技術的研究,以先前在機器人本體、運動、控制領域等領先技術和積累為基礎,研究員們也在嘗試將前沿的預訓練模型和深度強化學習技術引進機器人領域,提升機器人的控制能力,讓其更有彈性,也為機器人走入現實生活,服務人類打下了堅實的基礎。
以上是騰訊機器狗進化:透過深度學習掌握自主決策能力的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















