

自監督學習(SSL)在最近幾年取得了很大的進展,在許多下游任務上幾乎已經達到監督學習方法的水平。但是,由於模型的複雜性以及缺乏有標註訓練資料集,我們也一直難以理解學習到的表徵及其底層的工作機制。此外,自監督學習中使用的 pretext 任務通常與特定下游任務的直接關係不大,這進一步增大了解釋所學習到的表徵的複雜性。而在監督式分類中,所學到的表徵的結構往往很簡單。
相比於傳統的分類任務(目標是準確將樣本歸入特定類別),現代SSL 演算法的目標通常是最小化包含兩大成分的損失函數:一是將增強過的樣本進行聚類(不變性約束),二是防止表徵坍縮(正則化約束)。舉個例子,對於同一樣本經過不同增強之後的數據,對比式學習方法的目標是讓這些樣本的分類結果一樣,同時又要能區分經過增強之後的不同樣本。另一方面,非對比式方法要使用正規化器(regularizer)來避免表徵坍縮。
自監督學習可以利用輔助任務(pretext)無監督資料中挖掘自身的監督訊息,透過這種建構的監督資訊對網路進行訓練,從而可以學習到對下游任務有價值的表徵。近日,圖靈獎得主 Yann LeCun 在內的多位研究者發布了一項研究,宣稱對自監督學習進行了逆向工程,讓我們得以了解其訓練過程的內部行為。

#論文網址:https://arxiv.org/abs/2305.15614v2
#這篇論文透過一系列精心設計的實驗對使用SLL 的表徵學習進行了深度分析,幫助人們理解訓練期間的聚集過程。具體來說,研究揭示增強的樣本會表現出高度聚類的行為,這會圍繞共享相同圖像的增強樣本的含義嵌入形成質心。更出人意料的是,研究者觀察到:即便缺乏有關目標任務的明確訊息,樣本也會根據語義標籤發生聚類。這表明 SSL 有能力根據語義相似性對樣本進行分組。
由於自監督學習(SSL)通常用於預訓練,讓模型做好準備適應下游任務,這帶來了一個關鍵問題: SSL 訓練會對所學到的表徵產生什麼影響?具體來說,訓練期間 SSL 的底層工作機制是怎麼樣的,這些表徵函數能學到什麼類別?
為了調查這些問題,研究者在多種設定上訓練了 SSL 網路並使用不同的技術分析了它們的行為。
資料和增強功能:本文提到的所有實驗都使用了 CIFAR100 影像分類資料集。為了訓練模型,研究者使用了 SimCLR 中提出的影像增強協定。每一個 SSL 訓練 session 都執行 1000 epoch,使用了具有動量的 SGD 優化器。
骨幹架構:所有的實驗都使用了 RES-L-H 架構作為骨幹,再加上了兩層多層感知器(MLP)投射頭。
線性探測(linear probing):為了評估從表徵函數中提取給定離散函數(例如類別)的有效性,這裡使用的方法是線性探測。這需要基於該表徵訓練一個線性分類器(也稱為線性探針),這需要用到一些訓練樣本。
樣本層面的分類:為了評估樣本層面的可分離性,研究者創建了一個專門的新資料集。
其中訓練資料集包含來自 CIFAR-100 訓練集的 500 張隨機影像。每張圖像都代表一個特定類別並會進行 100 種不同的增強。因此,訓練資料集包含 500 個類別的共 50000 個樣本。測試集依然是用這 500 張影像,但要使用 20 種不同的增強,這些增強都來自同一分佈。因此,測試集中的結果由 10000 個樣本組成。為了在樣本層面衡量給定表徵函數的線性或NCC(nearest class-center / 最近類別中心)準確度,這裡採用的方法是先使用訓練資料計算出一個相關的分類器,然後再在對應測試集上評估其準確率。
在幫助分析深度學習模型方面,聚類過程一直以來都發揮著重要作用。為了直觀地理解 SSL 訓練,圖 1 透過 UMAP 視覺化展示了網路的訓練樣本的嵌入空間,其中包含訓練前後的情況並分了不同層級。
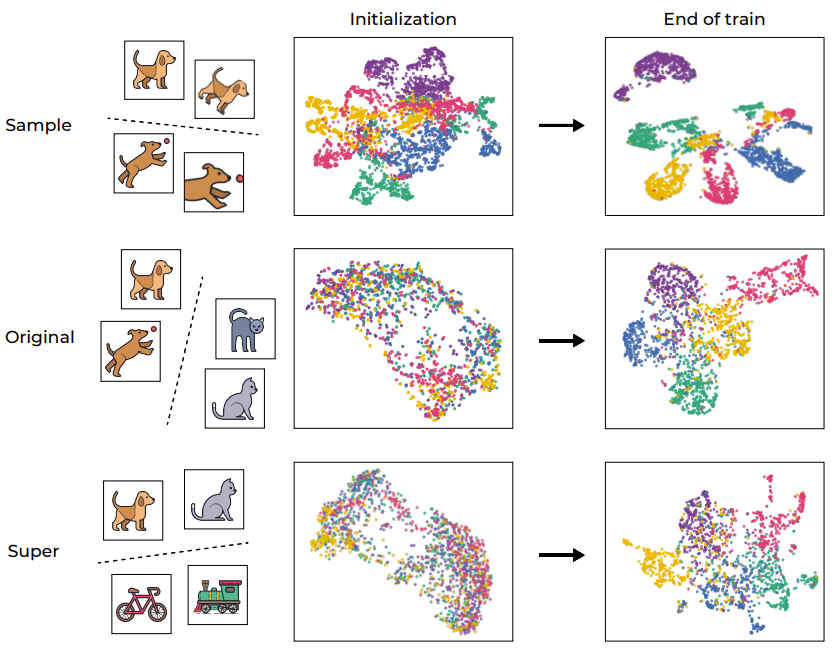
#圖1:SSL 訓練引起的語意聚類
如預期的那樣,訓練過程成功地在樣本層面上對樣本進行了聚類,映射了同一圖像的不同增強(如第一行圖示)。考慮到目標函數本身就會鼓勵這種行為(透過不變性損失項),因此這樣的結果倒是不意外。然而,更值得注意的是,該訓練過程也會根據標準 CIFAR-100 資料集的原始「語意類別」進行聚類,即便在該訓練過程期間缺乏標籤。有趣的是,較高的層級(超類別)也能被有效聚集。這個例子表明,儘管訓練流程直接鼓勵的是樣本層面的聚類,但 SSL 訓練的資料表徵也會在不同層面上根據語義類別來進行聚類。
為了進一步量化這個聚類過程,研究者使用 VICReg 訓練了一個 RES-10-250。研究者衡量的是 NCC 訓練準確度,既有樣本層面的,也有基於原始的類別。值得注意的是,SSL 訓練的表徵在樣本層面上展現出了神經坍縮(neural collapse,即NCC 訓練準確度接近於1.0),然而在語義類別方面的聚類也很顯著(在原始目標上約為0.41)。
如圖2 左圖所示,涉及增強(網路直接基於其訓練的)的聚類過程大部分都發生在訓練過程初期,然後陷入停滯;而在語義類別方面的聚集(訓練目標中並未指定)則會在訓練過程中持續提升。
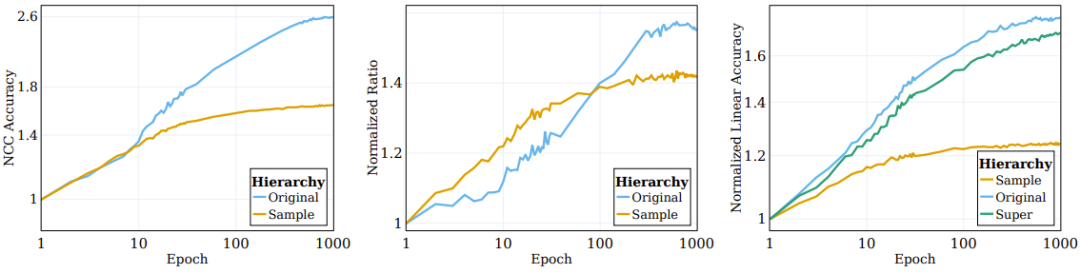
圖2:SSL 演算法根據語意目標對資料的聚類
之前有研究者觀察到,監督式訓練樣本的頂層嵌入會逐漸向一個類質心的結構收斂。為了更好地理解 SSL 訓練的表徵函數的聚集性質,研究者調查了 SSL 過程中的類似情況。其 NCC 分類器是一種線性分類器,其表現不會超過最佳的線性分類器。透過評估 NCC 分類器與同樣資料上訓練的線性分類器的準確度之比,能夠在不同粒度層級上研究資料聚類。圖 2 的中圖給出了樣本層面類別和原始目標類別上的這一比值的變化情況,其值根據初始化的值進行了歸一化。隨著 SSL 訓練的進行,NCC 準確度和線性準確度之間的差距會變小,這說明增強後的樣本會根據其樣本身份和語義屬性逐漸提升聚類水平。
此外,圖也說明,樣本層面的比值起初會高一些,這說明增強後的樣本會根據它們的身份進行聚類,直到收斂至質心(NCC 準確度和線性準確度的比值在100 epoch 時≥ 0.9)。但是,隨著訓練持續,樣本層面的比值會飽和,而類別層面的比值會持續成長並收斂至 0.75 左右。這說明增強後的樣本首先會根據樣本身分進行聚類,實現之後,再根據高層次的語意類別進行聚類。
SSL 训练中隐含的信息压缩
如果能有效进行压缩,那么就能得到有益又有用的表征。但 SSL 训练过程中是否会出现那样的压缩却仍是少有人研究的课题。
为了了解这一点,研究者使用了互信息神经估计(Mutual Information Neural Estimation/MINE),这种方法可以估计训练过程中输入与其对应嵌入表征之间的互信息。这个度量可用于有效衡量表征的复杂度水平,其做法是展现其编码的信息量(比特数量)。
图 3 的中图报告了在 5 个不同的 MINE 初始化种子上计算得到的平均互信息。如图所示,训练过程会有显著的压缩,最终形成高度紧凑的训练表征。
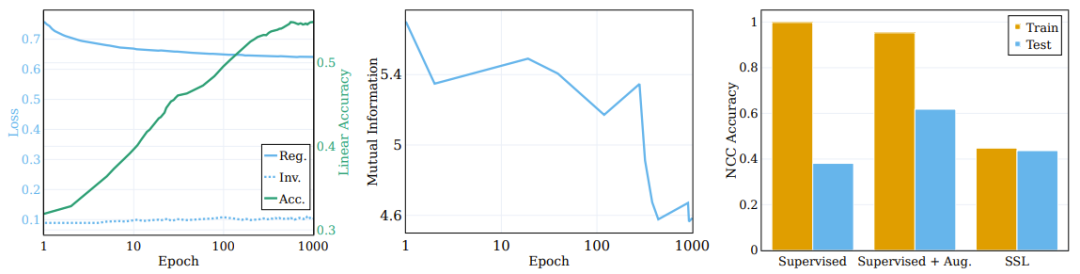
左侧图表显示了 SSL 训练模型在训练过程中正则化和不变性损失的变化以及原始目标线性测试准确度。(中)训练期间输入和表征之间的互信息的压缩。(右)SSL 训练学习聚类的表征。
正则化损失的作用
目标函数包含两项:不变性和正则化。不变性项的主要功能是强化同一样本的不同增强的表征之间的相似性。而正则化项的目标是帮助防止表征坍缩。
为了探究这些分量对聚类过程的作用,研究者将目标函数分解为了不变性项和正则化项,并观察它们在训练过程中的行为。比较结果见图 3 左图,其中给出了原始语义目标上的损失项的演变以及线性测试准确度。不同于普遍流行的想法,不变性损失项在训练过程中并不会显著改善。相反,损失(以及下游的语义准确度)的改善是通过降低正则化损失实现的。
由此可以得出结论:SSL 的大部分训练过程都是为了提升语义准确度和所学表征的聚类,而非样本层面的分类准确度和聚类。
从本质上讲,这里的发现表明:尽管自监督学习的直接目标是样本层面的分类,但其实大部分训练时间都用于不同层级上基于语义类别的数据聚类。这一观察结果表明 SSL 方法有能力通过聚类生成有语义含义的表征,这也让我们得以了解其底层机制。
监督学习和 SSL 聚类的比较
深度网络分类器往往是基于训练样本的类别将它们聚类到各个质心。但学习得到的函数要能真正聚类,必须要求这一性质对测试样本依然有效;这是我们期望得到的效果,但效果会差一点。
这里有一个有趣的问题:相比于监督学习的聚类,SSL 能在多大程度上根据样本的语义类别来执行聚类?图 3 右图报告了在不同场景(使用和不使用增强的监督学习以及 SSL)的训练结束时的 NCC 训练和测试准确度比率。
尽管监督式分类器的 NCC 训练准确度为 1.0,显著高于 SSL 训练的模型的 NCC 训练准确度,但 SSL 模型的 NCC 测试准确度却略高于监督式模型的 NCC 测试准确度。这说明两种模型根据语义类别的聚类行为具有相似的程度。有意思的是,使用增强样本训练监督式模型会稍微降低 NCC 训练准确度,却会大幅提升 NCC 测试准确度。
语义类别是根据输入的内在模式来定义输入和目标的关系。另一方面,如果将输入映射到随机目标,则会看到缺乏可辨别的模式,这会导致输入和目标之间的连接看起来很任意。
研究者也探討了隨機性對模型學習所需目標的熟練程度的影響。為此,他們建立了一系列具有不同隨機度的目標系統,然後檢查了隨機度對所學表徵的影響。他們在用於分類的相同資料集上訓練了一個神經網路分類器,然後使用其不同 epoch 的目標預測作為具有不同隨機度的目標。在 epoch 0 時,網路是完全隨機的,會得到確定的但看似任意的標籤。隨著訓練進行,其函數的隨機性下降,最終得到與基本真值目標對齊的目標(可視為完全不隨機)。這裡將隨機度歸一化到 0(完全不隨機,訓練結束時)到 1(完全隨機,初始化時)之間。
圖 4 左圖展示了不同隨機度目標的線性測試準確度。每條線都對應於不同隨機度的 SSL 不同訓練階段的準確度。可以看到,在訓練過程中,模型會更有效率地捕捉與「語意」目標(更低隨機度)更接近的類別,同時在高隨機度的目標上沒有表現出顯著的表現改進。
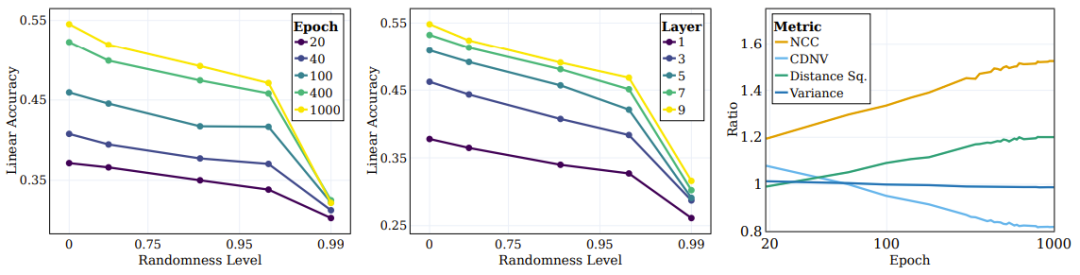
#圖4:SSL 持續學習語意目標,而非隨機目標
深度學習的一個關鍵問題是理解中間層對分類不同類型類別的作用和影響。例如,不同的層會學到不同類型的類別嗎?研究者也探討了這個問題,其做法是在訓練結束時不同目標隨機度下評估不同層表徵的線性測試準確度。如圖 4 中圖所示,隨著隨機度下降,線性測試準確度持續提升,更深度的層在所有類別類型上都表現更優,而對於接近語義類別的分類,性能差距會更大。
研究者也使用了其它一些測量來評估聚類的品質:NCC 準確度、CDNV、平均每類變異數、類別平均值之間的平均平方距離。為了衡量表徵隨訓練的改進情況,研究者為語意目標和隨機目標計算了這些指標的比率。圖 4 右圖展示了這些比率,結果顯示相比於隨機目標,表徵會更偏向根據語意目標來聚類資料。有趣的是,可以看到 CDNV(變異數除以平方距離)會降低,原因只是平方距離的下降。變異數比率在訓練期間相當穩定。這會鼓勵聚類之間的間距拉大,這現像已被證明能帶來效能提升。
先前的研究已經證明,在監督學習中,中間層會逐漸捕捉不同抽象層級的特徵。初始的層傾向於低層級的特徵,而更深的層會捕捉更抽象的特徵。接下來,研究者探討了 SSL 網路能否學習更高層面的層次屬性以及哪些層面與這些屬性的關聯性較好。
在實驗中,他們計算了三個層級的線性測試準確度:樣本層級、原始的 100 個類別、20 個超類別。圖 2 右圖給出了這三個不同類別集計算的數量。可以觀察到,在訓練過程中,相較於樣本層級的類別,在原始類別和超類別層級上的表現的提升更顯著。
接下來是 SSL 訓練的模型的中間層的行為以及它們捕捉不同層級的目標的能力。圖 5 左和中圖給出了不同訓練階段在所有中間層上的線性測試準確度,這裡測量了原始目標和超目標。圖 5 右圖給出超類別和原始類別之間的比率。
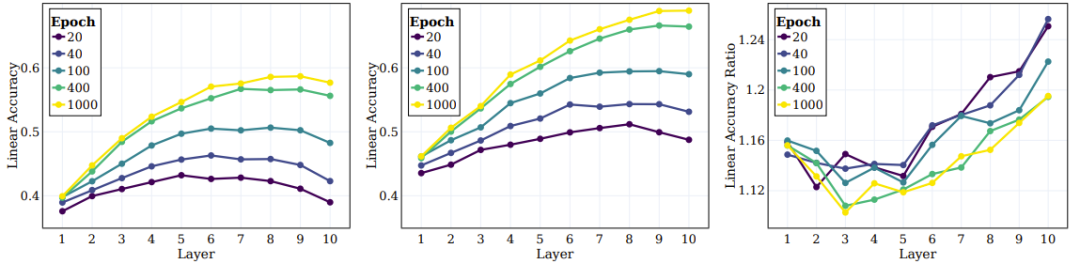
##圖5:SSL 能在整體中間層中有效學習語意類別
研究者基於這些結果得到了幾個結論。首先,可以觀察到隨著層的深入,聚類效果會持續提升。此外,與監督學習情況類似,研究者發現在 SSL 訓練期間,網路每一層的線性準確度都有提升。值得注意的是,他們發現對於原始類別,最終層並不是最佳層。近期的一些 SSL 研究顯示:下游任務能高度影響不同演算法的表現。本文的研究拓展了這項觀察結果,並且顯示網路的不同部分可能適合不同的下游任務與任務層級。根據圖 5 右圖,可以看出,在網路的更深層,超類別的準確度的提升幅度超過原始類別。
以上是Yann LeCun團隊新研究成果:對自監督學習逆向工程,原來聚類是這樣達成的的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































