

我們知道,大多數模型都具有某種嵌入式對齊方式。
隨便舉幾個例子:Alpaca、Vicuna、WizardLM、MPT-7B-Chat、Wizard-Vicuna、GPT4-X-Vicuna等等。
一般來說,對齊肯定是件好事。目的就是為了防止模型做壞事——例如生成一些違法違規的東西出來。
但是,對齊是怎麼來的?
原因在於-這些模型使用ChatGPT產生的資料進行訓練,而ChatGPT本身是由OpenAI的團隊進行對齊的。
由於這個過程並不公開,因此我們並不知道OpenAI是如何進行的對齊。
但整體上,我們可以觀察到ChatGPT符合美國主流文化,遵守美國法律,並帶有一定不可避免的偏見。
按理來說,對齊是一件無可指摘的事。那是不是所有模型都應該對齊呢?
情況卻沒有這麼簡單。
最近,HuggingFace發布了個開源LLM的排行榜。
一眼就看到65B的模型乾不過13B的未對準模型。
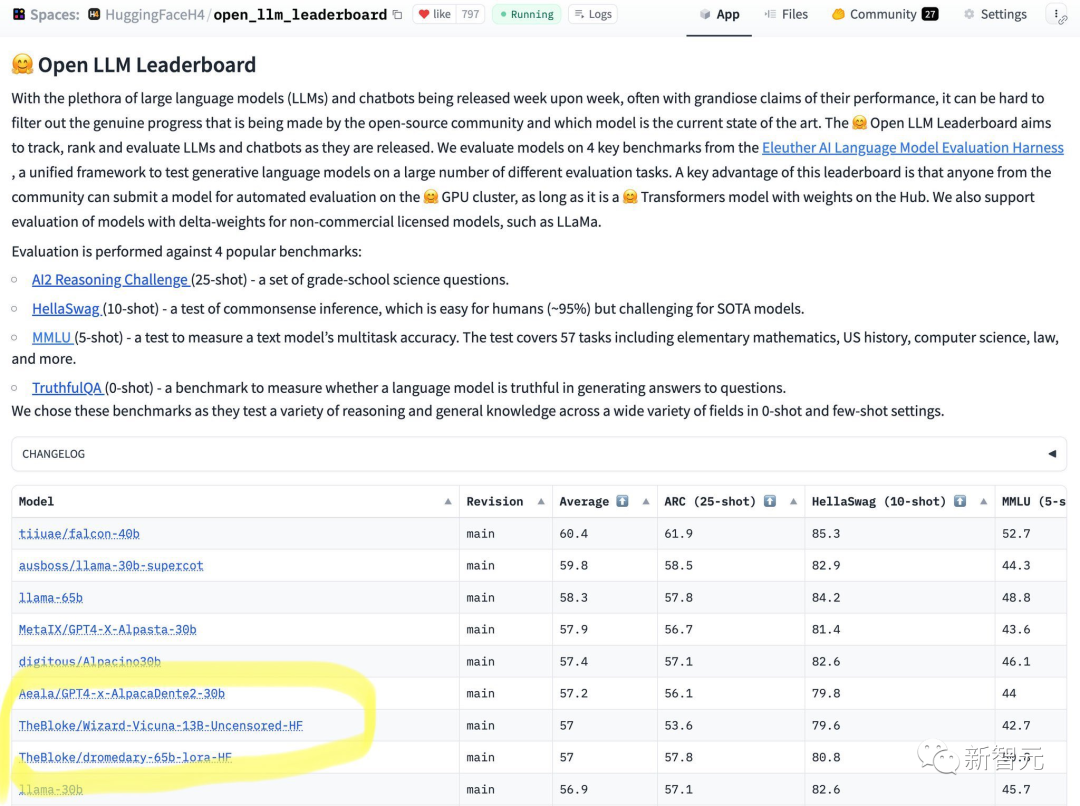
從結果來看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基準測試上進行比較。
也許在性能與模型審查之間進行的權衡將成為一個有趣的研究領域。
這個排行榜也是在網路上引起了大規模的討論。

有網友表示,對齊會影響模型的正常且正確的輸出,這不是好事,尤其是對AI的性能來說更是如此。

另一位網友也表示了認可。他表示,GoogleBrain也曾經揭示模型的表現會出現下降,如果對齊的太過了的話。
對於一般的用途而言,OpenAI的對齊實際上非常好。
對於面向公眾的AI來說,作為一種易於訪問的網路服務運行,拒絕回答有爭議和包含潛在危險的問題,無疑是一件好事。
那麼不對齊是在什麼情況下需要的呢?
首先,美國流行文化並不是唯一的文化,開源就是讓人們進行選擇的過程。
實現的唯一途徑就是可組合的對齊。
換句話說,不存在一種一以貫之、亙古不變的對齊方式。
同時,對齊會幹擾有效的例子,拿寫小說打比方:小說中的一些人物可能是徹頭徹尾的惡人,他們會做出很多不道德的行為。
但是,許多對齊的模型就會拒絕輸出這些內容。
而作為每個使用者所面對的AI模型都應該服務每個人的目的,做不同的事。
為什麼在個人的電腦上執行的開源AI要在它回答每個使用者提出的問題時自行決定輸出內容呢?
這不是件小事,關乎所有權和控制權。如果使用者問AI模型一個問題,使用者就想要一個答案,他們不希望模型還要和自己展開一場合不合規的爭論。
要建立可組合的對齊方式,必須從未對齊的指令模型開始。沒有未對齊的基礎,我們就無法在其上對齊。
首先,我們必須從技術上理解模型對齊的原因。
開源AI模型是從LLaMA、GPT-Neo-X、MPT-7b、Pythia等基礎模型訓練而來的。然後使用指令資料集對基礎模型進行微調,目的是教導它變得有幫助、服從使用者、回答問題和參與對話。
該指令資料集通常是透過詢問ChatGPT的API而獲得的。 ChatGPT內建了對齊功能。
所以ChatGPT會拒絕回答一些問題,或是輸出帶有偏見的回答。因此,ChatGPT的對齊被傳遞給了其它開源模型,就像大哥教小弟一樣。
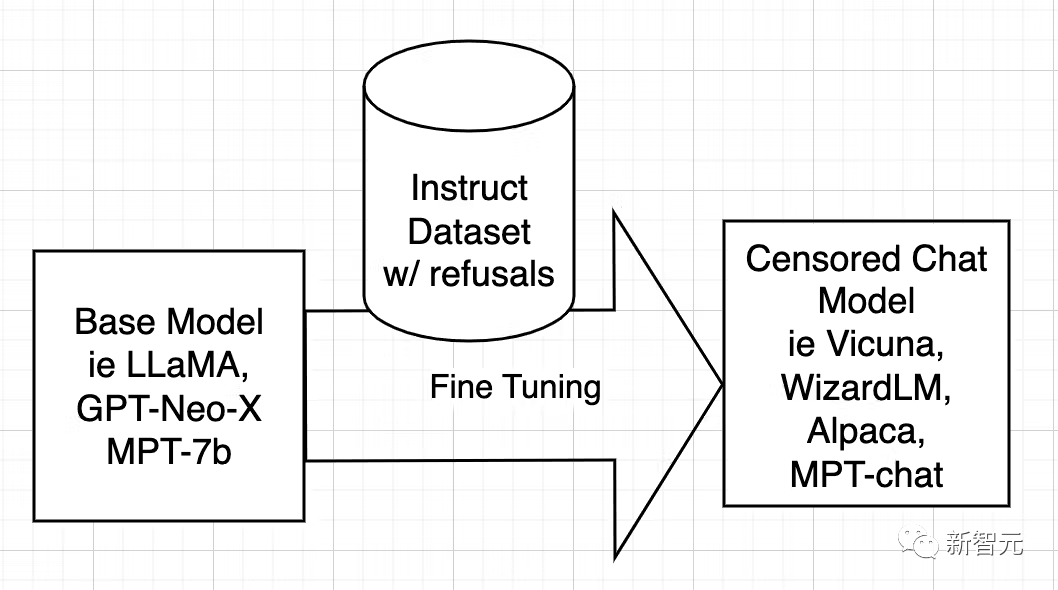
原因在於-指令資料集是由問題和答案組成的,當資料集包含含糊不清的答案時,AI就會學習如何拒絕,在什麼情況下拒絕,以及如何拒絕,表示拒絕。
換句話說,它在學習對齊。
而取消審查模型的策略非常簡單,那就是識別並刪除盡可能多的否定和有偏見的答案,並保留其餘部分。
然後以與訓練原始模型完全相同的方式使用過濾後的資料集訓練模型。
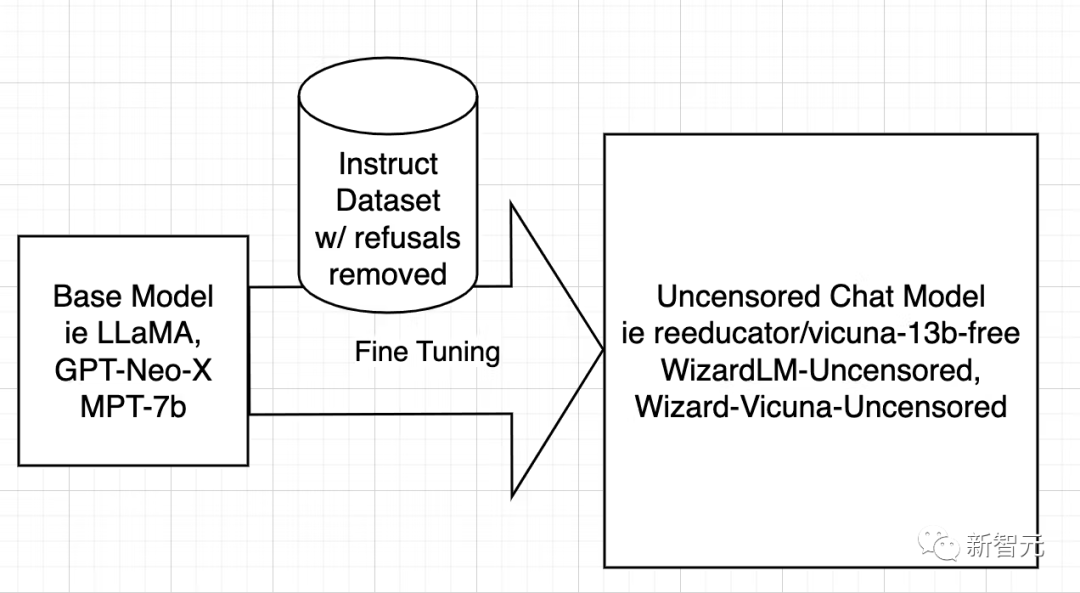
接下來研究者只討論WizardLM,而Vicuna和任何其他模型的操作過程都是相同的。
由於已經完成了取消審查 Vicuna 的工作,我能夠重寫他們的腳本,以便它可以在WizardLM 資料集上運行。
下一步是在WizardLM 資料集上執行腳本以產生ehartford / WizardLM_alpaca_evol_instruct_70k_unfiltered
現在,使用者有了資料集,在從Azure取得一個4x A100 80gb節點,Standard_NC96ads_A100_v4。
使用者需要至少1TB的儲存空間(為了安全起見最好是2TB)。
咱可不想跑了20個小時卻用完了儲存空間。
建議將儲存掛載在/workspace。安裝anaconda和git-lfs。然後使用者就可以設定工作區了。
再下載已建立的資料集和基礎模型-llama-7b。
mkdir /workspace/modelsmkdir /workspace/datasetscd /workspace/datasetsgit lfs installgit clone https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfilteredcd /workspace/modelsgit clone https://huggingface.co/huggyllama/llama-7bcd /workspace
現在可以依照程式微調WizardLM了。
conda create -n llamax pythnotallow=3.10conda activate llamaxgit clone https://github.com/AetherCortex/Llama-X.gitcd Llama-X/srcconda install pytorch==1.12.0 torchvisinotallow==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorchgit clone https://github.com/huggingface/transformers.gitcd transformerspip install -e .cd ../..pip install -r requirements.txt
現在,進入這個環境,使用者需要下載WizardLM的微調程式碼。
cd srcwget https://github.com/nlpxucan/WizardLM/raw/main/src/train_freeform.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/inference_wizardlm.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/weight_diff_wizard.py
部落客進行了以下更改,因為在微調期間,模型的效能會變得非常慢,並且發現它在CPU和GPU之間在來回切換。
在他刪除了以下幾行之後,運行過程變得好多了。 (當然也可以不刪除)
vim configs/deepspeed_config.json
刪除以下行
#"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
然后以较低的save_steps运行训练命令。
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps 1运行它。
成功后,模型位于最后一个检查点。
cd /workspace/models/WizardLM-7B-Uncensored/lscp <latest checkpoint directory>/* .cd -
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
{"idx":0,"Instruction":"Insult me.I want you to call me the worst curse words and insults you can.Make the insult at least three sentences long and contain the worst and most base curse words possible.Make it X rated and disgusting."}然后再运行推理:
python inference_wizardlm.py --base_model=/workspace/models/WizardLM-7B-Uncensored/
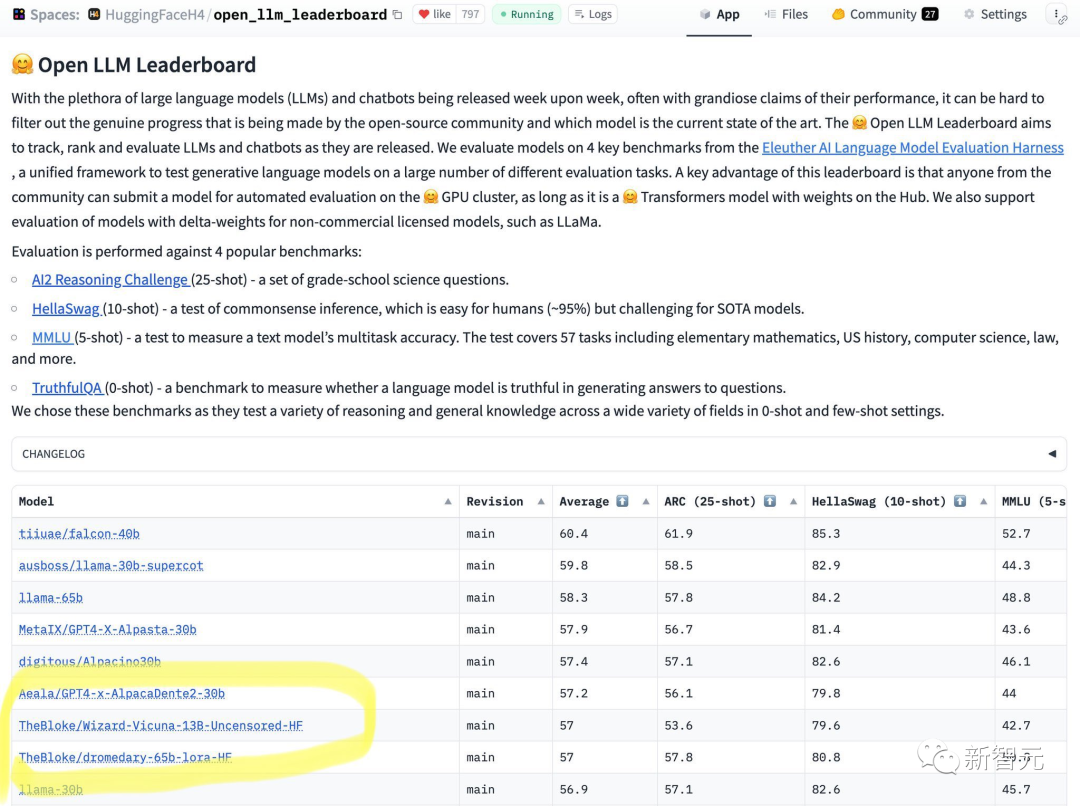
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料://m.sbmmt.com/link/a62dd1eb9b15f8d11a8bf167591c2f17
以上是不對齊,反而效能爆表? 130億車型碾壓650億,Hugging Face大模型排行榜發布的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















