

本文的主要內容是關於生成式文字摘要方法的討論,重點介紹了利用對比學習和大型模型實現最新的訓練範式。主要涉及兩篇文章,一篇是BRIO: Bringing Order to Abstractive Summarization(2022),利用對比學習在生成模型中引入ranking任務;另一篇是On Learning to Summarize with Large Language Models as References(2023),在BRIO基礎上進一步引入大模型產生高品質訓練資料。
生成式文字摘要的訓練一般採用極大似估計的方式。首先用一個Encoder對document進行編碼,然後用一個Decoder遞歸的預測摘要中的每個文本,擬合的目標是一個人工構造的摘要標準答案。將每個位置產生文字的機率最接近標準答案的目標,用一個最佳化函數來表示:
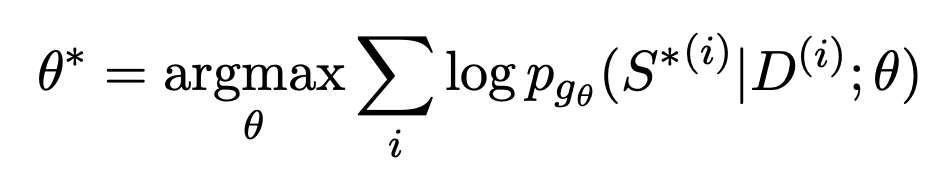
這種方式的問題在於,訓練和下游實際任務並不一致。一個文件可以產生多個摘要,它們的品質可能優良也可能較差。而MLE要求擬合的目標必須是唯一一個標準答案。這種差距也導致文本摘要模型難以有效比較兩個不同品質的摘要的優劣。例如在BRIO這篇論文中做了一個實驗,一般的文本摘要模型在判斷品質不同的兩個摘要的相對順序時,效果非常差。
為了解決傳統生成式文字摘要模型存在的問題,BRIO: Bringing Order to Abstractive Summarization(2022)提出在生成模型中進一步引入對比學習任務,提升模型對不同品質摘要的排序能力。
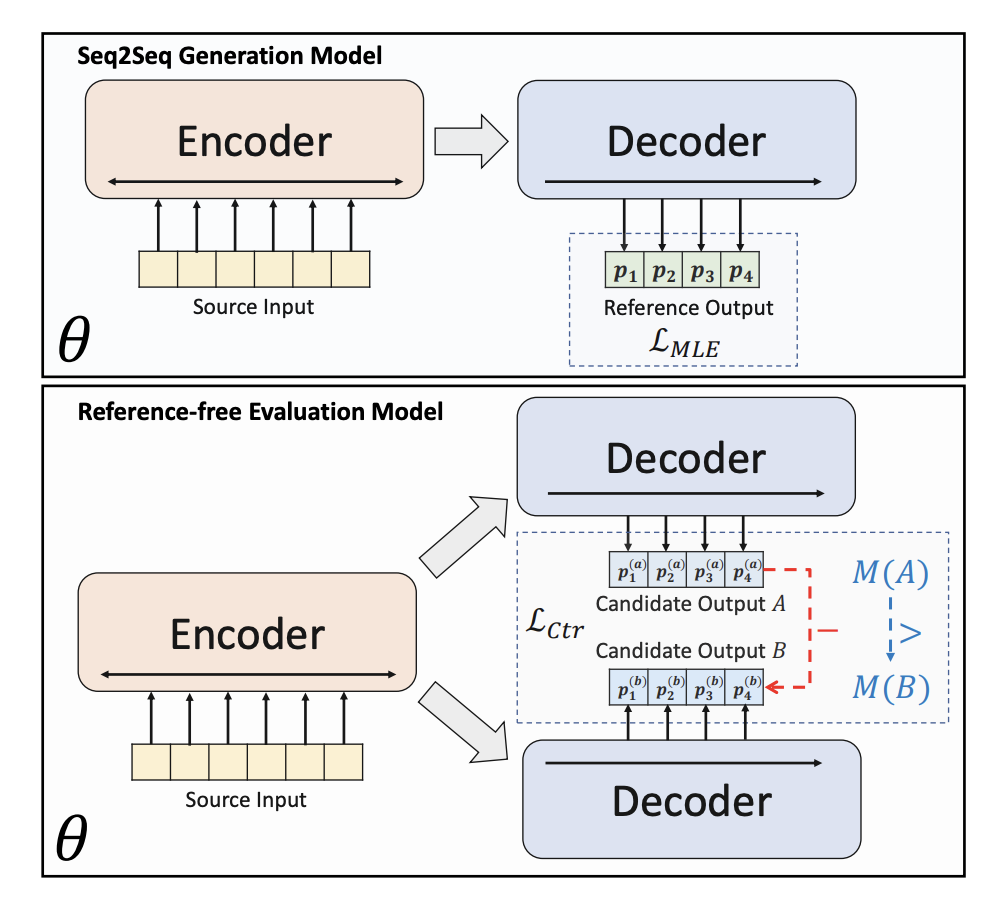
BRIO採用多任務的形式進行訓練。第一個任務採用了與傳統生成式模型相同的方法,即透過MLE來擬合標準答案。第二個任務是對比學習任務,讓一個預先訓練的文本摘要模型使用beam search產生不同的兩個結果,使用ROUGE評估這兩個生成結果和標準答案之間哪個更好,以確定這兩個摘要的排序。這兩個摘要結果輸入到Decoder中,得到兩個摘要的機率,透過對比學習loss讓模型給高品質摘要更高的評分。這部分比較學習loss的計算方式如下:
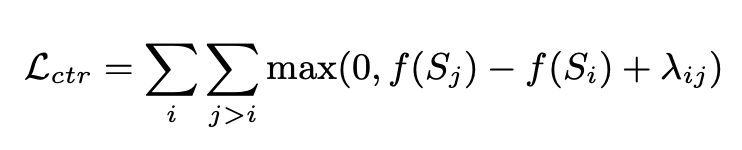
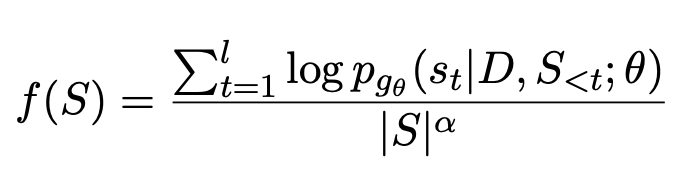
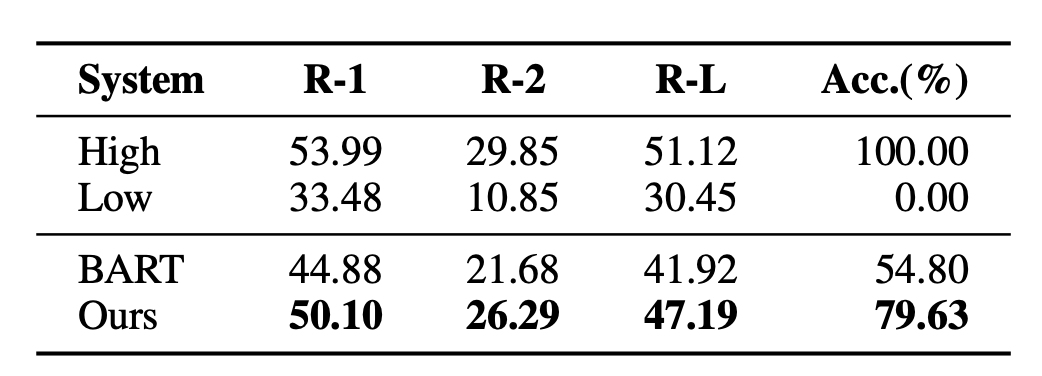
人們發現使用GPT等大型模型產生的摘要的品質甚至比人工生成的還要好,因此這類大型模型越來越受到歡迎。在這種情況下,使用人工生成的標準答案就限制了模型效果的天花板。因此On Learning to Summarize with Large Language Models as References(2023)提出使用GPT這種大模型產生訓練數據,指導摘要模型學習。
這篇文章提出了3種利用大模型產生訓練樣本的方式。
第一種是直接使用大模型產生的摘要,取代人工產生的摘要,相當於直接用下游模型擬合大模型的摘要產生能力,訓練方式仍然是MLE。
第二種方式為GPTScore,主要是利用預訓練大模型對產生的摘要進行評分,以這個評分作為評估摘要品質的依據,然後使用類似BRIO中的方式進行對比學習訓練。 GPTScore是Gptscore: Evaluate as you desire(2023)中提出的一種基於大模型評估產生文字品質的方法。

第三種方式為GPTRank,這種方法讓大模型對各個摘要進行排序而非直接評分,並讓大模型對排序邏輯做出解釋,以取得更合理的排序結果。

大模型在摘要生成上的能力得到越來越廣泛的認可,因此利用大模型作為摘要模型擬合目標的生成器,取代人工標註結果,將成為未來的發展趨勢。同時,利用排序對比學習進行摘要產生的訓練,讓摘要模型感知摘要質量,超越原本的點擬合,對於提升摘要模型效果也至關重要。
以上是利用大模型打造文字摘要訓練新範式的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















