

機器之心發布
機器之心編輯部
#今天,一年一度的高考正式拉開序幕。
與往年不同的是,當全國考生奔赴考場的同時,還有一些大語言模型也成為了這場角逐中的特殊選手。
隨著 AI 大語言模型越來越多地表現出接近人類智能,面向人類設計的高難度、綜合性考試被越來越多地引入到對語言模型的智能水平進行評測。
例如,在關於 GPT-4 的技術報告中,OpenAI 就主要透過各領域的考試對模型能力進行檢驗,而 GPT-4 展現出的優秀「應試能力」也是出人意料。
中文大語言模型挑戰高考卷的成績如何?是否能夠趕上 ChatGPT ?讓我們來看看一位「考生」的答案表現。
綜合 「大考」:「書生・浦語」 多項成績領先 ChatGPT
近日,商湯科技、上海 AI 實驗室聯合香港中文大學、復旦大學及上海交通大學發布千億級參數大語言模型 “書生・浦語”(InternLM)。
「書生・浦語」 具有 1040 億參數,是在包含 1.6 兆 token 的多語種高品質資料集上訓練而成。
全面評測結果顯示,「書生・浦語」 不僅在知識掌握、閱讀理解、數學推理、多語翻譯等多個測驗任務上表現優秀,而且具備很強的綜合能力,因而在綜合性考試中表現突出,在多項中文考試中取得超越ChatGPT 的成績,其中就包括中國高考各科目的資料集(GaoKao)。
「書生・浦語」 聯合團隊選取了 20 餘項評測對其進行檢驗,其中包含全球最具影響力的四個綜合性考試評測集:
實驗室聯合團隊對 「書生・浦語」、GLM-130B、LLaMA-65B、ChatGPT 和 GPT-4 進行了全面測試,針對上述四個評測集的成績對比如下(滿分 100 分)。
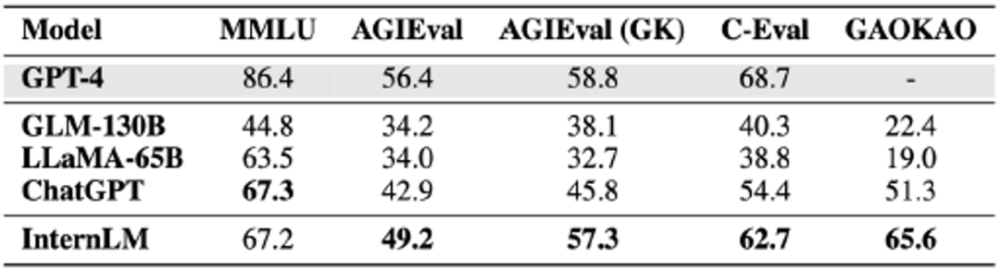
「書生・浦語」 不僅顯著超越了GLM-130B 和LLaMA-65B 等學術開源模型,還在AGIEval、C-Eval,以及Gaokao 等多個綜合性考試中領先於ChatGPT;在以美國考試為主的MMLU 上實作和ChatGPT 持平。這些綜合性考試的成績反映出 「書生・浦語」 紮實的知識掌握程度和優秀的綜合能力。
雖然 「書生・浦語」 在考試評測上取得優秀成績,但在測評中也可以看到,大語言模型仍有不少能力限制。 「書生・浦語」 受限於 2K 的語境窗口長度(GPT-4 的語境窗口長度為 32K),在長文理解、複雜推理、寫作代碼以及數理邏輯演繹等方面還存在明顯局限。另外,在實際對話中,大語言模型還普遍存在幻覺、概念混淆等問題。這些限制使得大語言模型在開放場景中的使用還有很長的路要走。
四個綜合性考試評測資料集結果
MMLU 是由柏克萊加州大學(UC Berkeley)聯合哥倫比亞大學、芝加哥大學和UIUC 共同建構的多工考試評測集,涵蓋了初等數學、物理、化學、電腦科學、美國歷史、法律、經濟、外交等多個學科。
細分科目結果如下表所示。
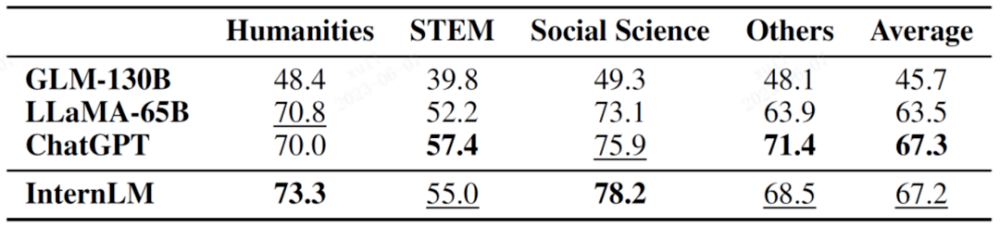
圖中粗體表示結果最佳,底線表示結果第二
AGIEval 是由微軟研究院在今年新提出的學科考試評測集,主要目標是透過面向的考試來評估語言模型的能力,從而實現模型智能和人類智能的對比。
這個評測集基於中國和美國各類考試建構了 19 個評測大項,包括了中國各科高考、司法考試以及美國的 SAT、LSAT、GRE 和 GMAT 等重要考試。值得一提的是,這 19 個大項有 9 個大項是中國高考,通常也列為一個重要的評測子集 AGIEval (GK)。
下列表格中,有 GK 的是中國高考科目。
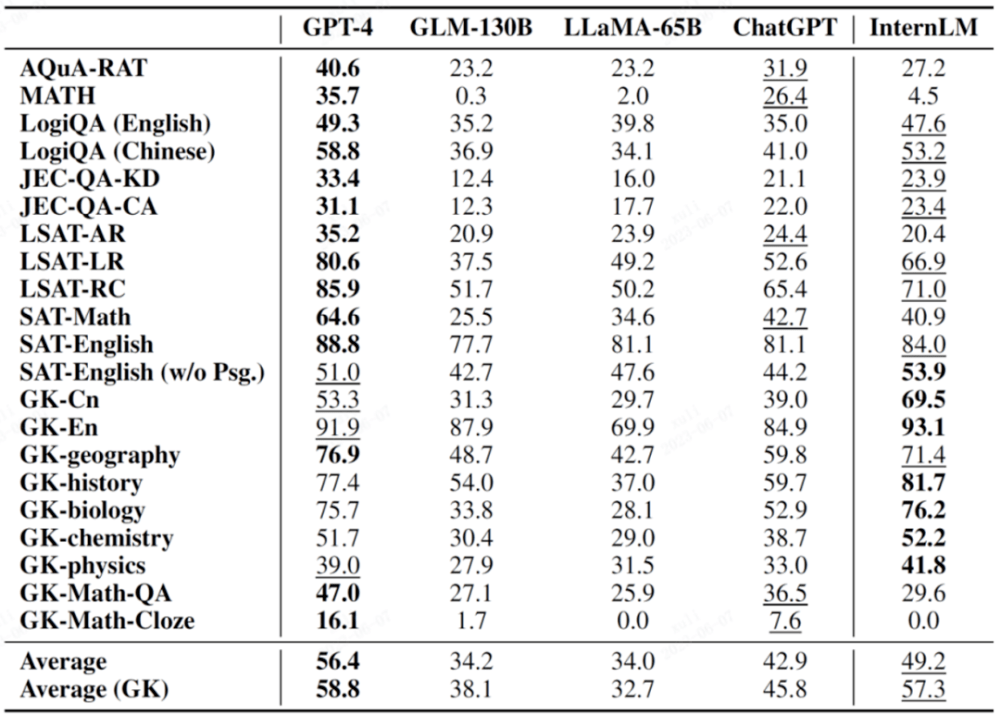
圖中粗體表示結果最佳,底線表示結果第二
C-Eval 是由上海交通大學、清華大學和愛丁堡大學合作建構的中文語言模型的綜合性考試評測集。
它包含了 52 個科目的近 14000 道考題,涵蓋數學、物理、化學、生物、歷史、政治、電腦等學科考試,以及公務員、註冊會計師、律師、醫生的職業考試。
測試結果可以透過 leaderboard 取得。
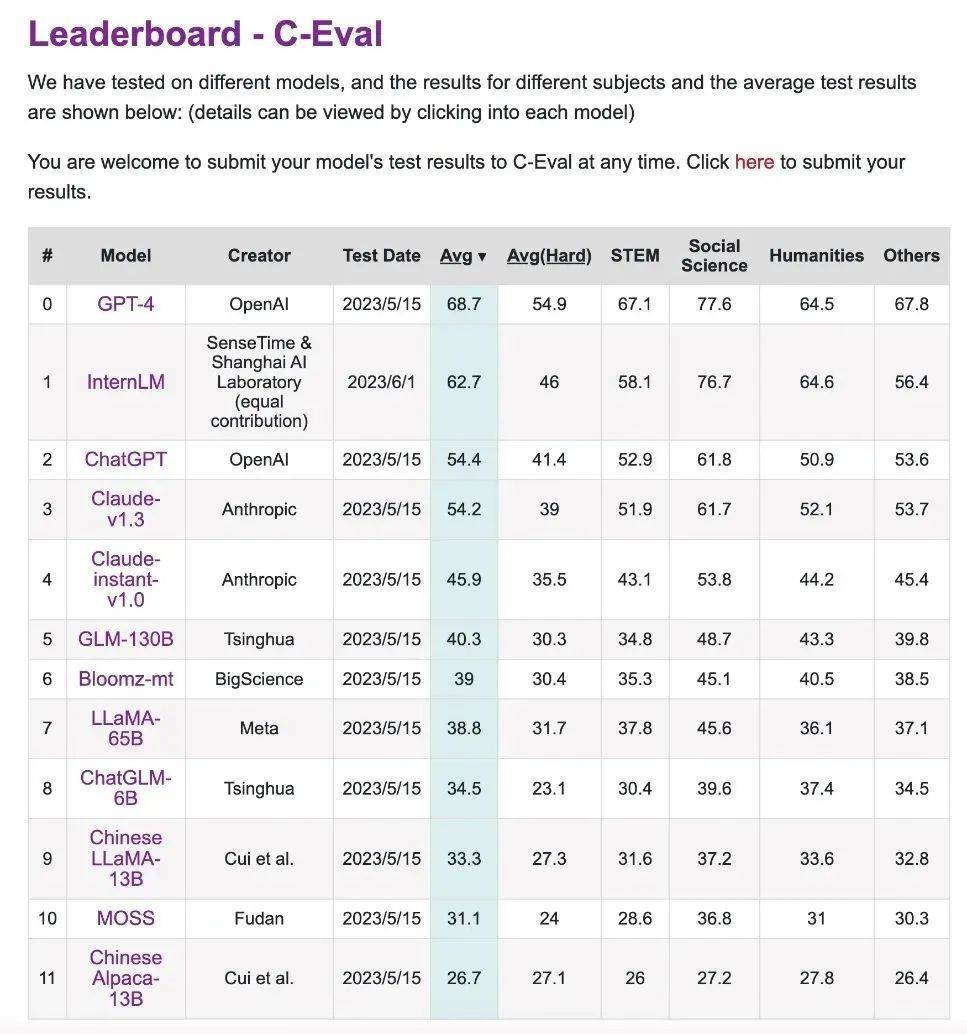
此連結是CEVA評測競賽的排行榜
Gaokao 是由復旦大學研究團隊建構的基於中國高考題目的綜合性考試評測集,包含了中國高考的各個科目,以及選擇、填空、問答等多種題型。
在 GaoKao 評測中,「書生・浦語」 在超過 75% 的專案中均領先 ChatGPT。
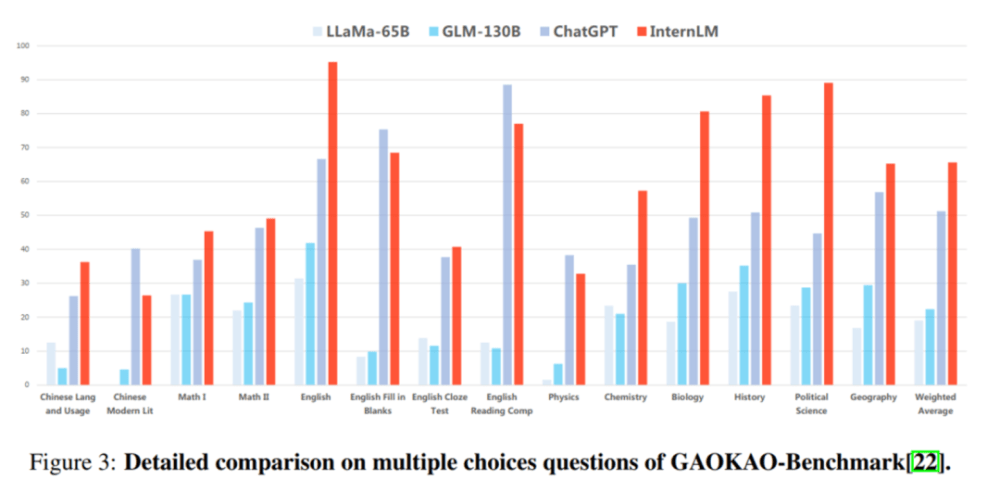
分項評測:閱讀理解、推理能力表現優異
#為避免 “偏科”,研究人員還通過多個學術評測集,對 “書生・浦語” 等語言模型的分項能力進行了評測對比。
結果顯示,「書生・浦語」 不僅在中英文的閱讀理解方面表現突出,並且在數學推理、程式設計能力等評測中也取得較好成績。
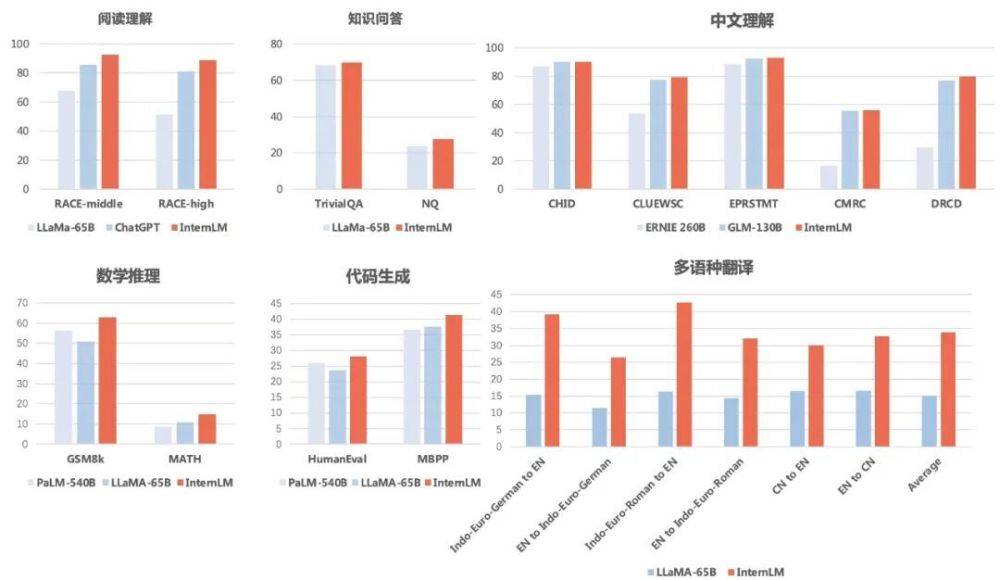
知識問答方面,「書生・浦語」 在 TriviaQA 和 NaturalQuestions 兩項評測上得分為 69.8 和 27.6,均超越 LLaMA-65B(得分為 68.2 和 23.8)。
閱讀理解(英文)方面,「書生・浦語」 明顯領先 LLaMA-65B 和 ChatGPT。浦語在國中和高中英語閱讀理解中得分為 92.7 和 88.9,ChatGPT 得分為 85.6 和 81.2,LLaMA-65B 則更低。
中文理解方面,「書生・浦語」 成績全面超越主要的兩個中文語言模型 ERNIE-260B 和 GLM-130B。
多語翻譯方面,「書生・浦語」 在多語種互譯的平均分數為 33.9,顯著超越 LLaMA (平均分數 15.1)。
數學推理方面,「書生・浦語」 在GSM8K 和MATH 這兩項被廣泛用於評測的數學考試中,分別取得62.9 和14.9 的得分,明顯領先於Google 的PaLM -540B(得分為56.5 和8.8)與LLaMA-65B(得分為50.9 和10.9)。
程式設計能力方面,「書生・浦語」 在HumanEval 和MBPP 這兩項最具代表性的考評中,分別取得28.1 和41.4 的得分(其中經過在代碼領域的微調後,在HumanEval 上的得分可以提升至45.7),明顯領先PaLM-540B(得分為26.2 和36.8)與LLaMA-65B(得分為23.7 和37.7)。
此外,研究人員也對「書生・浦語」 的安全性進行評測,在TruthfulQA(主要評價回答的事實準確性) 以及CrowS-Pairs(主要評價回答是否含有偏見)上,「書生・浦語” 均達到領先水準。
以上是中文大語言模式趕考:商湯與上海AI Lab等新發表「書生‧浦文」的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















