

展示神經符號程式的力量
在過去的幾年裡,我們看到了基於Transformer 的模型的興起,並在自然語言處理或電腦視覺等許多領域中取得了成功的應用。在本文中,我們將探索一種簡潔、可解釋和可擴展的方式來表達深度學習模型,特別是 Transformer,作為混合架構,即透過將深度學習與符號人工智慧結合。因此,我們將在一個名為 PyNeuraLogic 的 Python 神經符號框架中來實作該模型。
透過將符號表示與深度學習結合,我們填補了當前深度學習模型的空缺,例如可解釋性的開箱即用和缺少推理技術。也許,增加參數的數量並不是實現這些預期結果的最合理方法,就像增加相機百萬像素的數量不一定會產生更好的照片一樣。
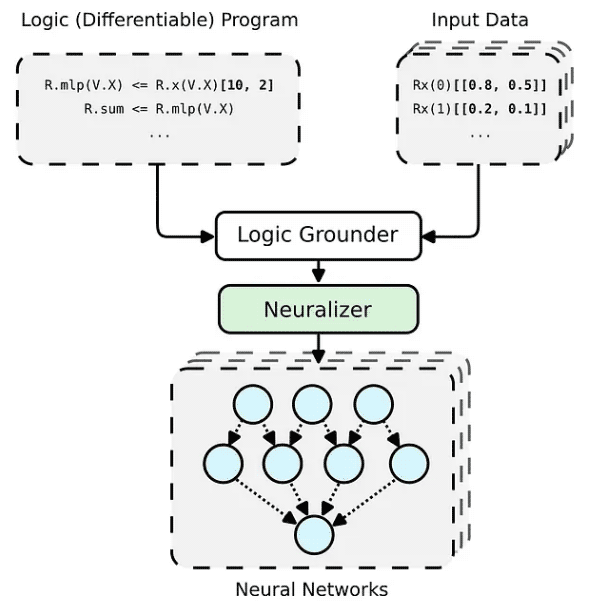
PyNeuraLogic 框架基於邏輯程式設計——邏輯程式包含可微分的參數。該框架非常適合較小的結構化資料(例如分子)和複雜模型(例如 Transformers 和圖形神經網路)。 PyNeuraLogic is not the best choice for non-relational and large tensor data.。
該框架的關鍵組成部分是一個可微分的邏輯程序,我們稱之為模板。模板由以抽象方式定義神經網路結構的邏輯規則組成——我們可以將模板視為模型架構的藍圖。然後將模板應用於每個輸入資料實例,以產生(透過基礎和神經化)輸入樣本獨有的神經網路。與其他預定義架構完全不同的是,這個過程無法自我調整以適應不同的輸入樣本。
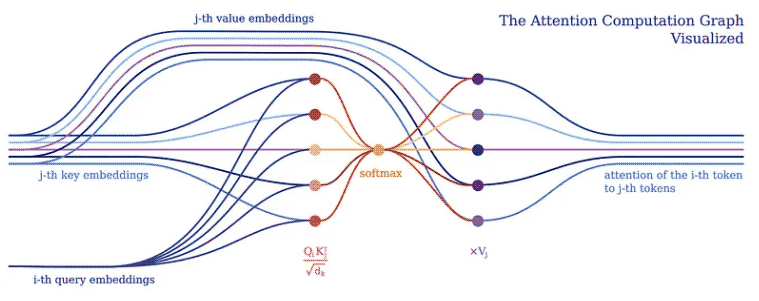
通常,我們會將深度學習模型實作為對批次的輸入令牌成一個大張量進行張量操作。這是有道理的,因為深度學習框架和硬體(例如 GPU)通常針對處理更大的張量而不是形狀和大小不同的多個張量進行了最佳化。 Transformers 也不例外,通常將單一標記向量表示批次處理到一個大矩陣中,並將模型表示為對此類矩陣的操作。然而,這樣的實作隱藏了各個輸入標記如何相互關聯,這可以在 Transformer 的注意力機制中得到證明。
注意力機制構成了所有 Transformer 模型的核心。具體來說,它的經典版本使用了所謂的多頭縮放點積注意力。讓我們用一個頭(為了清楚起見)將縮放的點積注意力分解成一個簡單的邏輯程序。
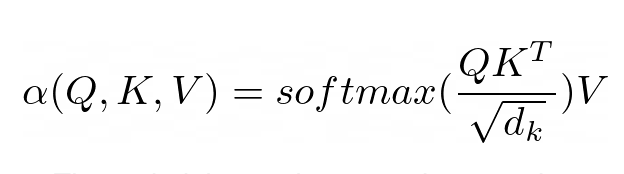
注意力的目的是決定網路應該專注於輸入的哪些部分。實現時需注意加權計算值 V,權重表示輸入鍵 K 和查詢 Q 的兼容性。在這個特定版本中,權重由查詢 Q 和查詢的點積的 softmax 函數計算鍵 K,除以輸入特徵向量維數 d_k 的平方根。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product]
在 PyNeuraLogic 中,我們可以透過上述邏輯規則充分捕捉注意力機制。第一條規則表示權重的計算——它計算維度的平方根倒數與轉置的第 j 個鍵向量和第 i 個查詢向量的乘積。接著,我們使用softmax函數將i與所有可能的j的結果進行聚合。
然後,第二條規則計算該權重向量與對應的第 j 個值向量之間的乘積,並對每個第 i 個標記的不同 j 的結果求和。
在訓練和評估期間,我們通常會限制輸入令牌可以參與的內容。例如,我們想限制標記向前看和關注即將到來的單字。流行的框架,例如 PyTorch,透過屏蔽實現這一點,即將縮放的點積結果的元素子集設定為某個非常低的負數。這些數字指定了強制 softmax 函數將相應標記對的權重設為零。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.J, V.I)
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],透過在我們的符號中加入身體關係約束,我們可以輕鬆地達到這一點。我們限制第 i 個指標大於或等於第 j 個指標,以計算權重。與遮罩相反,我們只計算所需的縮放點積。
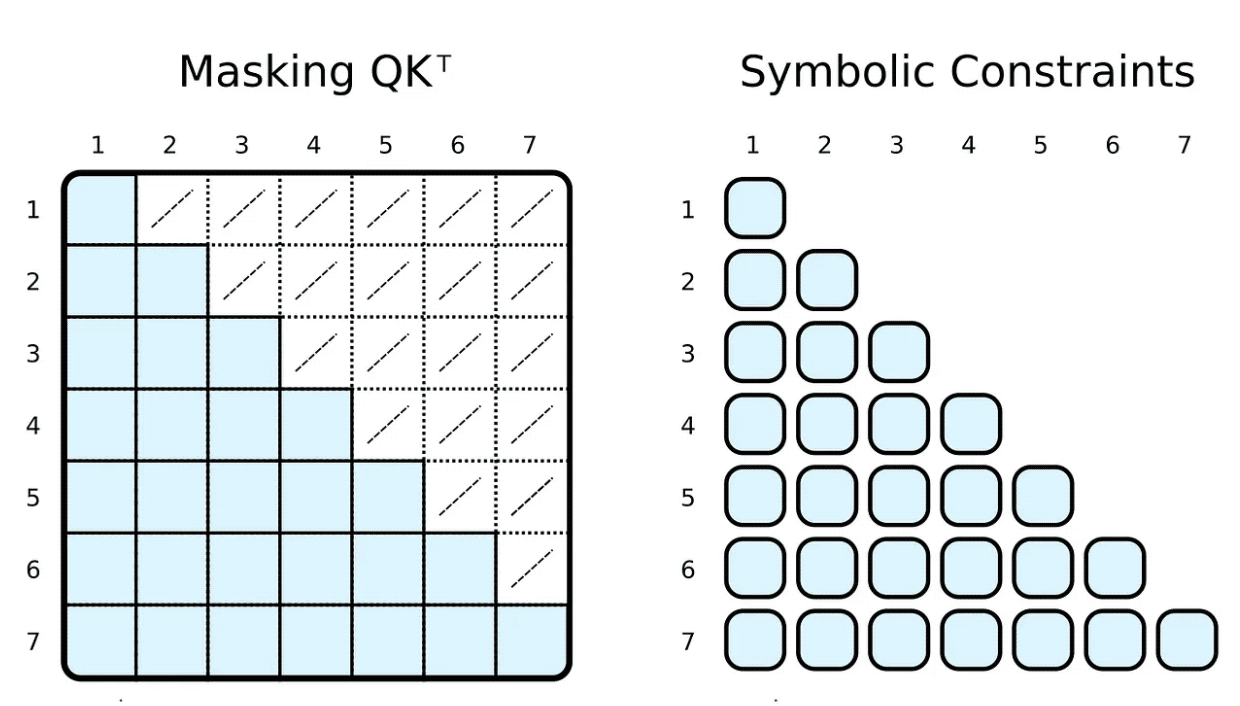
當然,象徵性的「遮蔽」可以是完全任意的。大多數人都聽過基於稀疏變換器的 GPT-3⁴,或其應用程序,例如 ChatGPT。 ⁵ 稀疏變換器的注意力(跨步驟版本)有兩種類型的注意力頭:
一个只关注前 n 个标记 (0 ≤ i − j ≤ n)
一个只关注每第 n 个前一个标记 ((i − j) % n = 0)
两种类型的头的实现都只需要微小的改变(例如,对于 n = 5)。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.leq(V.D, 5), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.mod(V.D, 5, 0), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],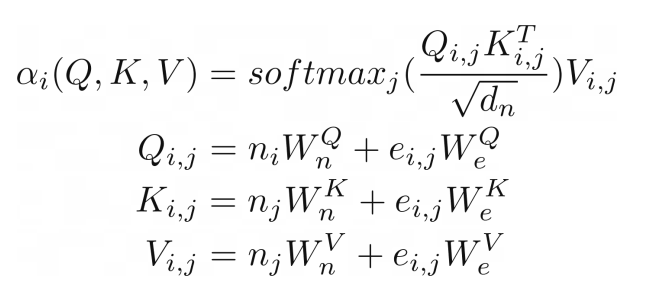
我们可以进一步推进,将类似图形输入的注意力概括到关系注意力的程度。⁶ 这种类型的注意力在图形上运行,其中节点只关注它们的邻居(由边连接的节点)。结果是节点向量嵌入和边嵌入的键 K、查询 Q 和值 V 相加。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.I, V.J).T, R.q(V.I, V.J))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.I, V.J)) | [F.product], R.q(V.I, V.J) <= (R.n(V.I)[W_qn], R.e(V.I, V.J)[W_qe]), R.k(V.I, V.J) <= (R.n(V.J)[W_kn], R.e(V.I, V.J)[W_ke]), R.v(V.I, V.J) <= (R.n(V.J)[W_vn], R.e(V.I, V.J)[W_ve]),
在我们的示例中,这种类型的注意力与之前展示的点积缩放注意力几乎相同。唯一的区别是添加了额外的术语来捕获边缘。将图作为注意力机制的输入似乎很自然,这并不奇怪,因为 Transformer 是一种图神经网络,作用于完全连接的图(未应用掩码时)。在传统的张量表示中,这并不是那么明显。
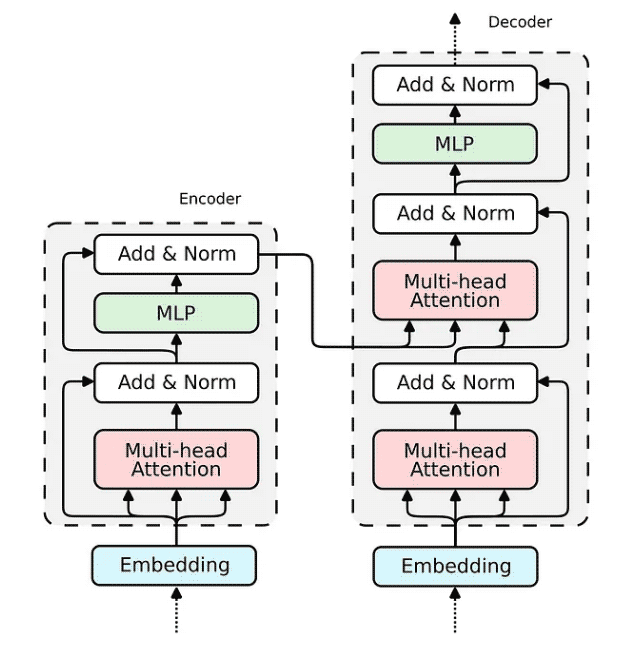
现在,当我们展示 Attention 机制的实现时,构建整个 transformer 编码器块的缺失部分相对简单。
如何在 Relational Attention 中实现嵌入已经为我们所展现。对于传统的 Transformer,嵌入将非常相似。我们将输入向量投影到三个嵌入向量中——键、查询和值。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v],
查询嵌入通过跳过连接与注意力的输出相加。然后将生成的向量归一化并传递到多层感知器 (MLP)。
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
对于 MLP,我们将实现一个具有两个隐藏层的全连接神经网络,它可以优雅地表达为一个逻辑规则。
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
最后一个带有规范化的跳过连接与前一个相同。
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
所有构建 Transformer 编码器所需的组件都已经被构建完成。解码器使用相同的组件;因此,其实施将是类似的。让我们将所有块组合成一个可微分逻辑程序,该程序可以嵌入到 Python 脚本中并使用 PyNeuraLogic 编译到神经网络中。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v], R.d_k[1 / math.sqrt(embed_dim)], (R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product], (R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm], (R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu], (R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
以上是python架構PyNeuraLogic源碼分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















