

我們來看看當進行 join 操作時,mysql是如何運作的。常見的 join 方式有哪些?
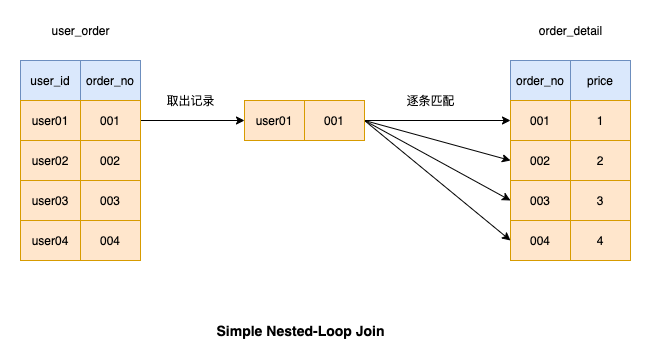
如圖,當我們進行連接操作時,左邊的表是驅動表,右邊的表是被驅動表
Simple Nested-Loop Join 這種連接操作是從驅動表中取出一筆記錄然後逐條匹配被驅動表的記錄,如果條件匹配則將結果傳回。接著,繼續匹配驅動表的下一筆記錄,直到驅動表的所有資料都被匹配完
#因為每次從驅動表取資料比較耗時,所以MySQL並沒有採用這個演算法來進行連線操作
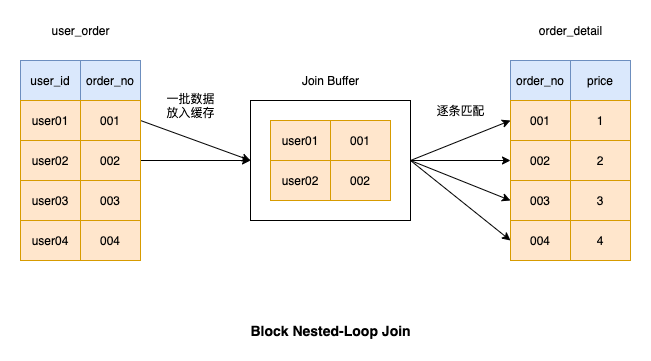
#為了避免每次從驅動程式表取資料耗時,我們可以將一批資料會一次從驅動表取出,並在記憶體中進行匹配操作。這批資料匹配完畢,再從驅動表中取一批資料放到記憶體中,直到驅動表的資料全都匹配完畢
批量取資料能減少很多IO操作,因此執行效率比較高,這種連接操作也被MySQL採用
對了,這塊內存在MySQ中有一個專有的名詞,叫做join buffer,我們可以執行以下語句查看join buffer 的大小
show variables like '%join_buffer%'

把我們之前用的single_table 表搬出來,基於single_table 表建立2個表,每個表插入1w個隨機記錄
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;如果直接使用join 語句,MySQL優化器可能會選擇表t1 或t2 作為驅動表,這會影響我們分析sql語句的過程,所以我們用straight_join 讓mysql使用固定的連接方式執行查詢
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
運行時間為0.035s

執行計劃如下

在Extra列中看到了Using join buffer ,說明連接操作是基於Block Nested -Loop Join 演算法
#了解了Block Nested-Loop Join 演算法之後,可以看到驅動表的每個記錄會把被驅動表的所有記錄都配對一遍,非常耗時,能不能提升一下被驅動表匹配的效率呢?
估計這種演算法你也想到了,就是為被驅動表連接的列加上索引,這樣匹配的過程就非常快,如圖所示
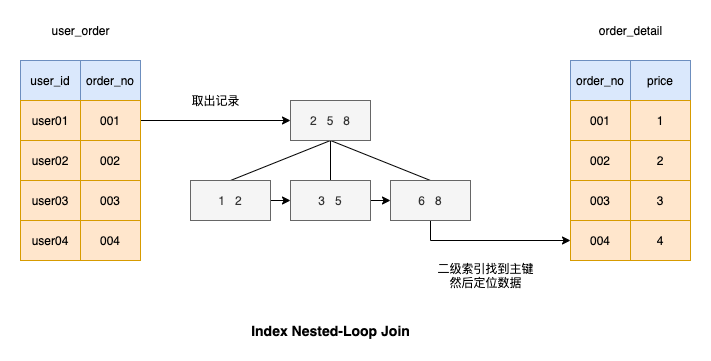
我們來看看基於索引列進行連線執行查詢有多快?
select * from t1 straight_join t2 on (t1.id = t2.id)
執行時間為0.001秒,可以看到比基於普通的列進行連接快了不止一個檔次

執行計劃如下

驅動表的記錄並不是所有列都會被放到join buffer,只有查詢清單中的列和篩選條件中的列才會被放入join buffer,因此我們不要把* 作為查詢列表,只需要把我們關心的列放到查詢列表就好了,這樣可以在join buffer 中放置更多的記錄
知道了 join 的具體實現,我們來聊一個常見的問題,即如何選擇驅動表?
如果是Block Nested-Loop Join 演算法:
#當join buffer 夠大時,誰做驅動表沒有影響
#當join buffer 不夠大時,應該選擇小表做驅動表(小表資料量少,放入join buffer 的次數少,減少表的掃描次數)
如果是Index Nested-Loop Join 演算法
假設驅動程式表的行數是M,因此需要掃描驅動表M行
每次從被驅動表中取得一行資料時,需要先尋找索引a,然後再尋找主鍵索引。被驅動表的行數為N。每次搜尋一顆樹近似複雜度是以2為底N的對數,所以在被驅動表上查一行的時間複雜度是2 ∗ l o g 2 N 2*log2^N 2∗log2N
驅動表的每一行資料都要到被驅動表上搜尋一次,整個執行過程近似複雜度為M M ∗ 2 ∗ l o g 2 N M M*2*log2^N M M∗2∗log2N
顯然M對掃描行數影響更大,因此應該讓小表做驅動表。當然這個結論的前提是可以使用被驅動表的索引
總而言之,我們讓小表做驅動表即可
當join 語句執行的比較慢時,我們可以透過以下方法來進行最佳化
進行連接操作時,能使用被驅動表的索引
#小表來做驅動表
增大join buffer 的大小
不要用* 作為查詢列表,只回傳需要的列
以上是MySQL中join語句如何最佳化的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































