

繼Windows Copilot發布後,微軟Build大會熱度又被一場演講引爆。
前特斯拉AI總監Andrej Karpathy在演講中認為思考樹(tree of thoughts)與AlphaGo的蒙特卡羅樹搜尋(MCTS)有異曲同工之妙!
網友高喊:這是關於如何使用大語言模型和GPT-4模型的最詳盡有趣的指南!

此外Karpathy透露,由於訓練和數據的擴展,LLAMA 65B“明顯比GPT-3 175B更強大”,並介紹了大模型匿名競技場ChatBot Arena:
Claude得分介於ChatGPT 3.5和ChatGPT 4之間。

網友表示,Karpathy的演講一向很棒,而這次的內容也一如既往沒有令大家失望。
隨著演講而爆火的,還有推特網友根據演講整理的一份筆記,足足有31條,目前轉讚量已超過3000 :
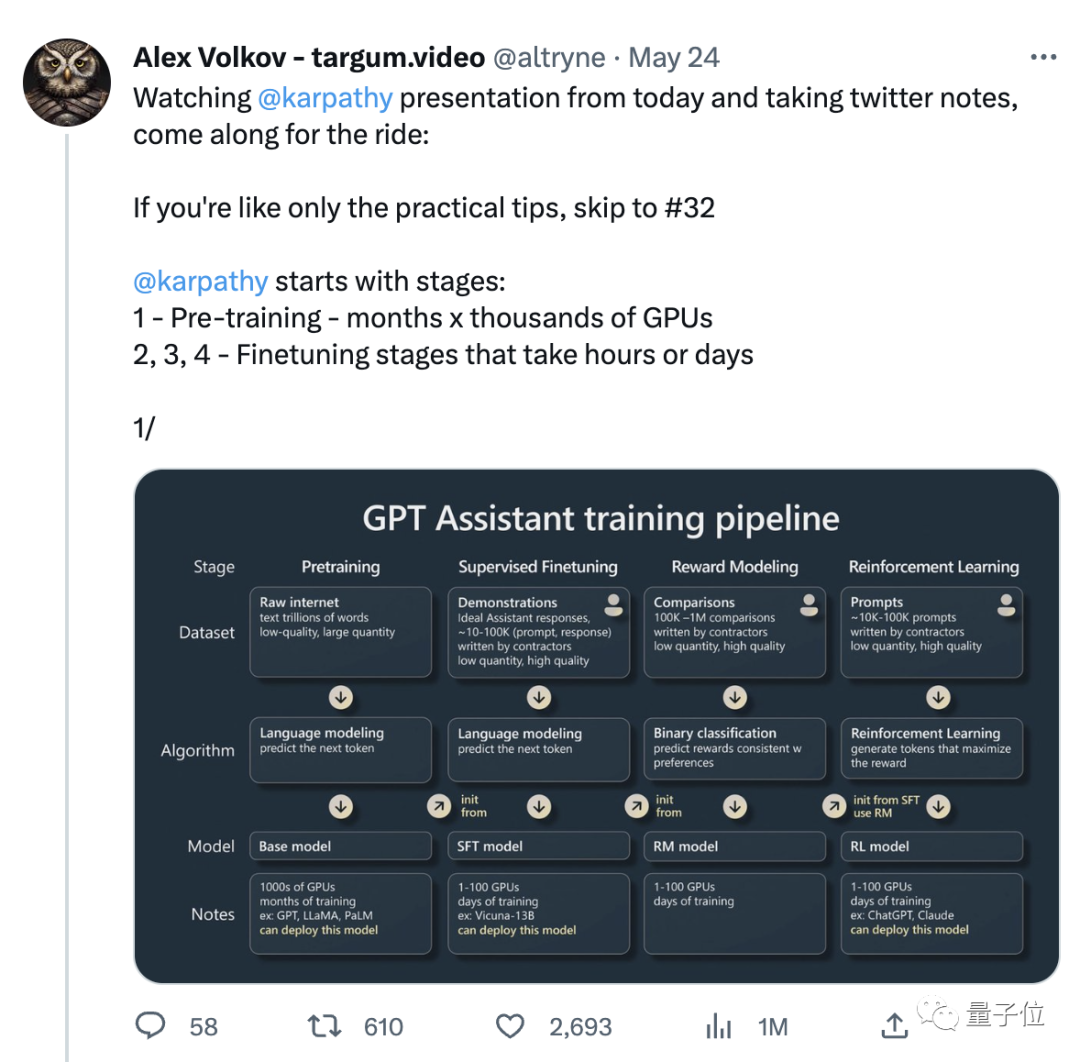
所以,這段備受關注的演講,具體提到了哪些內容呢?
Karpathy這次的演講主要分為兩個部分。
第一部分,他講如何訓練一個「GPT助手」。
Karpathy主要講述了AI助手的四個訓練階段:
預訓練(pre-training)、監督微調(supervised fine tuning)、獎勵建模(reward modeling)和強化學習(reinforcement learning )。
每一個階段都需要一個資料集。

在預訓練階段,需要動用大量的運算資源,收集大量的資料集。在大量無監督的資料集上訓練出一個基礎模型。
Karpathy用了更多例子來補充:
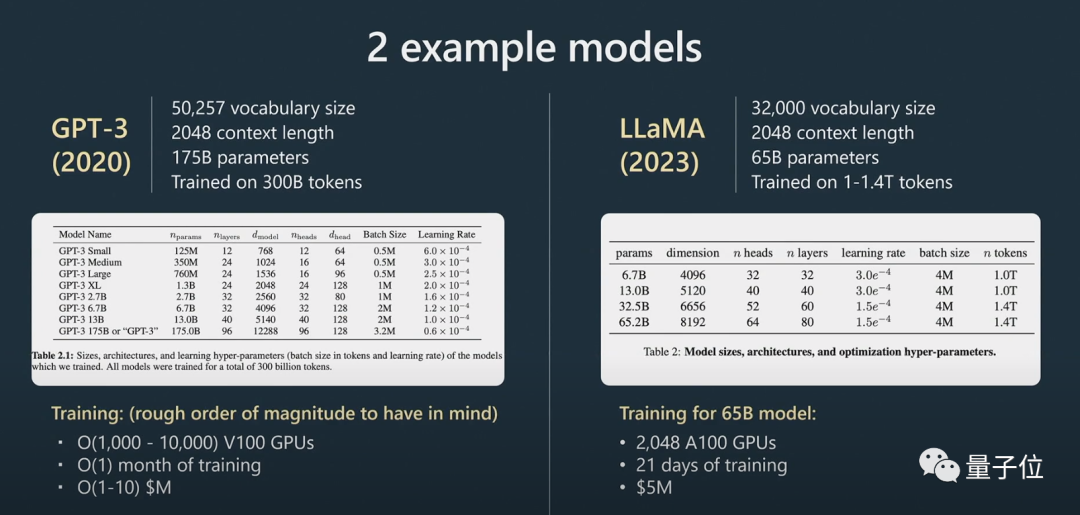
#接下來進入微調階段。
使用較小的監督資料集,透過監督學習對這個基礎模型進行微調,就能創建一個能夠回答問題的助手模型。
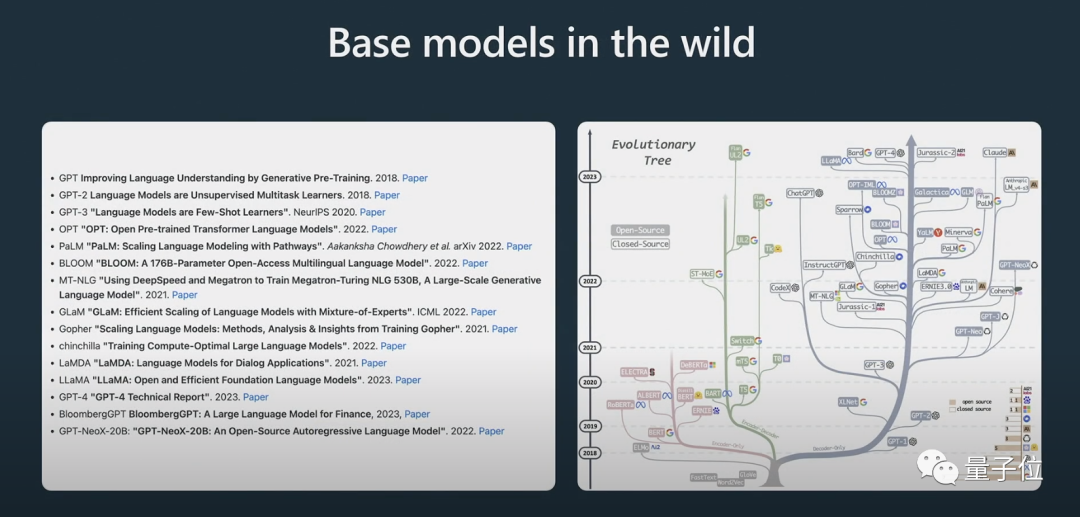
他也展示了一些模型的演化過程,相信很多人之前已經看過上面這張「演化樹」的圖了。
Karpathy認為目前最好的開源模型是Meta的LLaMA系列(因為OpenAI沒有開源任何關於GPT-4的內容)。
在這裡需要明確指出的是,基礎模型不是助手模型。
儘管基礎模型有解決問題的能力,但其給出的答案並不可信,而助手模型能夠提供可靠的答案。經過監督微調的助手模型,在基礎模型的基礎上訓練,其生成回復和理解文本結構的表現將優於基礎模型。
在訓練語言模型時,強化學習是另一個關鍵的過程。
訓練過程中採用高品質的人工標註數據,並以獎勵建模的方式創建損失函數,從而提高其性能。強化訓練可以透過增加積極標記和降低消極標記的機率來實現。
在涉及創造性任務時,人類的判斷力對於改進AI模型至關重要,透過加入人類的回饋可以更有效地訓練模型。
經過人類回饋的強化學習後,就可以得到一個RLHF模型了。
模型訓練好了,接下來就是如何有效利用這些模型解決問題了。
在第二部分,Karpathy主要討論了提示策略、微調、快速發展的工俱生態系統以及未來的擴展等問題。
Karpathy又給了一個具體範例來說明:

#在寫作時,我們需要進行許多心理活動,包括考慮自己的表達是否準確。 For GPT, this is merely a sequence of tokens being tagged.。
而提示(prompt)可以彌補這個認知差異。
Karpathy進一步解釋了思維鏈提示的工作方式。
對於推理問題,要讓自然語言處理中Transformer的表現更好,需要讓它一步一步地處理訊息,而不能直接拋給它一個非常複雜的問題。
如果你給它幾個例子,它會模仿這個例子的模版,最終產生的結果會更好。

模型只能按照它的序列來回答問題,如果它產生的內容是錯誤的,你可以進行提示,讓它重新生成。
如果你不要求它檢查,它自己是不會檢查的。
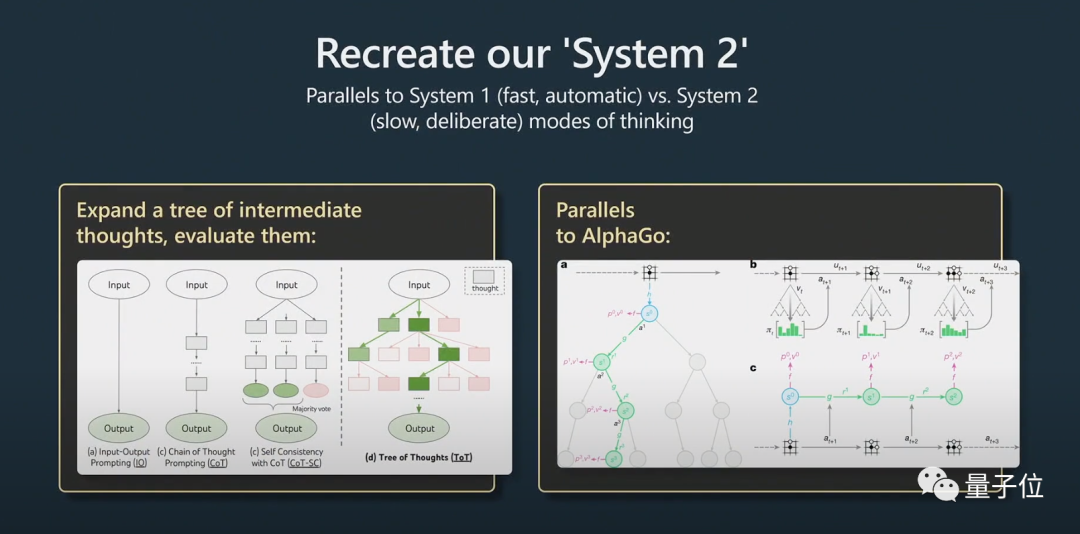
這就牽涉到了System1和System2的問題。
諾貝爾經濟學獎得主丹尼爾卡尼曼在《思考快與慢》中提出,人的認知系統包含System1和System2兩個子系統。 System1主要靠直覺,而System2是邏輯分析系統。
通俗來說,System1是一個快速自動產生的過程,而System2是經過深思熟慮的部分。
這在最近一篇挺火的論文「Tree of thought」(思考樹)中也被提及。

深思熟慮指的是,不是簡單的給出問題的答案,而更像是與Python膠水代碼一起使用的prompt,將許多prompt串聯在一起。為了擴展提示,模型需要維護多個提示並執行樹搜尋演算法。
Karpathy認為這個想法與AlphaGo非常相似:
AlphaGo在下圍棋時,需要考慮下一個棋子下在哪裡。最初它是靠模仿人類來學習的。
除此之外,它還實作了蒙特卡羅樹搜索,以獲取具有多種潛在策略的結果。它可以對多種可能的下法進行評估,只保留那些較好的策略。我認為這在某種程度上相當於AlphaGo。
對此,Karpathy也提到了AutoGPT:
我認為目前它的效果還不是很好,我不建議大家進行實際應用。我認為隨著時間的推移,我們或許可以從它的發展歷程中吸取啟示。

其次,還有一個小妙招是檢索增強生成(retrieval agumented generation)和有效提示。
視窗上下文的內容就是transformers在運行時的記憶(working memory),如果你可以將與任務相關的資訊加入到上下文中,那麼它的表現就會非常好,因為它可以立即訪問這些資訊。
簡而言之,就是可以為相關資料建立索引讓模型可以有效率地存取。
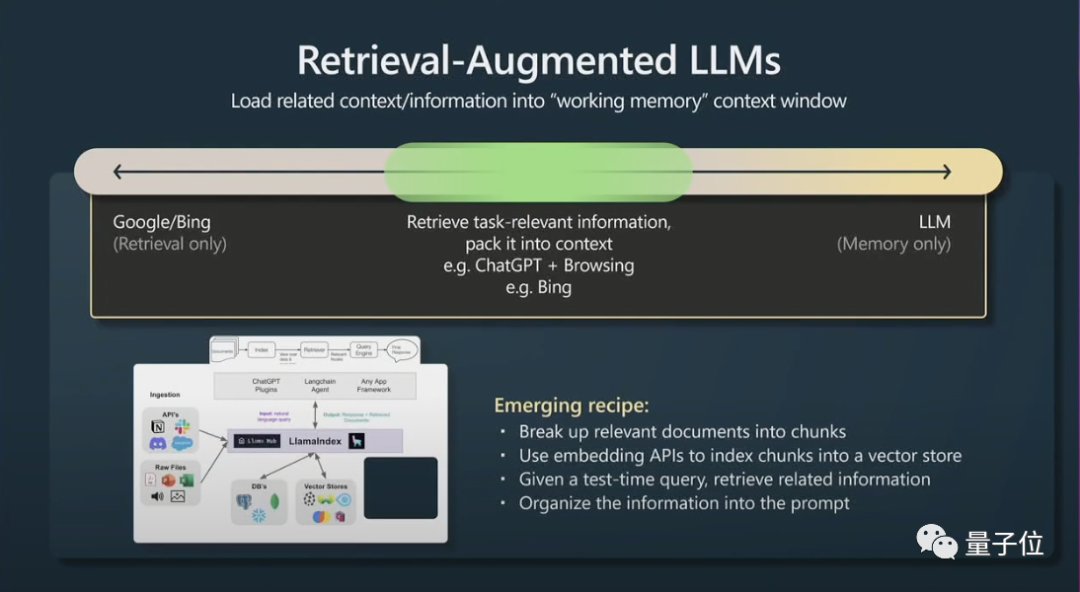
如果Transformers也有可參考的主要文件,它的表現會更好。
最後,Karpathy簡單講了一下在大語言模型中的約束提示(Constraint prompting)和微調。
可以透過約束提示和微調來改進大語言模型。約束提示在大語言模型的輸出中強制執行模板,而微調則調整模型的權重以提高效能。
我建議在低風險的應用中使用大語言模型,始終將它們與人工監督相結合,將它們看作是靈感和建議的來源,考慮copilots而不是讓它們完全自主代理。

#Andrej Karpathy博士畢業後的第一份工作,是在OpenAI研究電腦視覺。
後來OpenAI聯合創始人之一的馬斯克看上了Karpathy,把人挖到了特斯拉。馬斯克和OpenAI因此事不和,最後馬斯克被排除在外。 Karpathy負責特斯拉公司的Autopilot、FSD等專案。
今年二月份,離開特斯拉7個月後,Karpathy再次加入了OpenAI。
最近他發推文表示,目前對開源大語言模型生態系統的發展饒有興趣,有點像早期寒武紀爆發的跡象。
傳送門:
[1]https://www.youtube. com/watch?v=xO73EUwSegU(演講影片)
[2]https://arxiv.org/pdf/2305.10601.pdf(「Tree of thought」論文)
參考連結:
[1]https://twitter.com/altryne/status/1661236778458832896
[2]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
[ 3]https://www.wisdominanutshell.academy/state-of-gpt/
以上是GPT現狀終於有人講清楚了! OpenAI大牛最新演講爆火,還得是馬斯克欽點的天才的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















