

在《聖經》中有一個巴別塔的故事,說是人類聯合起來計劃興建一座高塔,希望能通往天堂,但神擾亂了人類的語言,計劃也就因此失敗。到了今天,AI 技術有望拆除人類語言之間的藩籬,幫助人類創造文明的巴別塔。
近日,Meta 的一項研究向這個方面邁出了重要一步,他們將新提出的方法稱為Massively Multilingual Speech(超多語言語音/ MMS),其以《聖經》作為訓練資料的一部分,得到了以下成果:
對於許多罕見語言的資料稀少問題,Meta 是如何解決的呢?他們採用的方法很有意思,即採用宗教的語料庫,因為像《聖經》這樣的語料具有最「對齊的」語音資料。儘管這個資料集偏向宗教內容並且主要是男性聲音,但其論文表明這個模型在其它領域以及使用女聲時也表現優良。這是基礎模型的湧現行為,著實讓人驚嘆。而更令人驚嘆的是,Meta 將新開發的模型(語音辨識、TTS 和語言辨識)都免費發佈出來了!
為了打造出一個能辨識千言萬語的語音模型,首要的挑戰是收集各種語言的音訊數據,因為現目前已有的最大語音資料集也只有至多100 種語言。為了克服這個問題,Meta 的研究者使用了宗教文本,例如《聖經》,這些文本已被翻譯成了許多不同語言,而那些譯本都已被廣泛研究過。這些譯本都有人們用不同語言閱讀的錄音,而這些音訊也是公開可用的。使用這些音頻,研究者創建了一個資料集,其中包含人們用 1100 種語言閱讀《新約》的音頻,其中每種語言的平均音頻長度為 32 小時。
然後他們又納入了基督教的其它許多讀物的無標註錄音,從而將可用語言數量增加到了 4000 以上。儘管這個資料集領域單一,而且大都是男聲,但分析結果表明 Meta 新開發的模型在女聲上表現也同樣優良,並且該模型也不會格外偏向於產生更宗教式的語言。研究者在部落格中表示,這主要是得益於他們使用的Connectionist Temporal Classification(連結主義時間分類)方法,相較於大型語言模型(LLM)或序列到序列語音辨識模型,這種方法要遠遠更為受限。
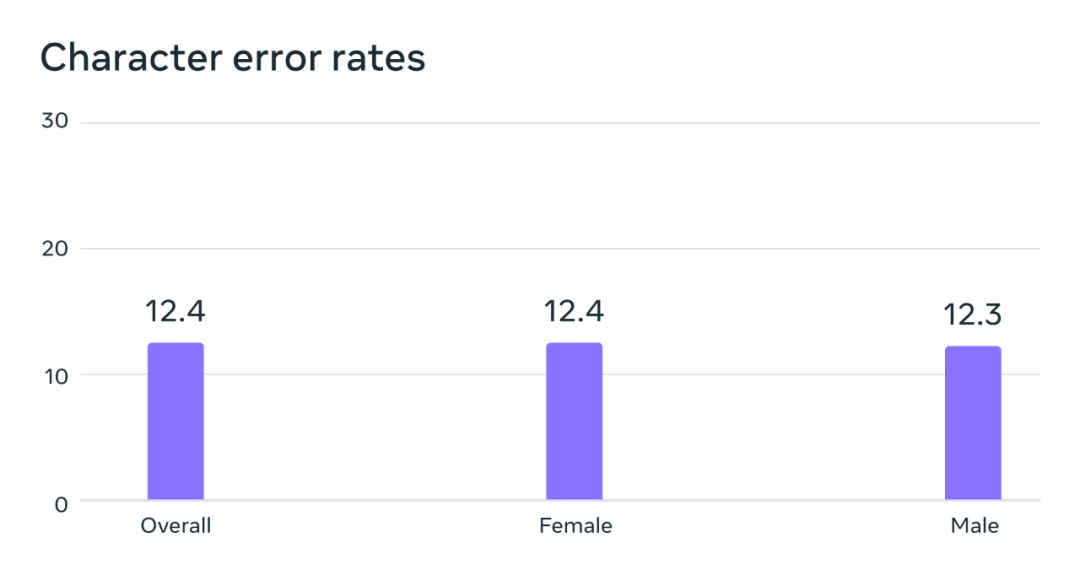
潛在的性別偏誤情況分析。在 FLEURS 基準上,這個在超多語言語音(MMS)資料集上訓練的自動語音辨識模型在男聲和女聲上的錯誤率是差不多的。
為了提升資料質量,使之能被機器學習演算法使用,他們也採用了一些預處理方法。首先,他們在現有的 100 多種語言的資料上訓練了一個對齊模型,然後再搭配使用了一個高效的強制對齊演算法,該演算法可處理 20 分鐘以上的超長錄音。之後,經過多輪對齊過程,最終再執行一步交叉驗證過濾,基於模型準確度移除可能未對齊的資料。為了方便其他研究者創建新的語音資料集,Meta 將該對齊演算法添加到了 PyTorch 並釋放了該對齊模型。
要訓練出普遍可用的監督式語音辨識模型,每種語言只有 32 小時的資料可不夠。因此,他們的模型是基於 wav2vec 2.0 開發的,這是他們先前在自監督語音表徵學習上的研究成果,能大幅減少訓練所需的有標註資料量。具體來說,研究者使用 1400 多種語言的大約 50 萬小時語音資料訓練了一個自監督模型 —— 這個語言數量已經超過之前任何研究的五倍以上了。然後,基於具體的語音任務(例如多語言語音辨識或語言辨識),研究者再對所得模型進行微調。
研究者在一些已有基準上評估了新開發的模型。
其多語言語音辨識模型的訓練使用了含 10 億參數的 wav2vec 2.0 模型,訓練資料集包含 1,100 多種語言。隨著語言數量增加,模型表現確實會下降,但下降幅度非常小:當語言數量從 61 種增加到 1107 種時,字元錯誤率僅上升了 0.4%,但語言覆蓋範圍卻增加了 18 倍以上。
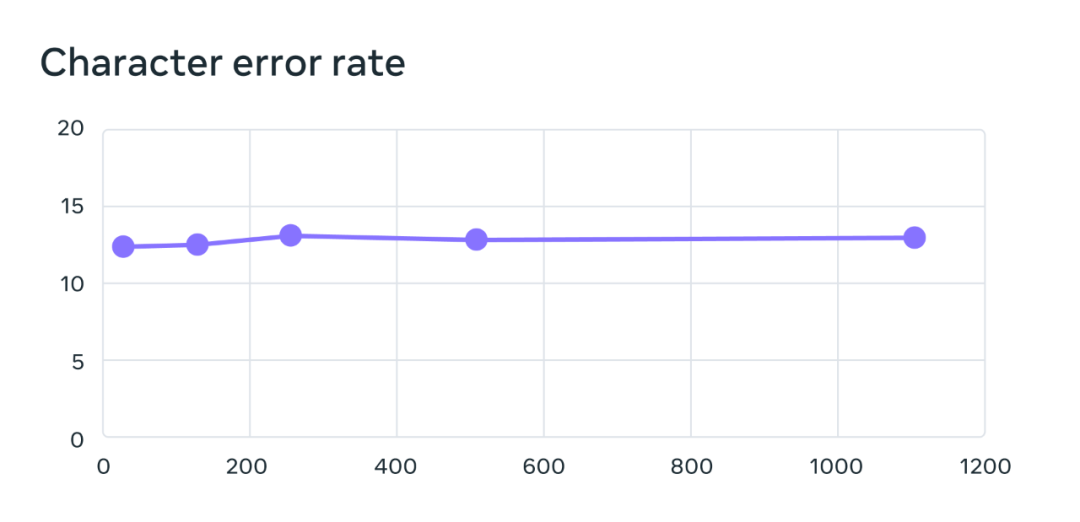
在61 種FLEURS 語言的基準測試上,隨語言數量增長的字元錯誤率變化情況,錯誤率越高,模型越差。
透過比較 OpenAI 的 Whisper 模型,研究者發現他們的模型的單字錯誤率僅有 Whisper 的一半,而同時新模型支援的語言數量還多 11 倍。這個結果足以顯示新方法的卓越能力。
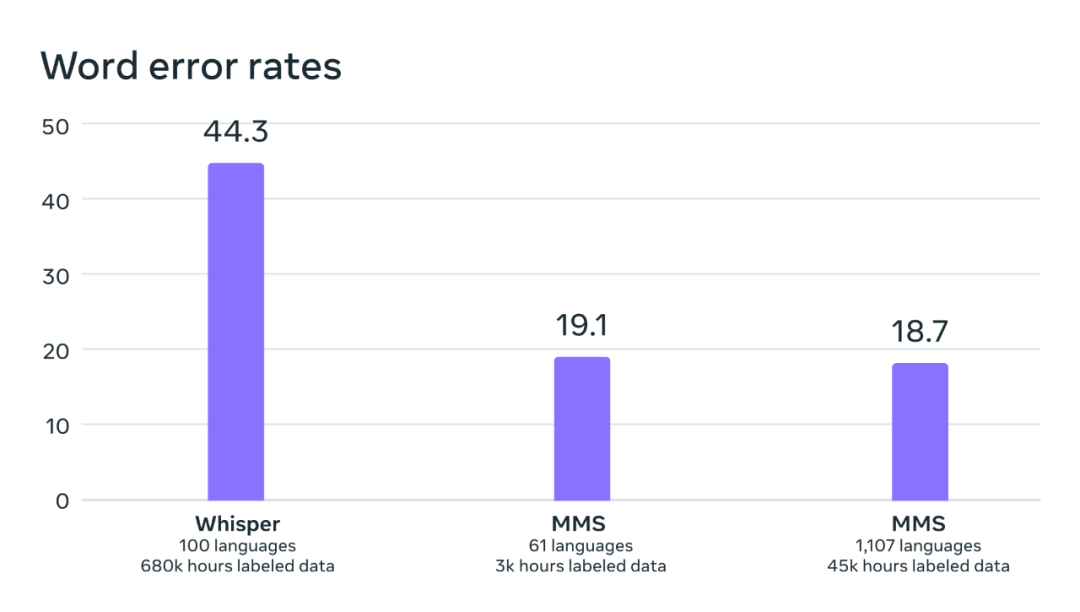
在可直接比較的54 種FLEURS 語言的基準測試上,OpenAI Whisper 與MMS 的單字錯誤率對比。
接下來,使用先前已有的資料集(如FLEURS 和CommonVoice)和新資料集,Meta 的研究者也訓練了一個語言辨識(LID)模型,並在FLEURS LID 任務上進行了評估。結果表明,新模型不僅表現很棒,而且支援的語言數量也增加了 40 倍。
先前的研究在 VoxLingua-107 基準上也僅支援 100 多種語言,而 MMS 支援超過 4000 種語言。
另外 Meta 也建構了一個支援 1100 種語言的文字轉語音系統。目前文字轉語音模型的訓練資料通常是來自單一說話者的語音語料。 MMS 資料的一個限制是許多語言都只有少量說話人,甚至往往只有一個說話者。但是,在建立文字轉語音系統時,這卻成了一個優勢,於是 Meta 就順便創造了一個支援 1100 多種語言的 TTS 系統。研究者表示,這些系統產生的語音品質其實相當好,下面給了幾個例子。
約魯巴語、伊洛科語和邁蒂利語的 MMS 文字轉語音模型演示。
儘管如此,研究者表示 AI 技術都仍不完美,MMS 也是。舉個例子,MMS 在語音轉文字時可能錯誤轉錄選定的單字或片語。這可能導致輸出結果中出現冒犯性和 / 或不準確的語言。研究者強調了與 AI 社群合作共同進行負責任開發的重要性。
世界上有許多語言瀕臨滅絕,而當前的語音辨識和語音生成技術的限制只會進一步加速這一趨勢。研究者在部落格中設想:也許科技能鼓勵人們留存自己的語言,因為有了好的技術後,他們完全可以使用自己喜歡的語言來獲取資訊和使用科技。
他們相信 MMS 專案是朝這個方向邁出的重要一步。他們也表示這個計畫也將繼續開發,未來也將支援更多語言,甚至還會解決方言和口音的難題。
以上是Meta用《聖經》訓練超多語言模型:辨識1107種、辨識4017種語言的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















