

Google未開源的PaLM,網友竟給開源了。
昨天,一位開發者在GitHub上開源了三種微縮版的PaLM模型:參數分別為1.5億(PalM-150m),4.1億(PalM-410m)和10億(PalM-1b)。
計畫網址:https://github.com/conceptofmind/PaLM
這三種模型在GoogleC4資料集進行了訓練,上下文長度為8k。未來,還有20億參數的模型正在訓練中。
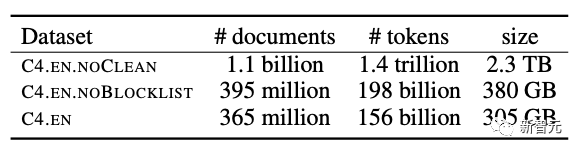
#GoogleC4資料集
使用4.1億參數模型產生的範例:
My dog is very cute, but not very good at socializing with other dogs. The dog loves all new people and he likes to hang out with other dogs . I do need to take him to the park with other dogs. He does have some bad puppy breath, but it is only when he runs off in a direction he doesn't want to go. currently my off in a direction he doesn't want to go. currently my verydog isbeing he doesn . would like to say hi in the park, but would rather take great care of himself for a while. He also has bad breath. I am going to have to get him some oral braces. It's been 3 months. The dog has some biting pains around his mouth. The dog is very timid and scared. The dog gets aggressive towards people. The dog is very playful and they are a little spoiled. I am not sure if it's a dog thing or if . and just wants to play. He plays with his toys all the time and even goes on walks. He is a little picky, not very good with other dogs. The dog is just a little puppy that goes to the park. He is a super friendly dog. He has not had a bad mouth or bad breath
#我的狗很可愛,但是不善於和其他狗交際。這隻狗喜歡所有新來的人,他喜歡和其他的狗一起玩。我確實需要帶他和其他狗一起去公園。他確實有點小狗的口臭,但只有當他往不想去的方向跑的時候。現在我的狗很淘氣。他想在公園打個招呼,但寧願好好照顧自己一段時間。他還有口臭。我得給他買口腔矯正器,已經過了三個月。這條狗狗嘴邊有些咬痕疼痛。這隻狗非常膽小和害怕。這隻狗非常頑皮,他們有點被寵壞了。我不確定是狗的問題還是他被寵壞了。他喜歡他的玩具,只是想玩。他總是玩他的玩具,甚至去散步。他有點挑剔,不太會和其他狗相處。那隻狗隻是一隻去公園的小狗。它是一隻超級友善的狗。他沒有口臭問題了。
雖然參數確實有點少,但這產生的效果還是有些一言難盡…
這些模型相容於許多Lucidrain的流行倉庫,例如Toolformer-pytorch 、PalM-rlhf-pytorch和PalM-pytorch。
最新開源的三種模型都是基準模型,並將在更大規模資料集上進行訓練。
所有的模型將在FLAN上進一步調整指令,以提供flan-PaLM模型。
開源的PaLM模型透過Flash Attention、 Xpos Rotary Embeddings進行訓練,從而實現了更好的長度外推,並使用多查詢單鍵值注意力機制進行更有效率的解碼。
在最佳化演算法方面,採用的則是解耦權重衰減Adam W,但也可以選擇使用Mitchell Wortsman的Stable Adam W。
目前,模型已經上傳到Torch hub,檔案也儲存在Huggingface hub中。
如果模型無法從Torch hub正確下載,請務必清除 .cache/torch/hub/ 中的檢查點和模型資料夾。如果問題仍未解決,那麼你可以從Huggingface的倉庫下載檔案。目前,Huggingface 的整合工作正在進行中。
所有的訓練資料都已經用GPTNEOX標記器進行了預標記,並且序列長度被截止到8192。這將有助於節省預處理資料的大量成本。
這些資料集已經以parquet格式儲存在Huggingface上,你可以在這裡找到各個資料區塊:C4 Chunk 1,C4 Chunk 2,C4 Chunk 3,C4 Chunk 4,以及C4 Chunk 5。
在分散式訓練腳本中還有另一個選項,不使用提供的預標記C4資料集,而是載入和處理另一個資料集,如 openwebtext。
在嘗試執行模型之前,需要先進行一波安裝。
git clone https://github.com/conceptofmind/PaLM.gitcd PaLM/pip3 install -r requirements.txt你可以透過使用Torch hub載入預訓練的模型進行額外的訓練或微調:
#model = torch.hub.load("conceptofmind/PaLM", "palm_410m_8k_v0").cuda()另外,你還可以通下面的方式直接載入PyTorch模型檢查點:
from palm_rlhf_pytorch import PaLMmodel = PaLM(num_tokens=50304, dim=1024, depth=24, dim_head=128, heads=8, flash_attn=True, qk_rmsnorm = False,).cuda()model.load('/palm_410m_8k_v0.pt')要使用模型產生文本,可以使用命令列:
prompt-用於產生文字的提示。
seq _ len-產生文字的序列長度,預設值為256。
temperature-取樣溫度,預設為0.8
#filter_thres-用於取樣的濾波器閾值。預設值為0.9。
model-用於產生的模型。有三種不同的參數(150m,410m,1b):palm_150m_8k_v0,palm_410m_8k_v0,palm_1b_8k_v0。
python3 inference.py "My dog is very cute" --seq_len 256 --temperature 0.8 --filter_thres 0.9 --model "palm_410m_8k_v0"為了提升效能,推理使用torch.compile()、 Flash Attention和Hidet。
如果你想透過添加流處理或其他功能來擴展生成,作者提供了一個通用的推理腳本「inference.py」。
這幾個「開源PalM」模型是在64個A100(80GB)GPU上完成訓練的。
為了方便模型的訓練,作者也提供了一個分散式訓練腳本train_distributed.py。
你可以自由改變模型層和超參數配置以滿足硬體的要求,並且還可以載入模型的權重並改變訓練腳本來微調模型。
最後,作者表示將來會加入一個具體的微調腳本,並對LoRA進行探索。

#可以透過執行build_dataset.py腳本,以類似於訓練期間使用的C4資料集的方式預處理不同的資料集。這將對資料進行預先標記,將資料分成指定序列長度的區塊,並上傳到Huggingface hub。
例如:
python3 build_dataset.py --seed 42 --seq_len 8192 --hf_account "your_hf_account" --tokenizer "EleutherAI/gpt-neox-20b" --dataset_name "EleutherAI/the_pile_deduplicated"2022年4月,Google首次官宣了5400億參數的PaLM。與其他LLM一樣,PaLM能執行各種文字產生和編輯任務。
PaLM是Google首次大規模使用Pathways系統將訓練擴展到6144塊晶片,這是迄今為止用於訓練的基於TPU的最大系統配置。
它的理解能力拔群,不只連笑話都能看懂,還能給看不懂的你解釋笑點在哪。

就在3月中,Google首次開放其PaLM大型語言模型API。

這意味著,人們可以用它來完成總結文字、寫程式碼等任務,甚至是將PaLM訓練成一個像ChatGPT一樣的對話聊天機器人。
在即將召開的Google年度I/O大會上,劈柴將公佈公司在AI領域的最新發展。
據稱,最新、最先進的大型語言模型PaLM 2即將推出。
PaLM 2包含100多種語言,並一直在內部代號「統一語言模型」(Unified Language Model)下運作。它還進行了廣泛的編碼和數學測試以及創意寫作。
上個月,Google表示,其醫學LLM「Med-PalM2」,可以回答醫學考試的問題,在「專家醫生層級」,準確率為85% 。
此外,Google還將發布大模型加持下的聊天機器人Bard,以及搜尋的生成式體驗。
最新AI發布能否讓Google挺直腰板,還得拭目以待。
以上是Google沒開源的PaLM,網友給開源了!千億參數微縮版:最大隻有10億,8k上下文的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































