

數字運算在資料庫中是很常見的需求, 例如計算數量、重量、價格等, 為了滿足各種需求, 資料庫系統通常支持精準的數字類型和近似的數字類型. 精準的數字類型包含int, decimal 等, 這些類型在計算過程中小數點位置是固定的, 其結果和行為比較可預測. 當涉及錢時, 這個問題尤其重要, 因此部分資料庫實現了專門的money 類型. 近似的數字類型包含float, double 等, 這些數字的精度是浮動的.
#decimal 的使用在多數資料庫上都差不多, 下面以MySQL 的decimal 為例, 介紹decimal 的基本使用方法.
與float 和double 不同, decimal 在創建時需要指定兩個描述精確度的數字, 分別是precision 和scale, precision 指整個decimal 包括整數和小數部分一共有多少個數字, scale 指decimal 的小數部分包含多少個數字, 例如:123.45 就是一個precision=5, scale= 2 的decimal. 我們可以在建表時按照這種方式定義我們想要的decimal.
可以在建表時這樣定義一個decimal:
create table t(d decimal(5, 2));
可以插入合法的資料, 例如
insert into t values(123.45); insert into t values(123.4);
此時執行select * from t 會得到
+--------+ | d | +--------+ | 123.45 | | 123.40 | +--------+
注意到123.4 變成了123.40, 這就是精確類型的特點, d 列的每行資料都要求scale=2, 即小數點後有兩位元
當插入不滿足precision 和scale 定義的資料時
insert into t values(1123.45); ERROR 1264 (22003): Out of range value for column 'd' at row 1 insert into t values(123.456); Query OK, 1 row affected, 1 warning show warnings; +-------+------+----------------------------------------+ | Level | Code | Message | +-------+------+----------------------------------------+ | Note | 1265 | Data truncated for column 'd' at row 1 | +-------+------+----------------------------------------+ select * from t; +--------+ | d | +--------+ | 123.46 | +--------+
類似1234.5 (precision=5, scale=1)這樣的數字看起來滿足要求, 但實際上需要滿足scale=2 的要求, 因此會變成1234.50(precision=6, scale=2)也不滿足要求.
計算的結果不受定義的限制, 而是受到內部實現格式的影響, 對於MySQL 結果最大可以到precision=81, scale=30, 但是由於MySQL decimal 的內存格式和計算函數實現問題, 這個大小不是在所有情況都能達到, 將在後文中詳細介紹. 繼續上面的例子中:
select d + 9999.999 from t; +--------------+ | d + 9999.999 | +--------------+ | 10123.459 | +--------------+
結果突破了precision=5, scale=2 的限制, 這裡涉及運算時scale 的變化, 基本規則是:
加法/減法/sum:取兩邊最大的scale
乘法:兩邊的scale 相加
除法:被除數的scale div_precision_increment(取決於資料庫實作)
在這一部分中, 我們主要介紹MySQL 的decimal 實現, 此外也會對比ClickHouse, 看看decimal 在不同系統中的設計與實現差異.
實現decimal 需要思考以下問題
支援多大的precision 和scale
在哪裡儲存scale
在連續乘法或除法時, scale 不斷增長, 整數部分也不斷擴大, 而儲存的buffer 大小總是有上限的, 此時應該如何處理?
除法可能產生無限小數, 如何決定除法結果的scale?
decimal 的表示範圍和計算性能是否有衝突, 是否可以兼顧
先來看看MySQL decimal 相關的資料結構
typedef int32 decimal_digit_t;
struct decimal_t {
int intg, frac, len;
bool sign;
decimal_digit_t *buf;
};MySQL 的decimal 使用一個長度為len 的decimal_digit_t (int32 ) 的陣列buf 來儲存decimal 的數字, 每個decimal_digit_t 最多儲存9 個數字, 用intg 表示整數部分的數字個數, frac 表示小數部分的數字個數, sign 表示符號. 小數部分和整數部分需要分開儲存, 不能混合在一個decimal_digit_t 中, 兩部分都向小數點對齊, 這是因為整數和小數通常需要分開計算, 所以這樣的格式可以更容易地將不同decimal_t 小數和整數分別對齊, 便於加減法運算. len在MySQL 實作中恆為9, 它表示儲存的上限, 而buf 實際有效的部分, 則是由intg 和frac 共同決定. 例如:
// 123.45 decimal(5, 2) 整数部分为 3, 小数部分为 2
decimal_t dec_123_45 = {
int intg = 3;
int frac = 2;
int len = 9;
bool sign = false;
decimal_digit_t *buf = {123, 450000000, ...};
};MySQL 需要使用兩個decimal_digit_t (int32) 來儲存123.45, 其中第一個為123, 結合intg=3, 它就表示整數部分為123, 第二個數字為450000000 (共9 個數字), 由於frac=2, 它表示小數部分為.45
再來看一個大一點的例子:
// decimal(81, 18) 63 个整数数字, 18 个小数数字, 用满整个 buffer
// 123456789012345678901234567890123456789012345678901234567890123.012345678901234567
decimal_t dec_81_digit = {
int intg = 63;
int frac = 18;
int len = 9;
bool sign = false;
buf = {123456789, 12345678, 901234567, 890123456, 789012345, 678901234, 567890123, 12345678, 901234567}
};這個例子用滿了81 個數字, 但是也有些場景無法用滿81 個數字, 這是因為整數和小數部分是分開存儲的,所以一個decimal_digit_t (int32) 可能只儲存了一個有效的小數數字, 但是其餘的部分沒有辦法給整數部分使用, 例如一個decimal 整數部分有62 個數字, 小數部分有19 個數字(precision=81, scale= 19), 那麼小數部分需要使用3 個decimal_digit_t (int32), 整數部分還有54 個數字的餘量, 無法存下62 個數字. 這種情況下, MySQL 會優先滿足整數部分的需求, 自動截斷小數點後的部分, 將它變成decimal(80, 18)
接下来看看 MySQL 如何在这个数据结构上进行运算. MySQL 通过一系列 decimal_digit_t(int32) 来表示一个较大的 decimal, 其计算也是对这个数组中的各个 decimal_digit_t 分别进行, 如同我们在小学数学计算时是一个数字一个数字地计算, MySQL 会把每个 decimal_digit_t 当作一个数字来进行计算、进位. 由于代码较长, 这里不再对具体的代码进行完整的分析, 仅对代码中核心部分进行分析, 如果感兴趣, 可以直接参考 MySQL 源码 strings/decimal.h 和 strings/decimal.cc 中的 decimal_add, decimal_mul, decimal_div 等代码.
准备步骤
在真正计算前, 还需要做一些准备工作:
MySQL 会将数字的个数 ROUND_UP 到 9 的整数倍, 这样后面就可以按照 decimal_digit_t 为单位来进行计算
此外还要针对参与运算的两个 decimal 的具体情况, 计算结果的 precision 和 scale, 如果发现结果的 precision 超过了支持的上限, 那么会按照 decimal_digit_t 为单位减少小数的数字.
在乘法过程中, 如果发生了 2 中的减少行为, 则需要 TRUNCATE 两个运算数, 避免中间结果超出范围.
加法主要步骤
首先, 因为两个数字的 precision 和 scale 可能不相同, 需要做一些准备工作, 将小数点对齐, 然后开始计算, 从最末尾小数开始向高位加, 分为三个步骤:
将小数较多的 decimal 多出的小数数字复制到结果中
将两个 decimal 公共的部分相加
将整数较多的 decimal 多出的整数数字与进位相加到结果中
代码中使用了 stop, stop2 来标记小数点对齐后, 长度不同的数字出现差异的位置.
/* part 1 - max(frac) ... min (frac) */
while (buf1 > stop) *--buf0 = *--buf1;
/* part 2 - min(frac) ... min(intg) */
carry = 0;
while (buf1 > stop2) {
ADD(*--buf0, *--buf1, *--buf2, carry);
}
/* part 3 - min(intg) ... max(intg) */
buf1 = intg1 > intg2 ? ((stop3 = from1->buf) + intg1 - intg2)
: ((stop3 = from2->buf) + intg2 - intg1);
while (buf1 > stop3) {
ADD(*--buf0, *--buf1, 0, carry);
}
乘法主要步骤
乘法引入了一个新的 dec2, 表示一个 64 bit 的数字, 这是因为两个 decimal_digit_t(int32) 相乘后得到的可能会是一个 64 bit 的数字. 在计算时一定要先把类型转换到 dec2(int64), 再计算, 否则会得到溢出后的错误结果. 乘法与加法不同, 乘法不需要对齐, 例如计算 11.11 5.0, 那么只要计算 111150=55550, 再移动小数点位置就能得到正确结果 55.550
MySQL 实现了一个双重循环将 decimal1 的 每一个 decimal_digit_t 与 decimal2 的每一个 decimal_digit_t 相乘, 得到一个 64 位的 dec2, 其低 32 位是当前的结果, 其高 32 位是进位.
typedef decimal_digit_t dec1; typedef longlong dec2;
for (buf1 += frac1 - 1; buf1 >= stop1; buf1--, start0--) {
carry = 0;
for (buf0 = start0, buf2 = start2; buf2 >= stop2; buf2--, buf0--) {
dec1 hi, lo;
dec2 p = ((dec2)*buf1) * ((dec2)*buf2);
hi = (dec1)(p / DIG_BASE);
lo = (dec1)(p - ((dec2)hi) * DIG_BASE);
ADD2(*buf0, *buf0, lo, carry);
carry += hi;
}
if (carry) {
if (buf0 < to->buf) return E_DEC_OVERFLOW;
ADD2(*buf0, *buf0, 0, carry);
}
for (buf0--; carry; buf0--) {
if (buf0 < to->buf) return E_DEC_OVERFLOW;
ADD(*buf0, *buf0, 0, carry);
}
}除法主要步骤
除法使用的是 Knuth's Algorithm D, 其基本思路和手动除法也比较类似.
首先使用除数的前两个 decimal_digit_t 组成一个试商因数, 这里使用了一个 norm_factor 来保证数字在不溢出的情况下尽可能扩大, 这是因为 decimal 为了保证精度必须使用整形来进行计算, 数字越大, 得到的结果就越准确. D3: 猜商, 就是用被除数的前两个 decimal_digit_t 除以试商因数 这里如果不乘 norm_factor, 则 start1[1] 和 start2[1] 都不会体现在结果之中.
D4: 将 guess 与除数相乘, 再从被除数中剪掉结果 然后做一些修正, 移动向下一个 decimal_digit_t, 重复这个过程.
想更详细地了解这个算法可以参考 https://skanthak.homepage.t-online.de/division.html
norm2 = (dec1)(norm_factor * start2[0]); if (likely(len2 > 0)) norm2 += (dec1)(norm_factor * start2[1] / DIG_BASE);
x = start1[0] + ((dec2)dcarry) * DIG_BASE; y = start1[1]; guess = (norm_factor * x + norm_factor * y / DIG_BASE) / norm2;
for (carry = 0; buf2 > start2; buf1--) {
dec1 hi, lo;
x = guess * (*--buf2);
hi = (dec1)(x / DIG_BASE);
lo = (dec1)(x - ((dec2)hi) * DIG_BASE);
SUB2(*buf1, *buf1, lo, carry);
carry += hi;
}
carry = dcarry < carry;ClickHouse 是列存, 相同列的数据会放在一起, 因此计算时通常也将一列的数据合成 batch 一起计算.
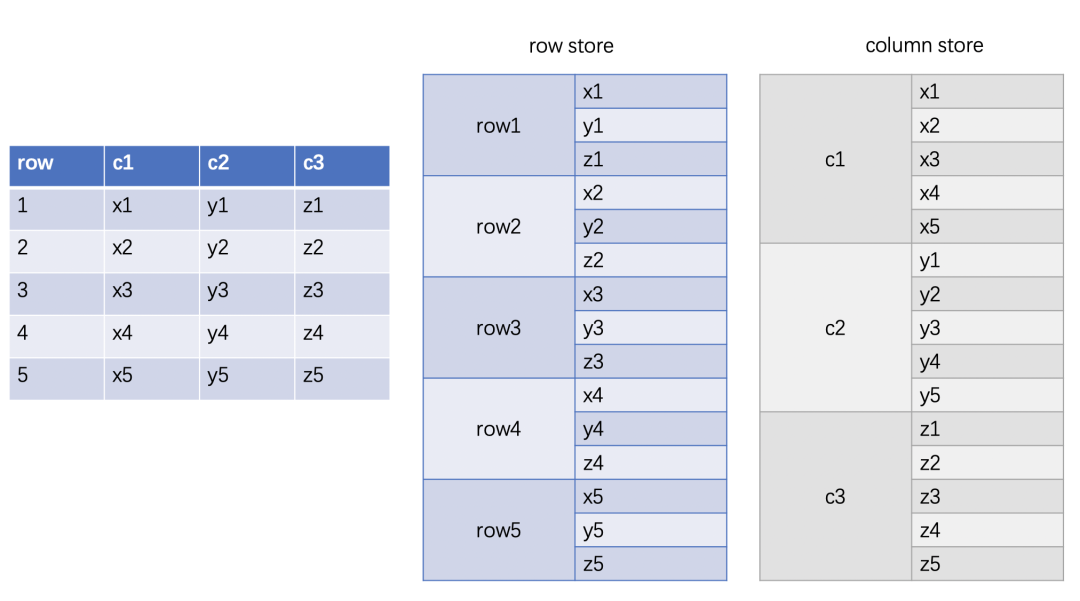
一列的 batch 在 ClickHouse 中使用 PODArray, 例如上图中的 c1 在计算时就会有一个 PODArray, 进行简化后大致可以表示如下:
class PODArray {
char * c_start = null;
char * c_end = null;
char * c_end_of_storage = null;
}在计算时会讲 c_start 指向的数组转换成实际的类型, 对于 decimal, ClickHouse 使用足够大的 int 来表示, 根据 decimal 的 precision 选择 int32, int64 或者 int128. 例如一个 decimal(10, 2), 123.45, 使用这样方式可以表示为一个 int32_t, 其内容为 12345, decimal(10, 3) 的 123.450 表示为 123450. ClickHouse 用来表示每个 decimal 的结构如下, 实际上就是足够大的 int:
template <typename T>
struct Decimal
{
using NativeType = T;
// ...
T value;
};
using Int32 = int32_t;
using Int64 = int64_t;
using Int128 = __int128;
using Decimal32 = Decimal<Int32>;
using Decimal64 = Decimal<Int64>;
using Decimal128 = Decimal<Int128>;显而易见, 这样的表示方法相较于 MySQL 的方法更轻量, 但是范围更小, 同时也带来了一个问题是没有小数点的位置, 在进行加减法、大小比较等需要小数点对齐的场景下, ClickHouse 会在运算实际发生的时候将 scale 以参数的形式传入, 此时配合上面的数字就可以正确地还原出真实的 decimal 值了.
ResultDataType type = decimalResultType(left, right, is_multiply, is_division);
int scale_a = type.scaleFactorFor(left, is_multiply);
int scale_b = type.scaleFactorFor(right, is_multiply || is_division);
OpImpl::vector_vector(col_left->getData(), col_right->getData(), vec_res,
scale_a, scale_b, check_decimal_overflow);例如两个 decimal: a = 123.45000(p=8, s=5), b = 123.4(p=4, s=1), 那么计算时传入的参数就是 col_left->getData() = 123.45000 10 ^ 5 = 12345000, scale_a = 1, col_right->getData() = 123.4 10 ^ 1 = 1234, scale_b = 10000, 12345000 1 和 1234 10000 的小数点位置是对齐的, 可以直接计算.
加法主要步骤
ClickHouse 实现加法同样要先对齐, 对齐的方法是将 scale 较小的数字乘上一个系数, 使两边的 scale 相等. 然后直接做加法即可. ClickHouse 在计算中也根据 decimal 的 precision 进行了细分, 对于长度没那么长的 decimal, 直接用 int32, int64 等原生类型计算就可以了, 这样大大提升了速度.
bool overflow = false;
if constexpr (scale_left)
overflow |= common::mulOverflow(a, scale, a);
else
overflow |= common::mulOverflow(b, scale, b);
overflow |= Op::template apply<NativeResultType>(a, b, res);template <typename T>
inline bool addOverflow(T x, T y, T & res)
{
return __builtin_add_overflow(x, y, &res);
}
template <>
inline bool addOverflow(__int128 x, __int128 y, __int128 & res)
{
static constexpr __int128 min_int128 = __int128(0x8000000000000000ll) << 64;
static constexpr __int128 max_int128 = (__int128(0x7fffffffffffffffll) << 64) + 0xffffffffffffffffll;
res = x + y;
return (y > 0 && x > max_int128 - y) || (y < 0 && x < min_int128 - y);
}乘法主要步骤
同 MySQL, 乘法不需要对齐, 直接按整数相乘就可以了, 比较短的 decimal 同样可以使用 int32, int64 原生类型. int128 在溢出检测时被转换成 unsigned int128 避免溢出时的未定义行为.
template <typename T>
inline bool mulOverflow(T x, T y, T & res)
{
return __builtin_mul_overflow(x, y, &res);
}
template <>
inline bool mulOverflow(__int128 x, __int128 y, __int128 & res)
{
res = static_cast<unsigned __int128>(x) * static_cast<unsigned __int128>(y); /// Avoid signed integer overflow.
if (!x || !y)
return false;
unsigned __int128 a = (x > 0) ? x : -x;
unsigned __int128 b = (y > 0) ? y : -y;
return (a * b) / b != a;
}除法主要步骤
先转换 scale 再直接做整数除法. 本身来讲除法和乘法一样是不需要对齐小数点的, 但是除法不一样的地方在于可能会产生无限小数, 所以一般数据库都会给结果一个固定的小数位数, ClickHouse 选择的小数位数是和被除数一样, 因此需要将 a 乘上 scale, 然后在除法运算的过程中, 这个 scale 被自然减去, 得到结果的小数位数就可以保持和被除数一样.
bool overflow = false;
if constexpr (!IsDecimalNumber<A>)
overflow |= common::mulOverflow(scale, scale, scale);
overflow |= common::mulOverflow(a, scale, a);
if (overflow)
throw Exception("Decimal math overflow", ErrorCodes::DECIMAL_OVERFLOW);
return Op::template apply<NativeResultType>(a, b);MySQL 通过一个 int32 的数组来表示一个大数, ClickHouse 则是尽可能使用原生类型, GCC 和 Clang 都支持 int128 扩展, 这使得 ClickHouse 的这种做法可以比较方便地实现.
MySQL 与 ClickHouse 的实现差别还是比较大的, 针对我们开始提到的问题, 分别来看看他们的解答.
precision 和 scale 范围, MySQL 最高可定义 precision=65, scale=30, 中间结果最多包含 81 个数字, ClickHouse 最高可定义 precision=38, scale=37, 中间结果最大为 int128 的最大值 -2^127 ~ 2^127-1.
在哪里存储 scale, MySQL 是行式存储, 使用火山模型逐行迭代, 计算也是按行进行, 每个 decimal 都有自己的 scale;ClickHouse 是列式存储, 计算按列批量进行, 每行按照相同的 scale 处理能提升性能, 因此 scale 来自表达式解析过程中推导出来的类型.
scale 增长, scale 增长超过极限时, MySQL 会通过动态挤占小数空间, truncate 运算数, 尽可能保证计算完成, ClickHouse 会直接报溢出错.
除法 scale, MySQL 通过 div_prec_increment 来控制除法结果的 scale, ClickHouse 固定使用被除数的 scale.
性能, MySQL 使用了更宽的 decimal 表示, 同时要进行 ROUND_UP, 小数挤占, TRUNCATE 等动作, 性能较差, ClickHouse 使用原生的数据类型和计算最大限度地提升了性能.
在这一部分中, 我们将讲述一些 MySQL 实现造成的违反直觉的地方. 这些行为通常发生在运算结果接近 81 digit 时, 因此如果可以保证运算结果的范围较小也可以忽略这些问题.
乘法的 scale 会截断到 31, 且该截断是通过截断运算数字的方式来实现的, 例如: select 10000000000000000000000000000000.100000000 10000000000000000000000000000000 = 10000000000000000000000000000000.100000000000000000000000000000 10000000000000000000000000000000.555555555555555555555555555555 返回 1, 第二个运算数中的 .555555555555555555555555555555 全部被截断
MySQL 使用的 buffer 包含了 81 个 digit 的容量, 但是由于小数部分必须和整数部分分开, 因此很多时候无法用满 81 个 digit, 例如: select 99999999999999999999999999999999999999999999999999999999999999999999999999.999999 = 99999999999999999999999999999999999999999999999999999999999999999999999999.9 返回 1
计算过程中如果发现整数部分太大会动态地挤占小数部分, 例如: select 999999999999999999999999999999999999999999999999999999999999999999999999.999999999 + 999999999999999999999999999999999999999999999999999999999999999999999999.999999999 = 999999999999999999999999999999999999999999999999999999999999999999999999 + 999999999999999999999999999999999999999999999999999999999999999999999999 返回 1
除法计算中间结果不受 scale = 31 的限制, 除法中间结果的 scale 一定是 9 的整数倍, 不能按照最终结果来推测除法作为中间结果的精度, 例如 select 2.0000 / 3 3 返回 2.00000000, 而 select 2.00000 / 3 3 返回 1.999999998, 可见前者除法的中间结果其实保留了更多的精度.
除法, avg 计算最终结果的小数部分如果正好是 9 的倍数, 则不会四舍五入, 例如: select 2.00000 / 3 返回 0.666666666, select 2.0000 / 3 返回 0.66666667
除法, avg 计算时, 运算数字的小数部分如果不是 9 的倍数, 那么会实际上存储 9 的倍数个小数数字, 因此会出现以下差异:
create table t1 (a decimal(20, 2), b decimal(20, 2), c integer); insert into t1 values (100000.20, 1000000.10, 5); insert into t1 values (200000.20, 2000000.10, 2); insert into t1 values (300000.20, 3000000.10, 4); insert into t1 values (400000.20, 4000000.10, 6); insert into t1 values (500000.20, 5000000.10, 8); insert into t1 values (600000.20, 6000000.10, 9); insert into t1 values (700000.20, 7000000.10, 8); insert into t1 values (800000.20, 8000000.10, 7); insert into t1 values (900000.20, 9000000.10, 7); insert into t1 values (1000000.20, 10000000.10, 2); insert into t1 values (2000000.20, 20000000.10, 5); insert into t1 values (3000000.20, 30000000.10, 2); select sum(a+b), avg(c), sum(a+b) / avg(c) from t1; +--------------+--------+-------------------+ | sum(a+b) | avg(c) | sum(a+b) / avg(c) | +--------------+--------+-------------------+ | 115500003.60 | 5.4167 | 21323077.590317 | +--------------+--------+-------------------+ 1 row in set (0.01 sec) select 115500003.60 / 5.4167; +-----------------------+ | 115500003.60 / 5.4167 | +-----------------------+ | 21322946.369561 | +-----------------------+ 1 row in set (0.00 sec)
以上是mysql資料庫中Decimal類型怎麼使用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















