

最近,一位網友整理了一份「每個LLM開發者都應該知道的數字」,同時解釋了這些數字為何重要,以及我們應該如何利用它們。
他在Google的時候,就有一份由傳奇工程師Jeff Dean整理的文件,叫做「每個工程師都應該知道的數字」。

Jeff Dean:「每個工程師都應該知道的數字」
而對於LLM(Large Language Model)開發者來說,有一組類似的用於粗略估算的數字也是非常有用的。

#40-90%:在提示中加入「簡明扼要」之後節省的成本
要知道,你是依照LLM在輸出時用掉的token來付費的。
這意味著,讓模型簡潔扼要(be concise)地進行表述,可以省下很多錢。
同時,這個理念還可以擴展到更多地方。
例如,你本來想用GPT-4產生10個備選方案,現在也許可以先要求它提供5個,就可以留下另一半的錢了。
1.3:每個字的平均token數
#LLM是以token為單位進行運算的。
而token是單字或單字的子部分,例如「eating」可能會分解成兩個token「eat」和「ing」。
一般來說,750個英文單字會產生大約1000個token。
對於英語以外的語言,每個單字的token會增加,具體數量取決於它們在LLM的嵌入語料庫中的通用性。

#考慮到LLM的使用成本很高,因此和價格相關的數字就變得尤為重要了。
~50:GPT-4與GPT-3.5 Turbo的成本比
使用GPT-3.5-Turbo大約比GPT-4便宜50倍。說「大約」是因為GPT-4對提示和產生的收費方式不同。
所以在實際應用時,最好確認GPT-3.5-Turbo是不是就足夠完成你的需求。
例如,對於概括總結這樣的任務,GPT-3.5-Turbo綽綽有餘。


5:使用GPT- 3.5-Turbo與OpenAI嵌入進行文字產生的成本比
這表示在向量儲存系統中尋找某個內容比使用用LLM產生便宜得多。
具體來說,在神經資訊檢索系統中查找,比向GPT-3.5-Turbo提問要少花約5倍的費用。與GPT-4相比,成本差距更是高達250倍!
10:OpenAI嵌入與自我託管嵌入的成本比
注意:這個數字對負載和嵌入的批次大小非常敏感,因此請將其視為近似值。
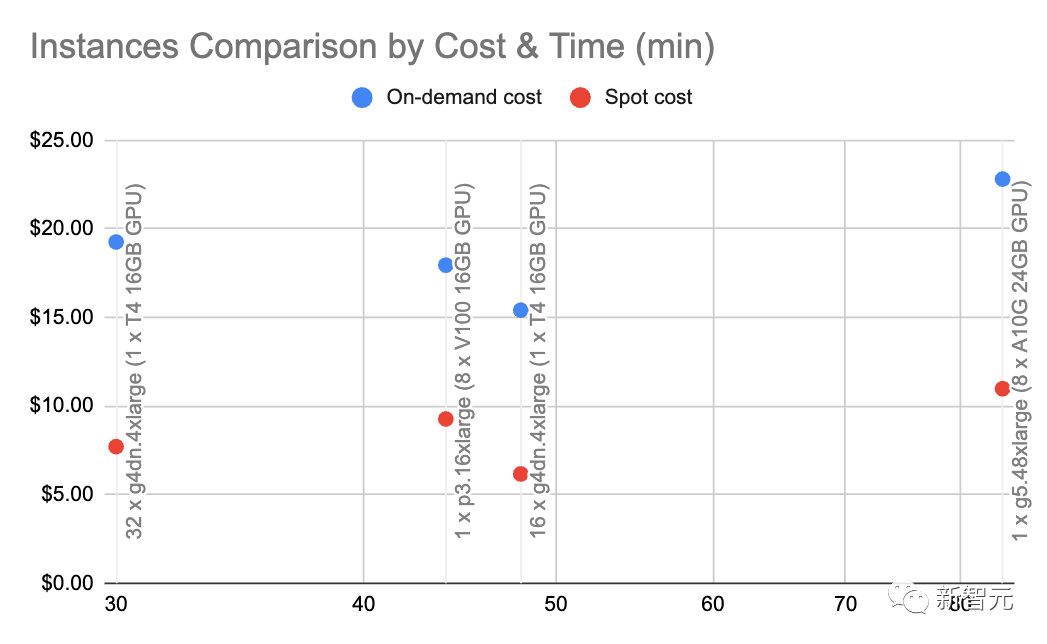
透過g4dn.4xlarge(按需價格:1.20美元/小時),我們可以利用用HuggingFace的SentenceTransformers(與OpenAI的嵌入相當)以每秒約9000個token的速度進行嵌入。
在這種速度和節點類型下進行一些基本的計算,顯示自我託管的嵌入可以便宜10倍。
6:OpenAI基礎模型與微調模型查詢的成本比
在OpenAI上,微調模型的成本是基礎模型的6倍。
這也意味著,比起微調客製化模型,調整基礎模型的提示更具成本效益。
1:自我託管基礎模型與微調模型查詢的成本比
如果你自己託管模型,那麼微調模型和基礎模型的成本幾乎相同:這兩種模型的參數數量是一樣的。
~100萬美元:在1.4兆個token上訓練130億參數模型的成本
#論文網址:https://arxiv.org/pdf/2302.13971.pdf
LLaMa的論文中提到,他們花了21天的時間,使用了2048個A100 80GB GPU,才訓練出了LLaMa模型。
假設我們在Red Pajama訓練集上訓練自己的模型,假設一切正常,沒有任何崩潰,並且第一次就成功,就會得到上述的數字。
此外,這個過程還涉及2048個GPU之間的協調。
大多數公司,並沒有條件做到這些。
不過,最關鍵的訊息是:我們有可能訓練出自己的LLM,只是這個過程並不便宜。
並且每次運行,都需要好幾天時間。
相較之下,使用預訓練模型,會便宜得多。
< 0.001:微調與從頭開始訓練的成本費率
這個數字有點籠統,總的來說,微調的成本可以忽略不計。
例如,你可以用大約7美元的價格,微調一個6B參數的模型。
即使按照OpenAI對其最昂貴的微調模型Davinci的費率,每1000個token也只要花費3美分。
這意味著,如果要微調莎士比亞的全部作品(大約100萬個字),只需要花費四、五十美元。
不過,微調是一回事,從頭開始訓練,就是另一回事了...
如果您正在自架模型,了解GPU顯存就非常重要,因為LLM正在將GPU的顯存推向極限。
以下統計資訊專門用於推理。如果要進行訓練或微調,就需要相當多的顯存。
V100:16GB,A10G:24GB,A100:40/80GB:GPU顯存容量
#了解不同類型的GPU的顯存量是很重要的,因為這將限制你的LLM可以擁有的參數量。
一般來說,我們喜歡使用A10G,因為它們在AWS上的按需價格是每小時1.5到2美元,並且用24G的GPU顯存,而每個A100的價格約為5美元/小時。
2x 參數量:LLM的典型GPU顯存需求
舉個例子,當你擁有一個70億參數的模型時,就需要約14GB的GPU顯存。
這是因為大多數情況下,每個參數需要一個16位元浮點數(或2個位元組)。
通常不需要超過16位元精度,但大多數時候,當精度達到8位元時,解析度就開始降低(在某些情況下,這也可以接受)。
當然,也有一些專案改善了這種情況。例如llama.cpp就透過在6GB GPU上量化到4位(8位也可以),跑通了130億參數的模型,但這並不常見。
~1GB:嵌入模型的典型GPU顯存需求
每當你嵌入語句(聚類、語意當搜尋和分類任務經常要做的事)時,你就需要一個像語句轉換器這樣的嵌入模型。 OpenAI也有自己的商用嵌入模式。
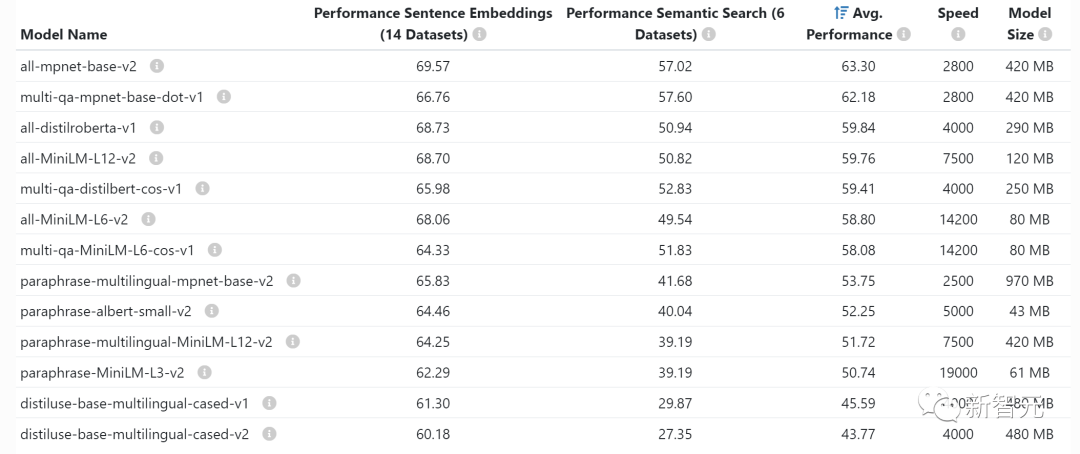
通常不必擔心GPU上的顯存嵌入佔用多少,它們相當小,甚至可以在同一GPU上嵌入LLM 。
>10x:透過批次LLM請求,提高吞吐量
##透過GPU執行LLM查詢的延遲非常高:吞吐量為每秒0.2個查詢的話,延遲可能需要5秒。
有趣的是,如果你執行兩個任務,延遲可能只需要5.2秒。
這意味著,如果能將25個查詢捆綁在一起,則需要大約10秒的延遲,而吞吐量已提高到每秒2.5個查詢。
不過,請接著往下看。
~1 MB:130億參數模型輸出1個token所需的GPU記憶體
你所需要的顯存與你想產生的最大token數量直接成正比。
例如,產生最多512個token(大約380個單字)的輸出,就需要512MB的記憶體。
你可能會說,這沒什麼大不了的──我有24GB的顯存,512MB算什麼?然而,如果你想運行更大的batch,這個數值就會開始累積了。
例如,如果你想做16個batch,記憶體就會直接增加到8GB。
以上是模仿Jeff Dean神總結,前Google工程師分享「LLM開發秘籍」:每個開發者都應知道的數字!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















