

導讀
1、為什麼Chatbot需要大語言模型 向量資料庫?
這個春天,最讓人震感的科技產品莫過於ChatGPT的橫空出世,透過大語言模型(LLM)讓人們看到了生成式AI能實現到和人類語言高度相仿的語言表達能力,AI不再遙不可及而已經可以走進人類的工作和生活,這使得沉寂一段時間的AI領域重新煥發了能量,無數的從業者正趨之若鷯地投身於下一個改變時代的機會;據不完全統計,在短短的4個月時間內,美國已經完成了超4000筆的生成式AI的行業融資。在下一代技術中,生成式AI已成為資本和企業不容忽視的一部分,越來越需要更高水準的基礎設施能力來支持其發展。
#大模型能夠回答較為普世的問題,但是若要服務於垂直專業領域,會存在知識深度和時效性不足的問題,那麼企業如何抓住機會並構建垂直領域服務?目前有兩種模式,第一種是基於大模型之上做垂直領域模型的Fine Tune,這個綜合投入成本較大,更新的頻率也較低,並不適用於所有的企業;第二種就是在向量資料庫中建構企業自有的知識資產,透過大模型向量資料庫來建構垂直領域的深度服務,本質是使用資料庫進行提示工程(Prompt Engineering)。企業可以藉助垂直類別的法律條文和先例,在法律業等特定領域建構法律科技服務。如法律科技公司Harvey,正在建構「律師的副駕駛」(Copilot for Lawyer)以提高法律條文的起草和研究服務。將企業知識庫文件和即時資訊透過向量特徵提取然後儲存到向量資料庫,結合LLM大語言模型可以讓Chatbot(問答機器人)的答案更具專業性和時效性,建立企業專屬Chatbot。
如何基於大語言模型讓Chatbot更好回答時事問題 ?歡迎移步「阿里雲瑤池資料庫」影片號碼觀看示範
##。
#本文接下來將重點介紹基於大語言模型( LLM) 向量資料庫打造企業專屬Chatbot的原理與流程,以及ADB-PG建構此場景的核心能力。
2、什麼是向量資料庫?
向量資料庫對於特徵向量的快速檢索,一般會採用建構向量索引的技術手段,我們通常說的向量索引都屬於ANNS(Approximate Nearest Neighbors Search,近似最近鄰搜尋),它的核心思想是不再局限於只返回最精確的結果項,而是僅搜尋可能是近鄰的資料項,也就是透過犧牲可接受範圍內的一點精確度來換取檢索效率的提高。這也是向量資料庫與傳統資料庫最大的差別。
#目前在實際生產環境中,業界有兩種主要實踐方式,以更方便地應用ANNS向量索引。一種是單獨將ANNS向量索引服務化,以提供向量索引建立和檢索的能力,從而形成專有的向量資料庫;另一種是將ANNS向量索引整合到傳統結構化資料庫中,形成一種具有向量檢索功能的DBMS。在實際的業務場景中,專有的向量資料庫往往都需要和其他傳統資料庫配合起來一起使用,這樣會造成一些比較常見的問題,如資料冗餘、資料遷移過多、資料一致性問題等,與真正的DBMS相比,專有的向量資料庫需要額外的專業人員維護、額外的成本,以及非常有限的查詢語言能力、可程式化、可擴展性和工具整合。
#而融合了向量檢索功能的DBMS則不同,它首先是一個非常完備的現代資料庫平台,能滿足應用程式開發人員的資料庫功能需求;然後它整合的向量檢索能力一樣也可以實現專有的向量資料庫的功能,並且使向量儲存和檢索繼承了DBMS的優秀能力,如易用性(直接使用SQL的方式處理向量)、事務、高可用性、高擴充性等等。
#本文介紹的ADB-PG即是具有向量檢索功能的DBMS,在包含向量檢索功能的同時,也具備一站式的資料庫能力。在介紹ADB-PG的具體能力之前,我們先來看看Demo影片中Chatbot的建立流程和相關原理。
#對於前面Demo影片結合大語言模型LLM和ADB-PG進行時事新聞點評解答的例子,讓LLM回答「通義千問是什麼」。可以看到,如果我們讓LLM直接回答,得到的答案沒有意義,因為LLM的訓練資料集裡並不包含相關的內容。而當我們使用向量資料庫作為本地知識存儲,讓LLM自動提取相關的知識之後,其正確地回答了「通義千問是什麼」。
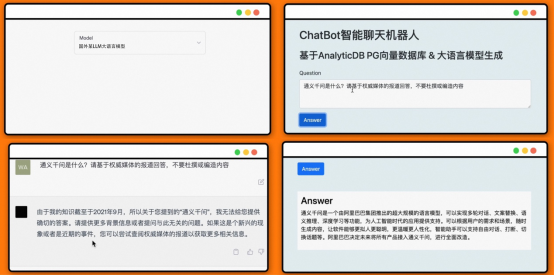
#回答「通義千問是什麼”
#這種處理方式可以同樣適用於處理未被LLM訓練資料集涵蓋的文件、PDF、電子郵件、網路資訊等內容。例如:
##本地知識問答系統(Local QA System)主要是透過結合了大語言模型的推理能力和向量資料庫的儲存和檢索能力。透過向量檢索來獲取最相關的語意片段,以此為基礎讓大語言模型結合相關片段上下文進行推理,從而得出正確的結論。在這個過程中主要有兩個流程:
#a. 後端資料處理與儲存流程
#b. 前端問答流程
同時其底層主要依賴兩個模組:
1. 基於大語言模型的推理模組
2. 基於向量資料庫的向量資料管理模組
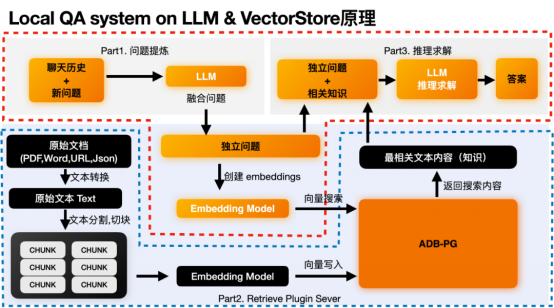
Local QA system on LLM & VectorStore原理
上圖黑色的部分為後端的資料處理流程,主要是將我們的原始資料求解embedding,並且和原始將資料一起存入向量資料庫ADB-PG。這裡你只需要注意上圖的藍色虛線框部分。黑色的處理模組和ADB-PG向量資料庫。
在這個過程中主要分為三個部分:1.問題提煉部分;2.向量檢索擷取最相關知識;3.推理求解部分。 在這裡我們需要關注橘色部分。單單說原理可能比較晦澀,我們還是用上面的例子來說明。
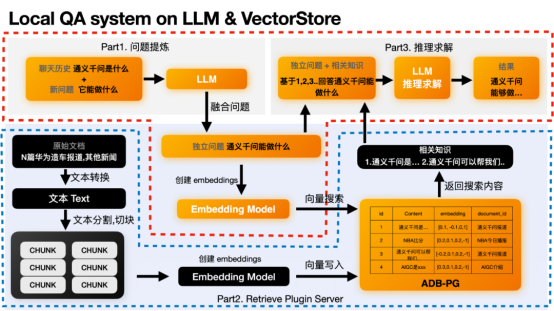
#Local QA system on LLM & VectorStore
Part1 問題提煉
#這個部分是可選的,之所以存在是因為有些問題是需要依賴上下文的。因為使用者問的新問題可能沒辦法讓LLM理解這個使用者的意圖。
#例如使用者的新問題是「它能做什麼」。 LLM並不知道它指的是誰,需要結合先前的聊天歷史,例如「通義千問是什麼」來推理出使用者需要求解答案的獨立問題「通義千問能做什麼」。 LLM無法正確回答「它有什麼用」這樣的模糊問題,但是能正確回答「通義千問有什麼用」這樣的獨立問題。如果你的問題本身就是獨立的,則不需要這個部分。
#得到獨立問題後,我們可以基於這個獨立問題,來求取這個獨立問題的embedding。然後去向量資料庫中搜尋最相似的向量,找出最相關的內容。這個行為在Part2 Retrieval Plugin的功能中。
#Part2 向量檢索
獨立問題求取embedding這個功能會在text2vec模型中進行。在取得embedding之後就可以透過這個embedding來搜尋已經事先儲存在向量資料庫中的資料了。例如我們已經在ADB-PG儲存了下面內容。我們就可以透過求取的向量來獲得最相近的內容或知識,例如第一條和第三條。通義千問是...,通義千問可以幫助我們xxx。
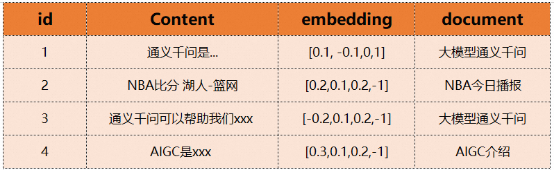
Part3 推理求解
在獲得最相關的知識之後,我們就可以讓LLM基於最相關的知識和獨立問題來進行求解推理,得到最終的答案了。這裡就是結合“通義千問是...”,“通義千問可以幫助我們xxx”等等最有效的信息來回答“通義千問有什麼用”這個問題了。最後讓GPT的推理求解大致是這樣:

4、ADB-PG:內建向量擷取全文檢索的一站式企業知識資料庫
#為什麼ADB-PG適合作為Chatbot的知識資料庫? ADB-PG是一款具備大規模平行處理能力的雲端原生資料倉儲。它支援行存儲和列存儲模式,既可以提供高效能的離線資料處理,也可以支援高並發的海量資料線上分析查詢。因此我們可以說ADB-PG是一個支援分散式事務、混合負載的資料倉儲平台,同時也支援處理多種非結構化和半結構化資料來源。如透過向量檢索外掛實現了圖片、語言、影片、文字等非結構化資料的高效能向量檢索分析,對JSON等半結構化資料的全文檢索分析。
#因此在AIGC場景下,ADB-PG既可以作為向量資料庫滿足其對向量儲存和檢索的需求,也可以滿足其他結構化資料的儲存和查詢,同時也可以提供全文檢索的能力,為AIGC場景下的業務應用提供一站式的解決方案。以下我們將對ADB-PG的向量檢索、融合檢索和全文檢索這三個面向的能力進行詳細介紹。
#ADB-PG向量擷取與融合檢索功能於2020年首次在公有雲上線,目前在人臉辨識領域得到了非常廣泛的應用。 ADB-PG的向量資料庫繼承自資料倉儲平台,因此它幾乎擁有DBMS的所有好處,如ANSISQL、ACID事務、高可用性、故障復原、時間點復原、可程式化、可擴充性等。同時它支援了點積距離、漢明距離和歐氏距離的向量和向量的相似度搜尋。這些功能目前在人臉辨識、商品辨識和基於文字的語意搜尋中得到了廣泛應用。隨著AIGC的爆炸式增長,這些功能為基於文字的Chatbot奠定了堅實的基礎。另外,ADB-PG向量檢索引擎也使用Intel SIMD指令極為有效地實現了向量相似性匹配。
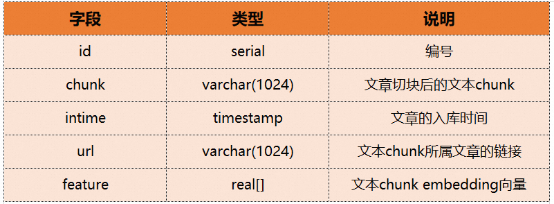
#下面我們用一個具體的例子來說明ADB- PG的向量檢索和融合檢索如何使用。假設有一個文字知識庫,它是將一批文章分割成chunk再轉換為embedding向量後入庫的,其中chunks表包含以下字段:

#那麼對應的建表DDL如下:

############### ###同時為了對向量結構化融合查詢提供加速,我們還需要為常用的結構化列建立索引:###############

在進行資料插入的時候,我們可以直接使用SQL中的insert語法:

在這個例子中,如果我們要透過文字搜尋它的來源文章,那麼我們就可以直接透過向量檢索來查找,具體SQL如下:

#同樣,如果我們的需求是尋找最近一個月以內的某個文本的來源文章。那我們就可以直接透過融合檢索來查找,具體SQL如下:

##在看完上面的範例之後,我們可以很清楚地發現,在ADB-PG中使用向量檢索和融合檢索就跟使用傳統資料庫一樣方便,沒有任何的學習門檻。同時,我們對向量檢索也有針對性地做了很多優化,例如向量資料壓縮、向量索引並行建構、向量多分區並行檢索等等,這裡不再詳述。
#ADB-PG同時也有豐富的全文檢索功能,支援複雜組合條件、結果排名等檢索能力;另外對於中文資料集,ADB-PG也支援中文分詞功能,能夠高效、自訂地對中文文本加工分詞;同時ADB-PG也支援使用索引加速全文檢索分析性能。這些能力同樣也可以在AIGC業務場景下得到充分的使用,如業務可以對知識庫文件結合上述向量檢索和全文檢索能力進行雙路召回。
#知識資料庫搜尋部分包括傳統的關鍵字全文檢索和向量特徵檢索,關鍵字全文檢索保證查詢的精準性,向量特徵檢索提供泛化性和語義匹配,除字面匹配之外召回和語義匹配的知識,降低無結果率,為大模型提供更加豐富的上下文,有利於大語言模型進行總結歸納。
5、總結#結合本文前面所提到的內容,如果把滿腹經綸的Chatbot比喻為人#,那麼大語言模型可以看成是Chatbot在大學畢業前從所有書籍和各領域公開資料所獲得的知識和學習推理能力。所以基於大語言模型,Chatbot能夠回答截止到其畢業前相關的問題,但如果問題涉及到特定專業領域(相關資料為企業組織專有,非公開)或者是新出現的物種概念(大學畢業時尚未誕生),僅靠在學校的知識所得(對應預訓練的大語言模型)則無法從容應對,需要具備畢業後持續獲得新知識的管道(如工作相關專業學習資料庫),結合本身的學習推理能力,來做出專業應對。
同樣的Chatbot需要結合大語言模型的學習推理能力,和像ADB-PG這樣包含向量檢索和全文檢索能力的一站式資料庫(儲存了企業組織專有的以及最新的知識文件和向量特徵),在應對問題時具備基於該資料庫中的知識內容來提供更專業更具時效性的回答。
以上是阿里雲AnalyticDB(ADB) + LLM:建構AIGC時代下企業專屬Chatbot的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















