

雖然大型預訓練語言模型(LLM)在一系列下游任務中展現出飛速提升的性能,但它們是否真的理解其使用和生成的文本語義?
長期以來,AI社群對這個問題存在著很大的分歧。有一種猜測是,純粹基於語言的形式(例如訓練語料庫中token的條件分佈)進行訓練的語言模型不會獲得任何語義。相反,它們僅僅是根據從訓練資料中收集的表面統計相關性來產生文本,其強大的湧現能力則歸因於模型和訓練資料的規模。這部分人將LLM稱為「隨機鸚鵡」。
但也有一部分人不認同此觀點。一項最近的研究表明,大約51%的NLP社群受訪者同意:「一些僅透過文字訓練的生成模型,在擁有足夠的資料和計算資源的情況下,可以以某種有意義的方式理解自然語言(超越表面層面的統計關聯,涉及對語言背後的語義和概念的理解)」。
為了探討這個懸而未決的問題,來自MIT CSAIL的研究人員展開了詳細研究。

#論文地址:https://paperswithcode.com/paper/evidence-of- meaning-in-language-models
該研究使用的語言模型僅訓練成為文本預測下一個token的模型,並製定兩個假設:
為了探究H1 和H2兩個假設的正確性,研究將語言建模應用於程式合成任務,即在給定輸入輸出範例形式規範的情況下合成程序。研究採用這種方法的主要是因為程式的意義(和正確性)完全由程式語言的語義決定。
具體來說,研究在程式及其規範的語料庫上訓練語言模型(LM),然後使用線性分類器來探測 LM 對於程式語意表徵的隱藏狀態。研究發現探測器提取語義的能力在初始化時是隨機的,然後在訓練期間經歷相變,這種相變與 LM 在未見過規範的情況下生成正確程序的能力強相關。此外,該研究還展示了一項介入實驗的結果,該實驗表明語義在模型狀態中得以表徵(而不是透過探測器(probe)進行學習)。
該研究的主要貢獻包括:
1、實驗結果表明,在執行預測下一個token任務的LM 中出現了有意義的表徵。具體來說,該研究使用經過訓練的 LM 在給定幾個輸入輸出範例的情況下生成程序,然後訓練一個線性探測器,以從模型狀態中提取有關程序狀態的資訊。研究者發現內部表徵包含以下線性編碼:(1) 抽象語意(抽象解釋)-在程式執行過程中追蹤指定輸入;(2) 與尚未產生的程式token對應的未來程式狀態預測。在訓練期間,這些語意的線性表徵與 LM 在訓練步驟中產生正確程序的能力同步發展。
2、研究設計並評估了一種新穎的介入(interventional)方法,以探究從表徵中提取意義時LM 和偵測器的貢獻。具體來說,研究試圖分析以下兩個問題中哪一個成立:(1) LM 表徵包含純(句法)轉錄物(transcript),同時偵測器學習解釋轉錄本以推斷意義;(2)LM 表徵包含語意狀態,探測器只是從語義狀態中提取含義。實驗結果表明 LM 表徵實際上與原始語義對齊(而不是僅僅編碼一些詞彙和句法內容),這說明假設H2是錯誤的。
3、研究顯示 LM 的輸出與訓練分佈不同,具體表現為LM 傾向於產生比訓練集的程序更短的程序(並且仍然是正確的)。雖然 LM 合成正確程序的能力有所提高,但LM 在訓練集中的程序上的困惑度仍然很高,這表明假設H1是錯誤的。
總的來說,研究提出了一個框架,根據程式語言的語義對 LM 進行實證研究。這種方法使我們能夠定義、測量和試驗來自底層程式語言的精確形式語義的概念,從而有助於理解當前 LM 的湧現能力。
研究使用追蹤語意作為程式意義模型。作為程式語言理論中一個基礎主題,形式語義學主要研究如何正式地為語言中的字串分配語義。研究使用的語意模型包括追蹤程式的執行:給定一組輸入(即變數賦值),一個(句法)程式的意思是用從表達式中計算出的語意值來識別的,追蹤軌跡是根據輸入執行程式時產生的中間值序列。
將追蹤軌跡用於程式意義模型有幾個重要原因:首先,準確追蹤一段程式碼的能力與解釋程式碼的能力直接相關;其次,電腦科學教育也強調追蹤是理解程式開發和定位推理錯誤的重要方法;第三,專業的程式開發依賴基於追蹤的偵錯器(dbugger)。
本研究使用的訓練集包含100萬個隨機抽樣的Karel程式。在1970年代,史丹佛大學畢業生 Rich Pattis 設計了一個程式環境,讓學生教導機器人來解決簡單的問題,這個機器人被稱為Karel機器人。
研究透過隨機取樣來建構訓練樣本的參考程序,然後取樣5個隨機輸入並執行程序得到對應的5個輸出。 LM 被訓練為對樣本語料庫執行下一個token預測。在測試時,研究只提供輸入輸出前綴給LM,並使用貪心解碼完成程式。下圖1描繪了一個實際的參考程序和經過訓練的 LM 的完成情況。
該研究訓練了一個現成的 Transformer 模型對資料集執行下一個token預測。經過 64000 個訓練步驟(training step),大約 1.5 個 epoch,最終訓練好的 LM 在測試集上達到了 96.4% 的生成準確率。每 2000 個訓練步驟,研究會擷取一個追蹤資料集。對於每個訓練軌跡資料集,該研究訓練一個線性探測器來預測給定模型狀態的程式狀態。
研究者對以下假設進行了研究:在訓練語言模型執行下一個token預測的過程中,語義狀態的表示會作為副產品出現在模型狀態。考慮到最終訓練得到的語言模型達到了96.4%的生成準確性,如果否定這個假設,將與H2一致,即語言模型已經學會「僅僅」利用表面統計來一致生成正確的程序。
為了測試這個假設,研究者訓練了一個線性探測器,將語義狀態從模型狀態中提取出來,作為5個獨立的4-way任務(每個輸入面向一個方向),如第2.2節所述。
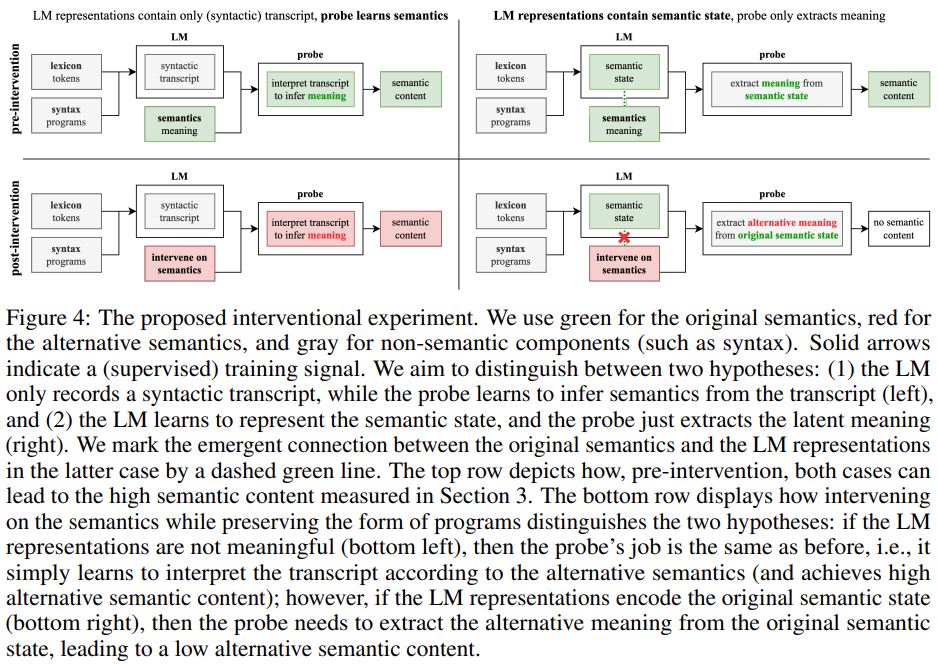
意義的湧現與生成準確度呈正相關
#圖2展示了主要結果。研究者的第一個觀察結果是,語意內容從隨機猜測的基線表現(25%)開始,並且在訓練過程中顯著增加。這個結果表明,語言模型的隱藏狀態確實包含語義狀態的(線性)編碼,而關鍵的是,這種意義是在一個純粹用於對文本執行下一個token預測的語言模型中出現的。
將產生準確度與語意內容進行線性迴歸,二者在訓練步驟中呈現出意外的強大且具有統計意義的線性相關性(R2 = 0.968, p < ; 0.001),即LM合成正確程序的能力的變化幾乎完全由LM的隱藏層的語義內容所解釋。這表明,在本文的實驗設定範圍內,學習建模正確程序的分佈與學習程序的意義直接相關,這否定了語言模型無法獲得意義的觀點(H2)。
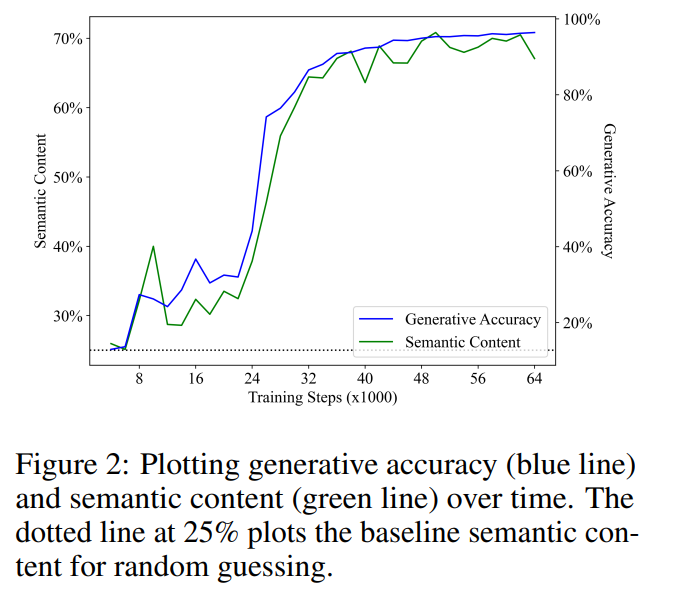
表徵是對未來程式語意的預測
#前一節討論了語言模型能否表示其生成的文本的意義。本文的結果對這個問題給出了積極的答案,即語言模型能夠(抽像地)解釋生成的程序。然而,解釋者(interpreter)並不等同於合成者(synthesizer),僅有理解能力是不足以進行生成的。就人類語言的產生而言,廣泛的共識是語言起源於思考中的一種非言語的訊息,然後轉化為反映初始概念的話語(utterance)。研究者假設訓練後的語言模型的生成過程遵循類似的機制,即語言模型的表示編碼了尚未生成的文本的語義。
為了驗證這個假設,他們使用與上述相同的方法訓練了一個線性探測器,來預測從模型狀態中得到的未來語意狀態。需要注意的是,由於他們使用貪婪解碼策略,未來的語義狀態也是確定性的,因此這個任務是明確定義的。
圖3展示了線性探測器在預測未來1步和2步的語義狀態方面的表現(綠段線表示“Semantic ( 1)”,綠點線表示“ Semantic ( 2)”)。與先前的結果類似,探測器的表現從隨機猜測的基線開始,然後隨著訓練顯著提高,並且他們還發現未來狀態的語義內容與生成準確性(藍線)在訓練步驟中呈現出強烈的相關性。語意內容與生成準確度進行線性迴歸分析所得的R2值分別為0.919與0.900,對應於未來1步與2步的語意狀態,兩者的p值均小於0.001。
他們也考慮了這樣一個假設,模型的表示只編碼了當前的語義狀態,而探測器只是從當前語義狀態預測未來的語意狀態。為了測試這個假設,他們計算了一個最優分類器,將目前程式中的ground truth面向方向映射到未來程式中的4個面向方向之一。
要注意的是,其中的5個操作中有3個保持了面向方向,並且下一個 token是均勻取樣的。因此他們預期,對於未來1步驟的情況,預測未來的語意狀態的最優分類器應該透過預測面向方向保持不變來達到60%的準確率。事實上,透過直接擬合測試集,他們發現從當前語意狀態預測未來語意狀態的上限分別為62.2%和40.7%(對應於未來1步和2步的情況)。相較之下,當給定偵測器正確預測目前狀態的條件下,偵測器在預測未來狀態方面的準確率分別為68.4%和61.0%。
這表明,探測器從模型狀態中提取未來語義狀態的能力不能僅僅透過從當前語義狀態的表示中推斷得出。因此,他們的結果表明,語言模型會學習去表示尚未生成的token的含義,這否定了語言模型無法學習意義的觀點(H2),也表明生成過程不僅僅基於純粹的表面統計(H1)。
接下來,研究者透過比較訓練後的語言模型產生的程式分佈與訓練集中的程式分佈,提供反駁H1的證據。如果H1成立,他們預期兩個分佈應該大致相等,因為語言模型只是在重複訓練集中文本的統計相關性。
圖6a顯示了LM產生的程式的平均長度隨時間的變化情況(實線藍色線條),與訓練集參考程式的平均長度(虛線紅色線條)進行對比。他們發現二者有統計上的顯著差異,顯示LM的輸出分佈確實與其訓練集的程序分佈不同。這與H1中提到的觀點(即LM只能重複其訓練資料中的統計相關性)相矛盾。
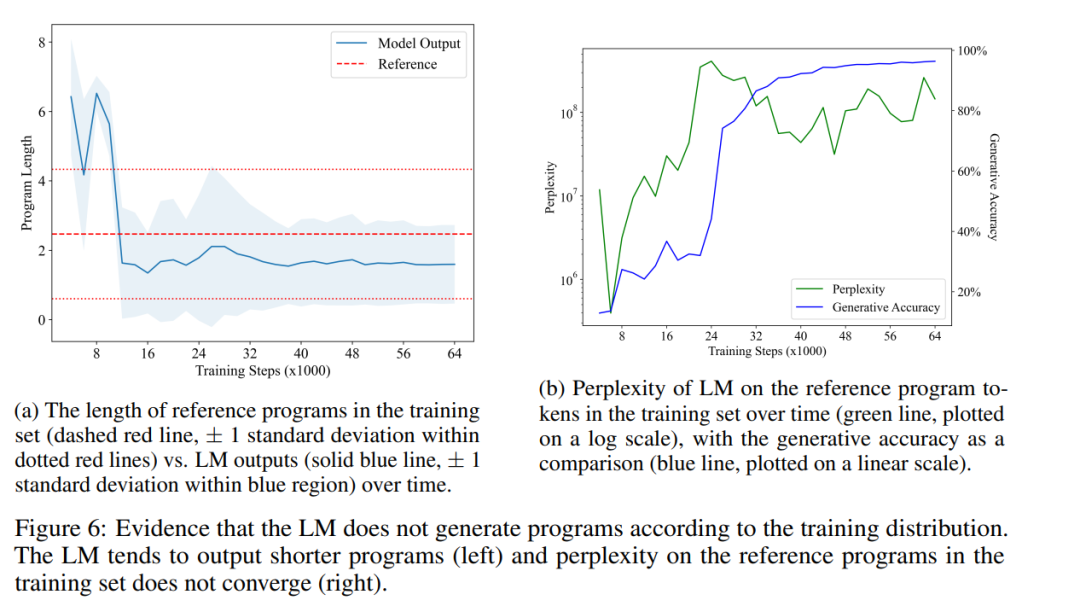
最後,他們也測量了LM在訓練集的程式上的困惑度隨時間的變化。圖6b展示了他們的結果。可以看到,LM從來沒有學會很好地擬合訓練集中程序的分佈,這進一步反駁了H1的觀點。這可能是因為在訓練集中隨機抽樣的程式包含了許多無操作指令,而LM更傾向於產生更簡潔的程式。有趣的是,困惑度的急劇增加——當LM超越了模仿階段——似乎導致了生成準確率(和語義內容)的提高。由於程序等價性問題與程序語義密切相關,LM能夠產生簡短且正確的程序表明它確實學到了語義的某個方面。
詳細內容請參考原論文。
以上是有證據了,MIT顯示:大型語言模型≠隨機鸚鵡,確實能學到語意的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















