

世界充滿了數據——由人和電腦生成的圖像、視訊、電子表格、音訊和文字充斥著互聯網,將我們淹沒在資訊的海洋中。
傳統上,人類分析數據以做出更明智的決策,並設法調整系統以控制數據模式的變化。然而,隨著傳入資訊量的增加,我們理解它的能力下降,給我們帶來了以下挑戰:
我們如何使用所有這些資料以自動而非手動的方式推導意義?
這正是機器學習發揮作用的地方。本文將介紹:
這些預測是由機器從一組稱為「訓練資料」的資料中學習模式做出的,它們可以推動進一步的技術發展,從而改善人們的生活。
機器學習是一個概念,它允許電腦自動從範例和經驗中學習,並在沒有明確程式設計的情況下模仿人類的決策。
機器學習是人工智慧的一個分支,使用演算法和統計技術從資料中學習並從中得出模式和隱藏的見解。
現在,讓我們更深入地探索機器學習的來龍去脈。
機器學習中有數以萬計的演算法,可以根據學習風格或所解決問題的性質進行分組。但每個機器學習演算法都包含以下關鍵元件:
以上是機器學習演算法的四個組成部分的詳細分類。
描述性:系統收集歷史數據,對其進行組織,然後以易於理解的方式呈現。
主要重點在於掌握企業中已經發生的事情,而不是從其發現中得出推論或預測。描述性分析使用簡單的數學和統計工具,例如算術、平均值和百分比,而不是預測性和規範性分析所需的複雜計算。
描述性分析主要針對歷史資料進行分析並推斷,而預測性分析則著重於預測和理解未來可能出現的情況。
透過查看歷史資料來分析過去的資料模式和趨勢可以預測未來可能發生的事情。
規範性的分析告訴我們如何行動,而描述性分析告訴我們過去發生了什麼事。預測性分析則告訴我們透過從過去學習,未來可能會發生什麼。但是,一旦我們對可能發生的事情有了洞察力,我們應該做什麼呢?
這就是規範分析。它幫助系統使用過去的知識對一個人可以採取的行動提出多項建議。規範性分析可以模擬場景並提供實現預期結果的途徑。
ML演算法的學習可以分為三個主要部分。
機器學習模型旨在從資料中學習模式並應用這些知識進行預測。問題是:模型如何進行預測?
這個過程非常基礎——從輸入資料(標記或未標記)中找到模式並應用它來得出結果。
機器學習模型旨在將自己所做的預測與基本事實進行比較。目標是了解它是否朝著正確的方向學習。這決定了模型的準確性,並暗示了我們如何改進模型的訓練。
該模型的最終目標是改進預測,這意味著減少已知結果與對應模型估計之間的差異。
此模型需要透過不斷更新權重來更好地適應訓練資料樣本。此演算法循環工作,評估和最佳化結果,更新權重,直到獲得關於模型準確性的最大值。
機器學習主要包括四種類型。
在監督學習中,顧名思義,機器在指導下學習。
這是透過向電腦提供一組標記資料來完成的,以使機器了解輸入的內容以及輸出應該是什麼。在這裡,人類充當嚮導,為模型提供標籤的訓練資料(輸入-輸出對),機器從中學習模式。
一旦從先前的資料集中學習了輸入和輸出之間的關係,機器就可以輕鬆地預測新資料的輸出值。
我們可以在哪裡使用監督學習?
答案是:在我們知道在輸入資料中查看什麼以及我們想要什麼作為輸出的情況下。
監督學習問題的主要類型包括迴歸和分類問題。
無監督學習的工作方式與監督學習的工作方式恰恰相反。
它使用未標記的數據——機器必須理解數據,找到隱藏的模式並做出相應的預測。
在這裡,機器在獨立地從資料中推導出隱藏模式後為我們提供新發現,而無需人工指定要尋找的內容。
無監督學習問題的主要類型包括聚類和關聯規則分析。
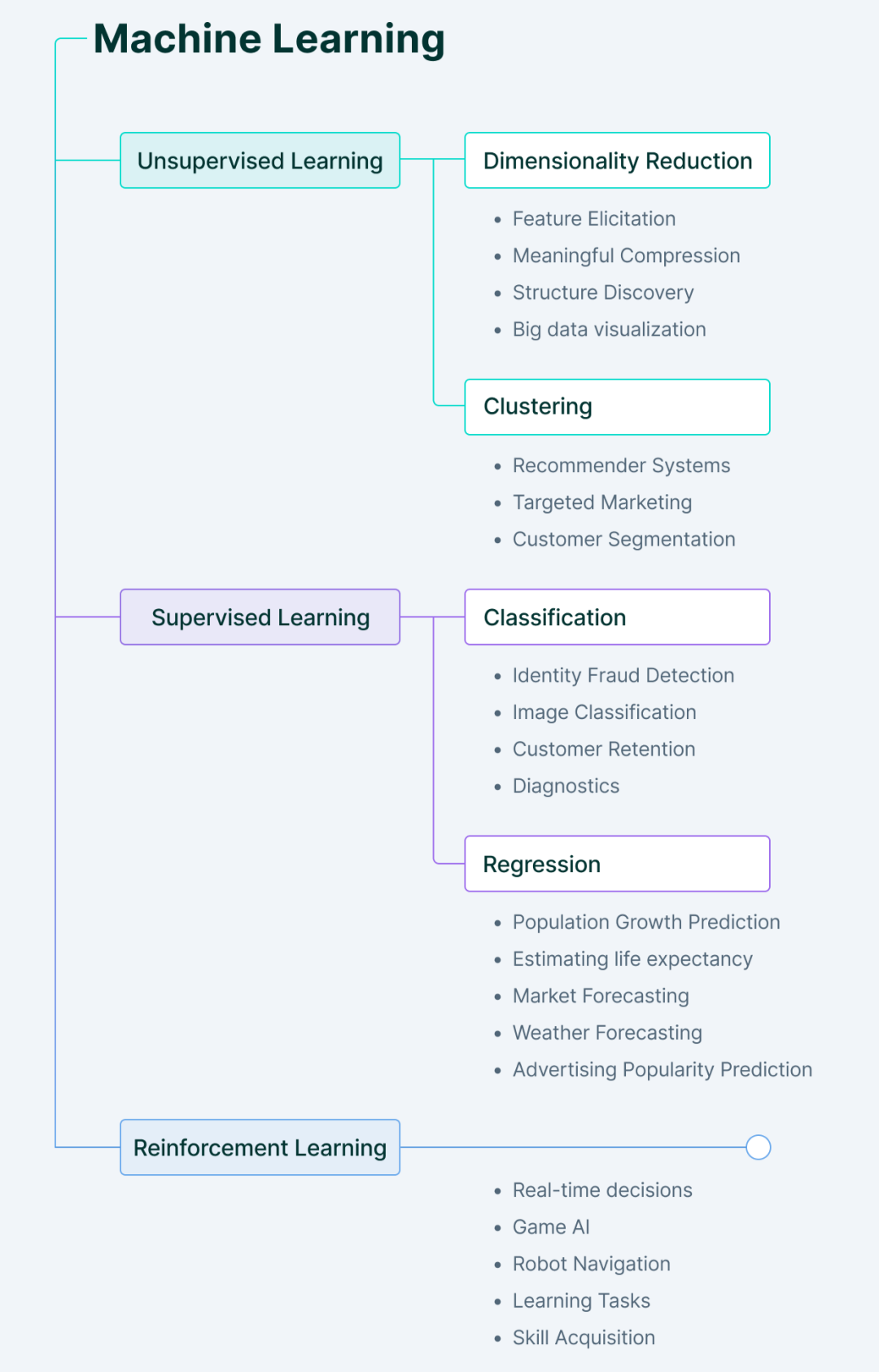
強化學習涉及一個代理,該代理透過執行操作來學習在環境中的行為。
根據這些行動的結果,它會提供回饋並調整其未來的路線-對於每一個好的動作,代理人都會得到正面的回饋,而對於每一個壞的動作,代理人都會得到負面的反饋或懲罰。
強化學習在沒有任何標記資料的情況下進行學習。由於沒有標記數據,代理只能根據自己的經驗進行學習。
半監督是監督和無監督學習之間的狀態。
它從每個學習中獲取積極的方面,即它使用較小的標記資料集來指導分類,並從較大的未標記資料集中執行無監督特徵提取。
使用半監督學習的主要優點是它能夠在沒有足夠的標記資料來訓練模型時解決問題,或者當資料根本無法標記時因為人類不知道要在其中尋找什麼。
如今,機器學習幾乎是所有科技公司的核心,包括Google或 Youtube 搜尋引擎等企業。
下面,匯總了一些您可能熟悉的機器學習在現實生活中的應用示例:
車輛在道路上會遇到各種各樣樣的情況。
為了讓自動駕駛汽車比人類表現更好,它們需要學習並適應不斷變化的路況和其他車輛的行為。
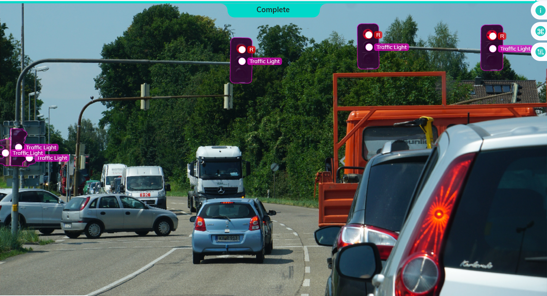
自動駕駛汽車從感測器和攝影機收集周圍環境的數據,然後對其進行解釋並做出相應的反應。它使用監督學習來識別周圍物體,使用無監督學習識別其他車輛的模式,並最終在強化演算法的幫助下採取相應的行動。
影像分析用於從影像中提取不同的資訊。
它在檢查製造缺陷、分析智慧城市的汽車交通或像Google鏡頭這樣的視覺搜尋引擎等領域中得到應用。
主要想法是使用深度學習技術從影像中提取特徵,然後將這些特徵應用於物件偵測。
如今,公司使用 AI 聊天機器人來提供客戶支援和銷售的情況非常普遍。 AI 聊天機器人透過提供 24/7 支援來幫助企業處理大量客戶查詢,從而降低支援成本並帶來額外收入和滿意的客戶。
AI 機器人技術使用自然語言處理 (NLP) 來處理文字、提取查詢關鍵字並做出相應回應。
事實是這樣的:醫學影像資料既是最豐富的資訊來源,也是最複雜的資訊來源之一。
手動分析數以千計的醫學影像是一項乏味的工作,並且浪費病理學家可以更有效地利用的寶貴時間。
但這不僅僅是節省時間——肉眼可能看不到偽影或結節等小特徵,從而導致疾病診斷延遲和錯誤預測。這就是為什麼使用涉及神經網路的深度學習技術(可用於從圖像中提取特徵)具有如此大的潛力。
隨著電子商務領域的擴張,我們可以觀察到線上交易數量的增加和可用支付方式的多樣化。不幸的是,有些人利用了這種情況。當今世界的詐欺者非常熟練,可以非常迅速地採用新技術。
這就是為什麼我們需要一個能夠分析資料模式、做出準確預測並回應線上網路安全威脅(如虛假登入嘗試或網路釣魚攻擊)的系統。
例如,根據您過去購買的地點或您在線上的時間,防詐騙系統可以發現購買是否合法。同樣,他們可以檢測是否有人試圖在網路或電話中冒充您。
推薦演算法的這種相關性是基於對歷史資料的研究,並取決於幾個因素,包括使用者偏好和興趣。
京東或抖音等公司使用推薦系統為使用者/買家策劃和展示相關內容或產品。
在大多數情況下,任何機器學習演算法表現不佳的原因都是由於欠擬合和過擬合。
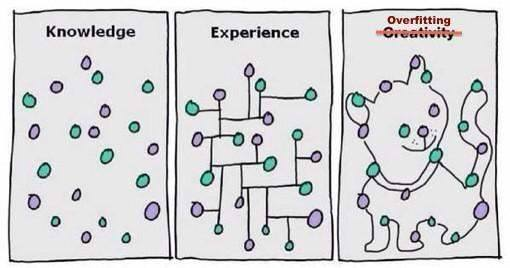
讓我們在訓練機器學習模型的背景下分解這些術語。
由於該模型的靈活性很小,因此無法預測新的資料點。換句話說,它過於關注所給的例子,無法看到更大的圖像。
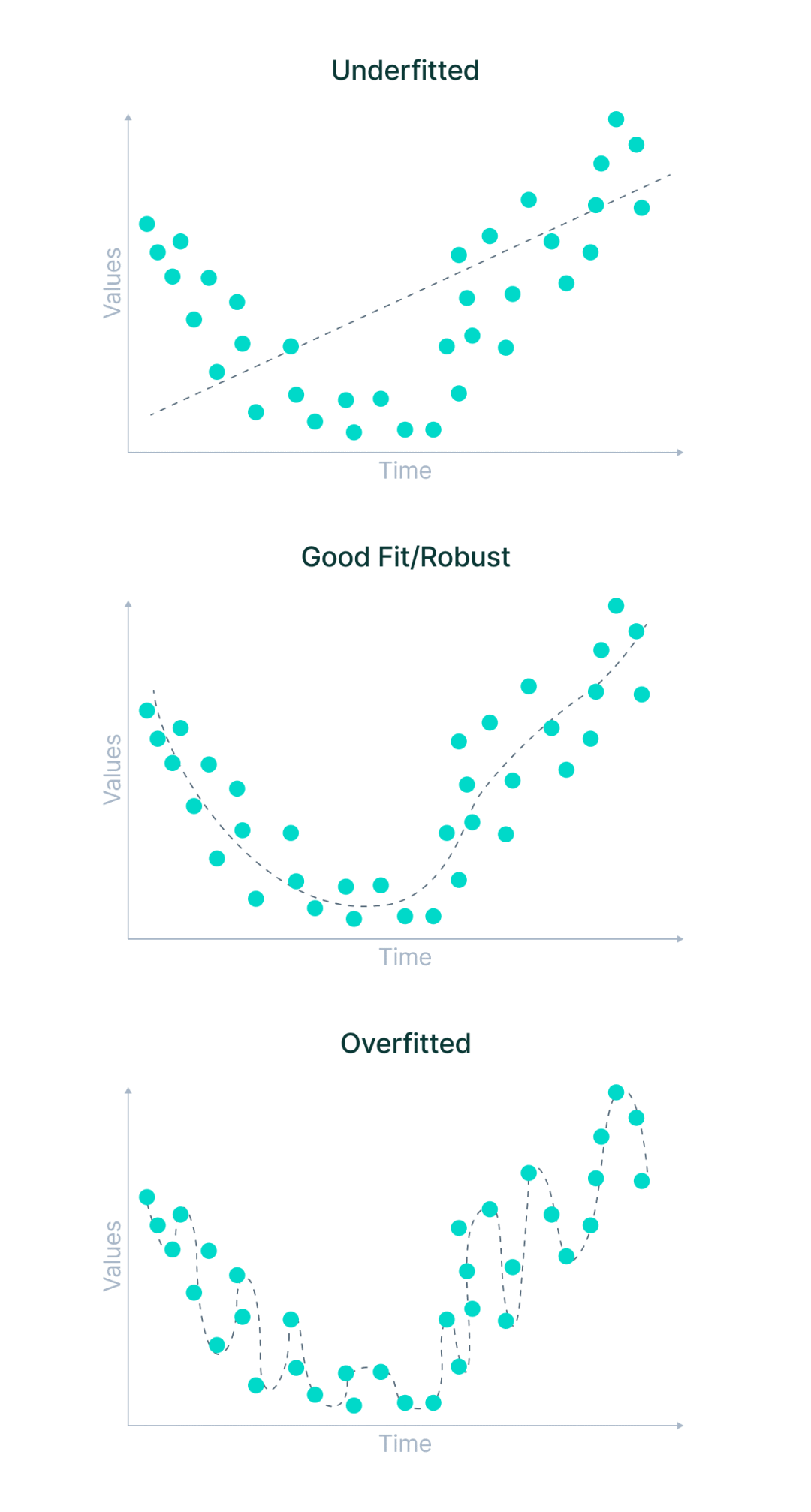
欠擬合和過擬合的原因是什麼?
更一般的情況包括用於訓練的資料不乾淨並且包含大量雜訊或垃圾值,或資料的大小太小的情況。但是,還有一些更具體的原因。
讓我們來看看那些。
欠擬合的發生可能是因為:
在以下情況下可能會發生過度擬合:

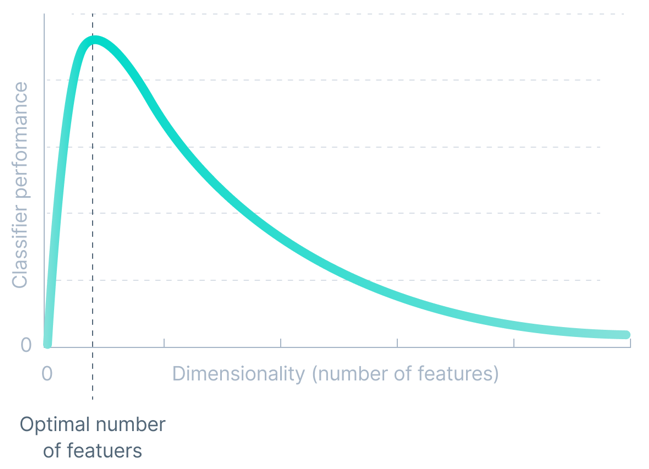
#任何機器學習模型的準確度都與資料集的維度成正比。但它只適用於特定的閾值。
資料集的維度是指資料集中存在的屬性/特徵的數量。以指數方式增加維度會導致添加非必需屬性,從而混淆模型,從而降低機器學習模型的準確性。
我們將這些與訓練機器學習模型相關的困難稱為「維度災難」。
機器學習演算法對低品質的訓練資料很敏感。
由於資料不正確或缺失值導致資料中出現噪聲,資料品質可能會受到影響。即使訓練資料中相對較小的錯誤也會導致系統輸出出現大規模錯誤。
當演算法表現不佳時,通常是由於資料品質問題,例如數量/傾斜/雜訊資料不足或描述資料的特徵不足。
因此,在訓練機器學習模型之前,往往需要進行資料清洗以獲得高品質的資料。
以上是一文讀懂什麼是機器學習的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















