

2017年,Google團隊在論文「Attention Is All You Need」提出了開創性的NLP架構Transformer,自此一路開掛。
多年來,這項架構風靡微軟、Google、Meta等大型科技公司。就連橫掃世界的ChatGPT,也是基於Transformer開發的。
而就在今天,Transformer在GitHub上星標破10萬大關!
Hugging Face,最初只是一個聊天機器人程序,因其作為Transformer模型的中心而聲名鵲起,一舉成為聞名世界的開源社群。
為了慶祝這個里程碑,Hugging Face也總結了100個基於Transformer架構搭建的專案。
2017年6月,Google發布「Attention Is All You Need」論文時,或許誰也沒想到這個深度學習架構Transformer能夠帶來多少驚喜。
從誕生至今,Transformer已成為AI領域的基石王者。 19年,谷歌也專門為其申請了專利。

隨著Transformer在NLP領域佔據了主流地位,也開始了向其他領域的跨界,越來越多的工作也開始嘗試將其引到CV領域。
看到Transformer突破這一里程碑,許多網友甚是激動。
「我一直是許多受歡迎的開源專案的貢獻者,但看到Transformer在GitHub上達到10萬顆星,還是很特別的!」
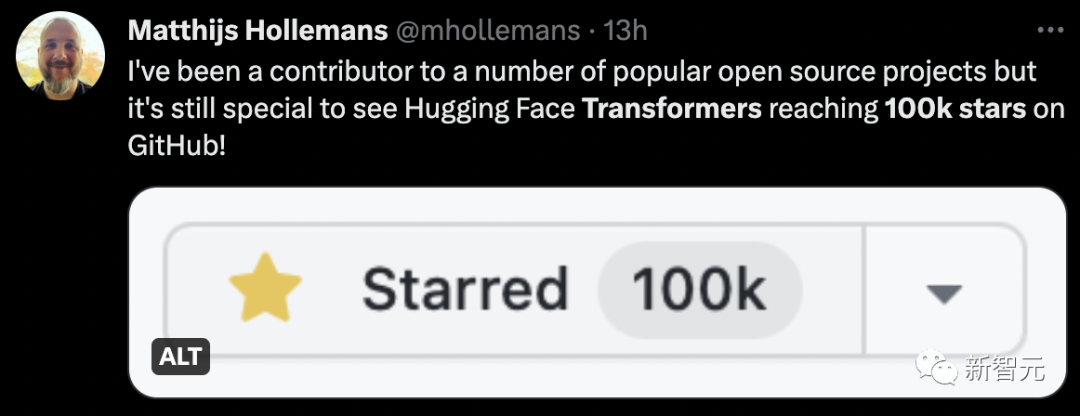
#前段時間Auto-GPT的GitHub星量超過了pytorch引起了很大的轟動。
網友不禁好奇Auto-GPT和Transformer比較呢?

其實,Auto-GPT遠遠超過Transformer,已經有13萬顆了。
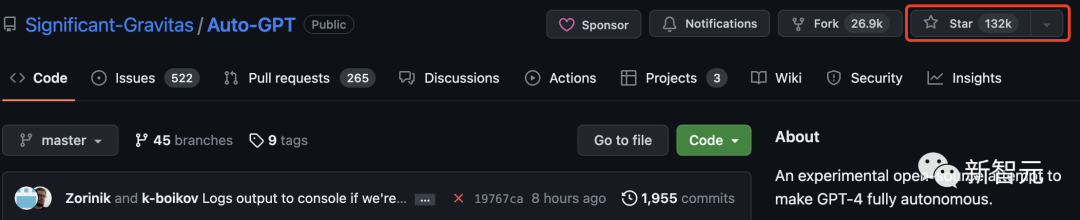
目前,Tensorflow有17萬多星。可見,Transformer是繼這兩個專案之後,第三個星標破10萬的機器學習庫。
還有網友回憶起了最初使用Transformers函式庫時,那時的名字叫「pytorch-pretrained-BERT」。
Transformers不僅是一個使用預訓練模型的工具包,它還是一個圍繞Transformers和Hugging Face Hub構建的項目社區。
在下面列表中,Hugging Face總結了100個基於Transformer搭建的讓人驚嘆的新穎項目。

以下,我們節錄了前50個項目來介紹:
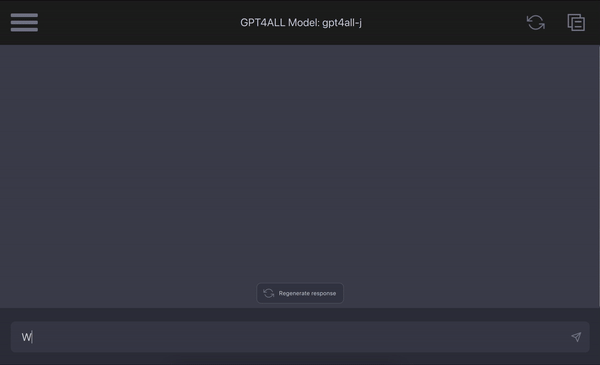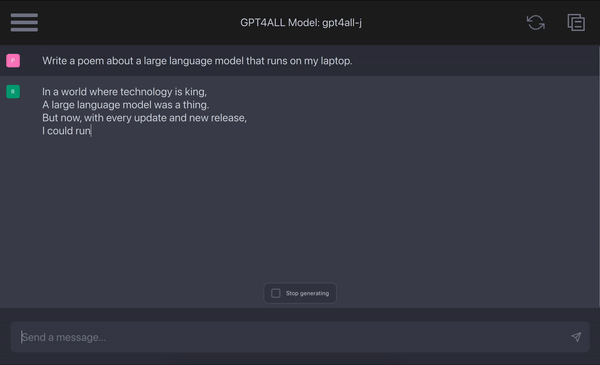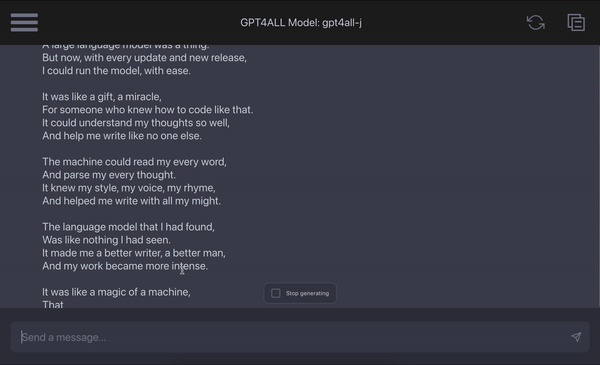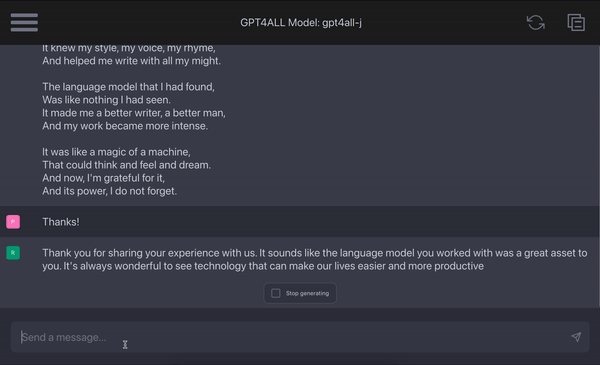
#gpt4all是一個開源聊天機器人生態系統。它是在大量乾淨的助手資料集合上訓練出來的,包括程式碼、故事和對話。它提供開源的大型語言模型,如LLaMA和GPT-J,以助理的方式進行訓練。
關鍵字: 開源,LLaMa,GPT-J,指令,助手
這個儲存庫包含建立推薦系統的範例和最佳實踐,以Jupiter筆記本形式提供。它涵蓋了建立有效推薦系統所需的幾個方面: 資料準備、建模、評估、模型選擇和最佳化,以及操作化。
關鍵字:推薦系統,AzureML
lama-cleaner基於Stable Diffusion技術的映像修復工具。可以從圖片中擦出任何你不想要的物體、缺陷、甚至是人,並替換圖片上的任何東西。
關鍵字:修補,SD,Stable Diffusion
FLAIR是一個強大的PyTorch自然語言處理框架,可以轉換幾個重要的任務:NER、情感分析、詞性標註、文本和對偶嵌入等。
關鍵字:NLP,文字嵌入,文件嵌入,生物醫學,NER,PoS,情緒分析

MindsDB是一個低程式碼的機器學習平台。它將幾個ML框架作為“AI表”自動集成到資料棧中,以簡化AI在應用程式中的集成,讓所有技能水平的開發人員都能使用。
關鍵字:資料庫,低程式碼,AI表
#langchainLangchain旨在協助開發相容LLM 和其他知識來源的應用程式。該庫允許對應用程式進行鍊式調用,在許多工具中創建一個序列。
關鍵字:LLM,大型語言模型,智能體,鏈
ParlAIParlAI是一個用來分享、訓練和測試對話模型的python框架,從開放領域的聊天,到任務導向的對話,再到視覺化問題回答。它在同一個API下提供了100多個資料集,許多預訓練模型,一組智能體,並有幾個整合。
關鍵字:對話,聊天機器人,VQA,資料集,智能體
sentence-transformers這個框架提供了一種簡單的方法來計算句子、段落和圖像的密集向量表示。這些模型基於BERT/RoBERTa/XLM-RoBERTa等Transformer為基礎的網絡,並在各種任務中取得SOTA。文字嵌入向量空間中,這樣類似的文字就很接近,可以透過餘弦相似度高效找到。
關鍵字:密集向量表示,文字嵌入,句子嵌入
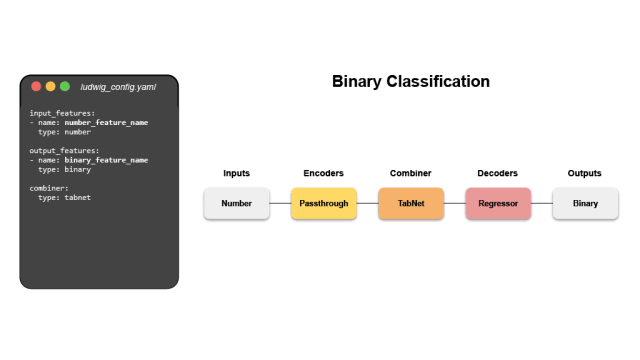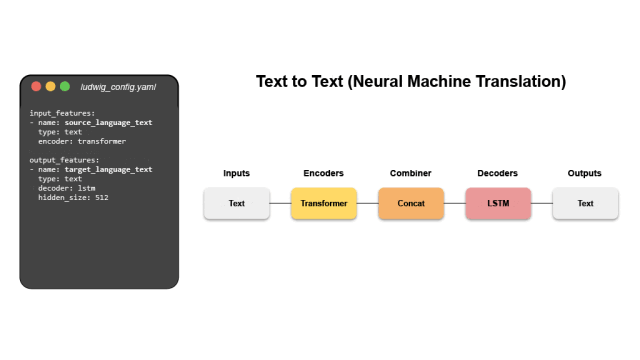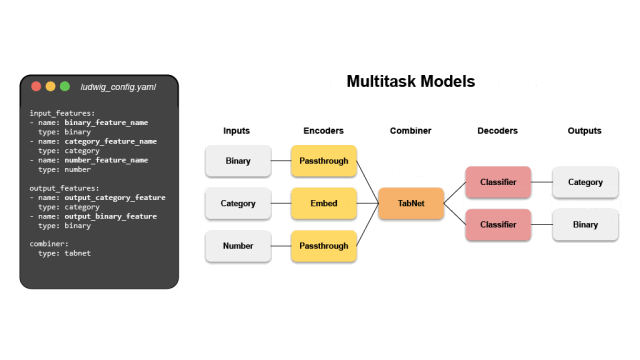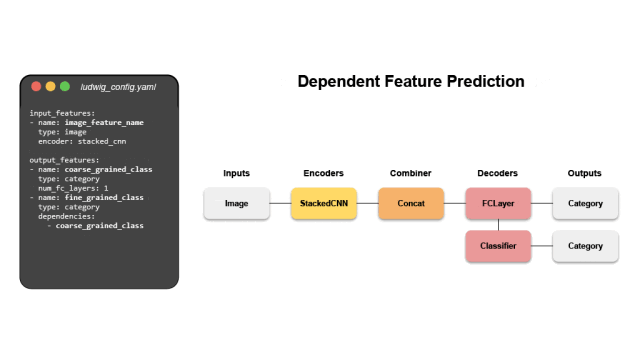
#ludwigLudwig是一個宣告式的機器學習框架,使用一個簡單而靈活的數據驅動的配置系統,可以輕鬆定義機器學習pipelines。 Ludwig針對的是各類AI任,提供了一個資料驅動的設定係統,訓練、預測和評估腳本,以及一個程式設計的API。
關鍵字:聲明式,資料驅動,ML 框架
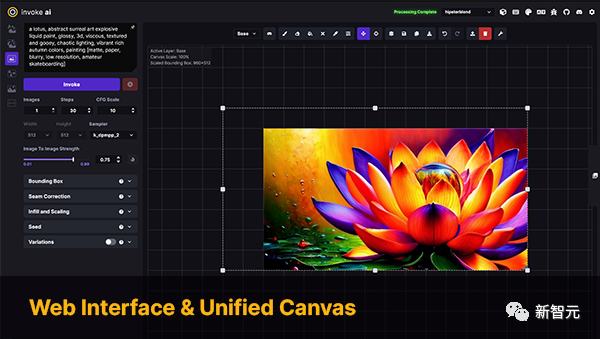
InvokeAI是Stable Diffusion模型的引擎,面向專業人士、藝術家和愛好者。它透過CLI以及WebUI來利用最新的AI驅動技術。
關鍵詞:Stable Diffusion,WebUI,CLI
PaddleNLP是一個易於使用且功能強大的NLP庫,特別是針對中文語言。它支援多個預訓練的模型動物園,並支援從研究到工業應用的廣泛的NLP任務。
關鍵字:自然語言處理,漢語,研究,工業
史丹佛大學NLP小組的官方Python NLP庫。它支援在60多種語言上運行各種精確的自然語言處理工具,並支援從Python存取Java Stanford CoreNLP軟體。
關鍵字:NLP,多語言,CoreNLP
DeepPavlov是一個開源的對話式人工智慧庫。它被設計用於開發可生產的聊天機器人,和複雜的對話系統,以及在NLP領域的研究,特別是對話系統。
關鍵字:對話,聊天機器人
Alpaca-lora包含了使用低秩適應( LoRA)重現史丹佛大學Alpaca結果的程式碼。此資源庫提供訓練(微調)以及產生腳本。
關鍵字:LoRA,參數高效微調
一個Imagen的開源實現,Google的封閉源文本到圖像的神經網路擊敗了DALL-E2。 imagen-pytorch是用於文字到圖像合成的新SOTA。
關鍵字:Imagen,文生圖
#adapter-transformers是Transformers 庫的擴展,透過納入AdapterHub,將適配器整合到最先進的語言模型中,AdapterHub是一個預先訓練的適配器模組的中央儲存庫。它是Transformers的直接替代品,定期更新以保持與Transformers發展同步。
關鍵字:適配器,LoRA,參數高效微調,Hub
NVIDIA NeMo是為從事自動語音由識別(ASR)、文本-語音合成(TTS)、大語言模型和自然語言處理的研究人員所建構的會話AI工具包。 NeMo的主要目標是幫助來自工業界和學術界的研究人員重新利用先前的工作(程式碼和預先訓練的模型),並使其更容易創建新的專案。
關鍵字:對話,ASR,TTS,LLM,NLP
Runhouse允許用Python將程式碼和資料發送到任何電腦或資料下層,並繼續從現有程式碼和環境正常地與它們進行互動。 Runhouse開發者提到:
可以將它看作 Python 解釋器的擴充包,它可以繞道遠端機器或操作遠端資料。
關鍵字: MLOps,基礎設施,資料存儲,建模
MONAI是PyTorch生態系統的一部分,是基於PyTorch的開源框架,用於醫療影像領域的深度學習。它的目標是:
- 發展一個學術、工業和臨床研究人員的共同基礎上的合作社區;
- 為醫療影像創建SOTA、端到端訓練的工作流程;
- 為深度學習模型的建立和評估提供了優化和標準化的方法。
關鍵字:醫療影像,訓練,評估
Simple Transformers讓您快速訓練和評估Transformer模型。初始化、訓練和評估模型只需要3行程式碼。它支援各種各樣的 NLP 任務。
關鍵字:框架,簡單性,NLP
JARVIS是一個將GPT-4等在內的LLM與開源機器學習社群其他模型合併的系統,利用多達60個下游模型來執行LLM 確定的任務。
關鍵字:LLM,智能體,HF Hub
transformers.js是一個JavaScript函式庫,目標是直接在瀏覽器中從transformers執行模型。
關鍵字:Transformers,JavaScript,瀏覽器
Bumblebee在Axon之上提供了預先訓練的神經網路模型,Axon是用於Elixir語言的神經網路函式庫。它包括與模型的集成,允許任何人下載和執行機器學習任務,只需要幾行程式碼。
關鍵字:Elixir,Axon
Argilla是一個提供高級NLP標籤、監控和工作區的開源平台。它與許多開源生態系統相容,例如Hugging Face、Stanza、FLAIR等。
關鍵字:NLP,標籤,監控,工作區
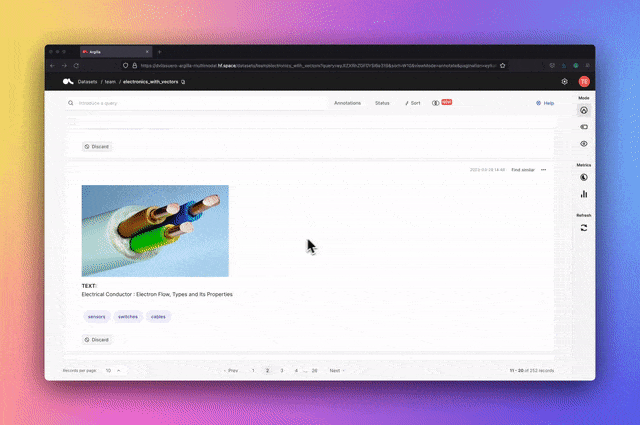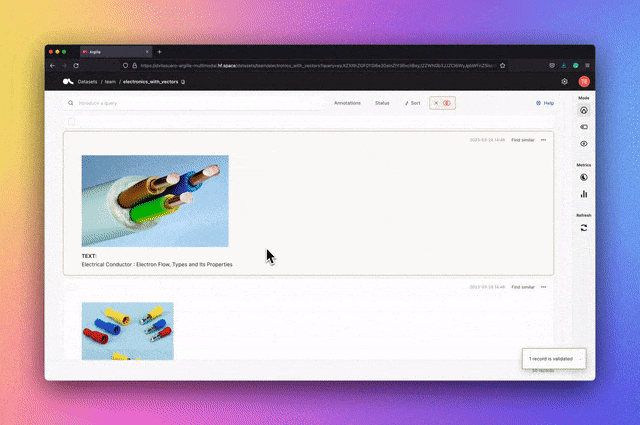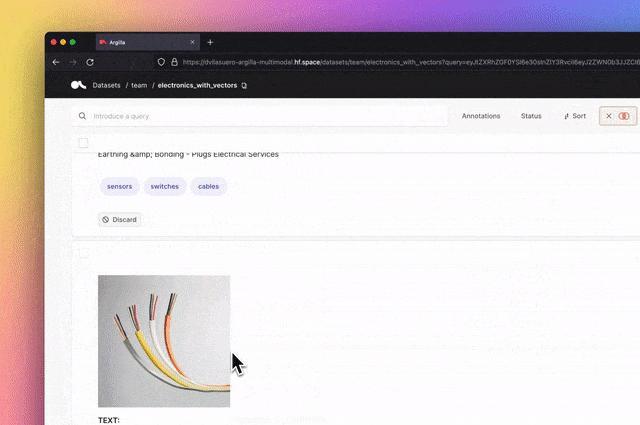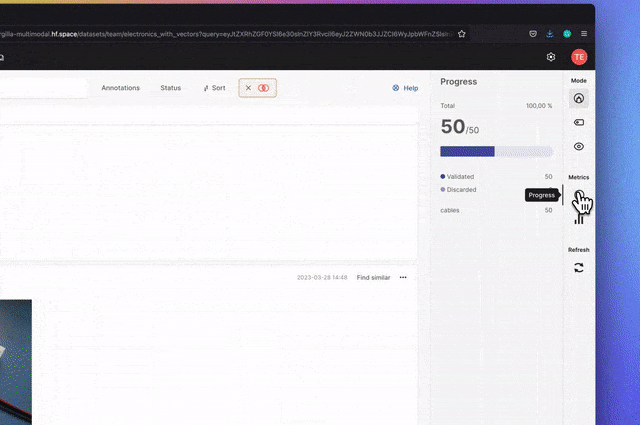
Haystack是一個開源的NLP框架,可以使用Transformer模型和LLM與資料互動。它為快速建立複雜的決策、問題回答、語義搜尋、文字生成應用程式等提供了可用於生產的工具。
關鍵字:NLP,Framework,LLM

SpaCy是一個用於Python和Cython中高階自然語言處理的函式庫。它建立在最新的研究基礎上,從一開始就被設計用於實際產品。它透過其第三方軟體包spacy-transformers為Transformers模型提供支援。
關鍵字:NLP,架構

SpeechBrain是一個基於PyTorch的開源、一體化的會話AI工具包。我們的目標是創建一個單一的、靈活的、用戶友好的工具包,可以用來輕鬆開發最先進的語音技術,包括語音識別、演講者識別、語音增強、語音分離、語言識別、多麥克風信號處理等系統。
關鍵字:對話,演講
Skorch是包裝PyTorch的具有scikit-learn相容性的神經網路庫。它支援Transformers中的模型,以及來自標記器的標記器。
關鍵字:Scikit-Learning,PyTorch
##BertViz是一個互動式工具,用於在諸如BERT、GPT2或T5之類的Transformer語言模型中可視化注意力。它可以透過支援大多數Huggingface模型的簡單Python API在Jupiter或Colab筆記本中運行。
關鍵字:視覺化,Transformers

#mesh-transformer-jax是一個俳句函式庫,使用JAX中的xmap/pjit運算子實作Transformers模型並行性。
這個函式庫被設計成在TPUv3上可擴展到大約40B的參數。它是用來訓練GPT-J模型的函式庫。
關鍵字:俳句,模型並行,LLM,TPUdeepchem
OpenNRE一種用於神經關係提取的開源軟體包(NRE)。它的目標用戶範圍很廣,從新手、到開發人員、研究人員或學生。
關鍵字:神經關係抽取,框架
pycorrector一種中文文字修正工具。此方法利用語言模型來偵測錯誤、拼音特徵和形狀特徵來修正漢語文字錯誤。可用於漢語拼音和筆畫輸入法。
關鍵字: 中文,糾錯工具,語言模型,Pinyin
這個python函式庫可以幫助你為機器學習專案增強nlp。它是一個輕量級的庫,具有生成合成資料以提高模型性能的功能,支援音訊和文本,並與幾個生態系統(scikit-learn、pytorch、tensorflow)相容。
關鍵字:資料增強,合成資料生成,音頻,自然語言處理
dream-texturesdream- textures是一個旨在為Blender帶來穩定擴散支援的函式庫。它支援多種用例,例如圖像生成、紋理投影、內畫/外畫、 ControlNet和升級。
關鍵字: Stable-Diffusion,Blender

關鍵字:微服務,建模,語言包裝
該程式庫包括最佳化的深度學習模型和一組演示,以加快高效能深度學習推理應用程式的開發。使用這些免費的預訓練模型,而不是訓練自己的模型來加速開發和生產部署流程。 關鍵字:最佳化模型,示範 ML-Stable-Diffusion是蘋果在蘋果晶片設備上為Core ML帶來Stable Diffusion支援的一個倉庫。它支援託管在Hugging Face Hub上的穩定擴散檢查點。 關鍵字:Stable Diffusion,蘋果晶片,Core MLopen_model_zoo
ml-stable-diffusion
Stable-Dreamfusion是文字到3D模型Dreamfusion的pytorch實現,由Stable Diffusion文字到2D模型提供動力。
關鍵字:文字到3D,Stable Diffusion

Txtai是一個開源平台,支援語義搜尋和語言模型驅動的工作流程。 Txtai建構了嵌入式資料庫,它是向量索引和關聯式資料庫的結合,支援SQL近鄰搜尋。語義工作流程將語言模型連接到統一的應用程式。
關鍵字:語意搜索,LLM

Deep Java Library (DJL)是一個用於深度學習的開源、進階、引擎無關的Java框架,易於開發人員使用。 DJL像其他常規Java函式庫一樣提供了本機Java開發經驗和函數。 DJL為HuggingFace Tokenizer提供了Java綁定,並為HuggingFace模型在Java中部署提供了簡單的轉換工具包。
關鍵字:Java,架構

該專案提供了一個統一的框架,以測試生成語言模型在大量不同的評估任務。它支援200多項任務,並支援不同的生態系統:HF Transformers,GPT-NeoX,DeepSpeed,以及OpenAI API。
關鍵字:LLM,評估,少樣本
這個資源庫記錄了EleutherAI用於在GPU上訓練大規模語言模型的函式庫。該框架以英偉達的Megatron語言模型為基礎,並以DeepSpeed的技術和一些新的最佳化來增強。它的重點是訓練數十億參數的模型。
關鍵字:訓練,LLM,Megatron,DeepSpeed
Muzic是一個關於人工智慧音樂的研究項目,它能夠透過深度學習和人工智慧來理解和生成音樂。 Muzic是由微軟亞洲研究院的研究人員創建的。
關鍵字:音樂理解,音樂生成

DALL · E Flow是一個互動式工作流程,用於從文字提示字元產生高清圖像。它利用DALL · E-Mega、GLID-3 XL和Stable Diffusion產生候選影像,然後呼叫CLIP-as-service對候選影像進行提示排序。首選的候選者被饋送到GLID-3 XL進行擴散,這通常會豐富紋理和背景。最後,透過SwinIR將候選項擴展到1024x1024。
關鍵字:高清度映像生成,Stable Diffusion,DALL-E Mega,GLID-3 XL,CLIP,SwinIR
LightSeq是在CUDA中實作的用於序列處理和產生的高效能訓練和推理函式庫。它能夠有效率地計算現代NLP和CV模型,如BERT,GPT,Transformer等。因此,它對於機器翻譯、文字生成、圖像分類和其他與序列相關的任務非常有用。
關鍵字:訓練,推理,序列處理,序列產生

該專案的目標是建立一個基於學習的系統,該系統採用數學公式的圖像,並傳回對應的LaTeX程式碼。
關鍵字:OCR,LaTeX,數學公式
OpenCLIP是OpenAI的CLIP的開源實作。
這個資源庫的目標是使具有對比性的圖像-文字監督的訓練模型成為可能,並研究它們的屬性,如對分佈轉移的穩健性。專案的出發點是CLIP的實現,當在相同的資料集上訓練時,與原始CLIP模型的準確性相符。
具體來說,以OpenAI的1500萬圖像子集YFCC為程式碼基礎訓練的ResNet-50模型在ImageNet上達到32.7%的最高準確率。
關鍵字:CLIP,開源,對比,圖像文字

一個playground產生圖像從任何文字提示使用Stable Diffusion和Dall-E mini。
關鍵字:WebUI,Stable Diffusion,Dall-E mini
FedML是一個聯邦學習和分析庫,能夠在任何地方、任何規模的分散資料上進行安全和協作的機器學習。
關鍵字:聯邦學習,分析,協作機器學習,分散#
以上是星標破10萬! Auto-GPT之後,Transformer越新里程碑的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















