

分類模型可分為兩大類:生成式模型與辨別式模型。本文解釋了這兩種模型類型之間的區別,並討論了每種方法的優缺點。
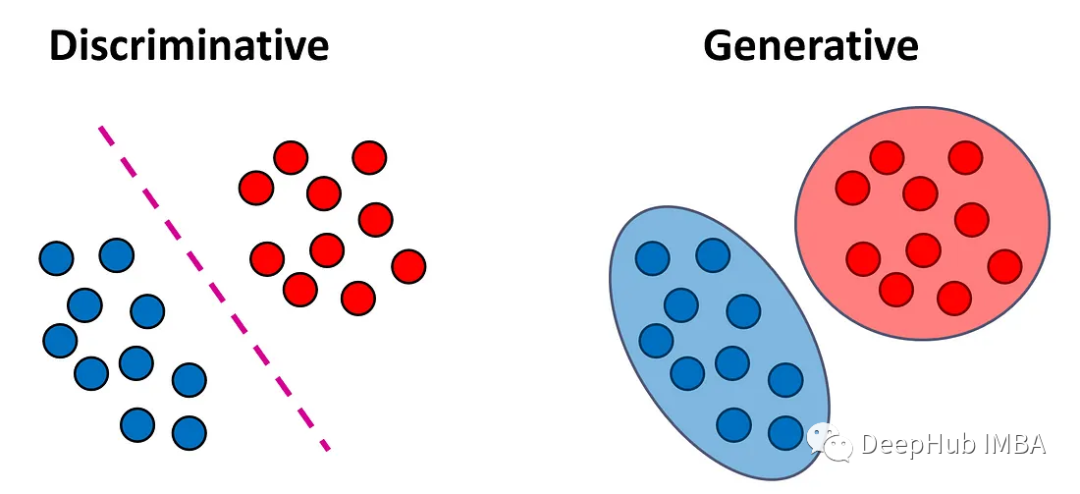
辨別式模型是一種能夠學習輸入資料和輸出標籤之間關係的模型,它透過學習輸入資料的特徵來預測輸出標籤。在分類問題中,我們的目標是將每個輸入向量x分配給標籤y。判別模型試圖直接學習將輸入向量對應到標籤的函數f(x)。這些模型可以進一步分為兩個子類型:
分類器試圖找到f(x)而不使用任何機率分佈。這些分類器直接為每個樣本輸出一個標籤,而不提供類別的機率估計。這些分類器通常稱為確定性分類器或無分佈分類器。此類分類器的例子包括k近鄰、決策樹和SVM。
分類器首先從訓練資料中學習後驗類機率P(y = k|x),並根據這些機率將一個新樣本x分配給其中一個類別(通常是後驗機率最高的類)。
這些分類器通常被稱為機率分類器。這種分類器的例子包括邏輯迴歸和在輸出層中使用sigmoid或softmax函數的神經網路。
在所有條件相同的情況下,我一般都使用機率分類器而不是確定性分類器,因為這個分類器提供了關於將樣本分配給特定類別的置信度的額外資訊。
一般的判別式模型包括:
生成式模型在估計類別機率之前學習輸入的分佈。生成式模型是一種能夠學習資料生成過程的模型,它可以學習輸入資料的機率分佈,並產生新的資料樣本。
更具體地說生成模型首先從訓練資料估計類別的條件密度P(x|y = k)和先驗類別機率P(y = k)。他們試圖了解每個分類的數據是如何產生的。
接著利用貝葉斯定理估計後驗類別機率:
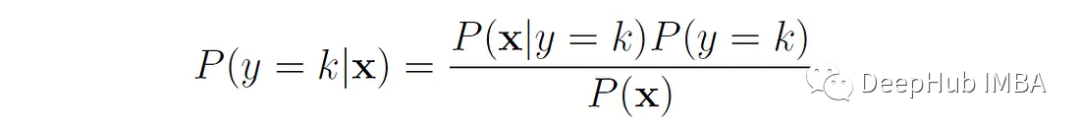
#貝葉斯規則的分母可以用分子中出現的變數來表示:
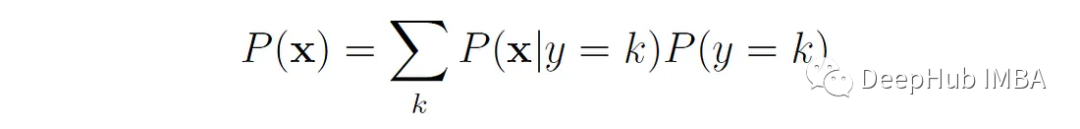
生成式模型也可以先學習輸入和標籤P(x, y)的聯合分佈,然後將其歸一化以獲得後驗機率P(y = k |x)。一旦我們有了後驗機率,我們就可以用它們將一個新的樣本x分配給其中一個類別(通常是後驗機率最高的類別)。
例如,考慮一個圖像分類任務中,我們需要區分圖像狗(y = 1)和貓(y = 0)。生成模型首先會建立一個狗 P(x|y = 1) 的模型,以及貓 P(x|y = 0) 的模型。然後在對新圖像進行分類時,它會將其與兩個模型進行匹配,以查看新圖像看起來更像狗還是更像貓。
為生成模型允許我們從學習的輸入分佈P(x|y)中產生新的樣本。所以我們稱之為生成式模型。最簡單的例子是,對於上面的模型我們可以從P(x|y = 1)中取樣來產生新的狗的圖像。
一般的生成模型包括
深度生成模型(DGMs)結合了生成模型和深度神經網路:
訓練複雜度高,因為生成式模型要建立輸入資料和輸出資料之間的聯合分佈,需要大量的運算和儲存資源。對資料分佈的假設比較強,因為生成式模型要建立輸入資料和輸出資料之間的聯合分佈,需要對資料的分佈進行假設和建模,因此對於複雜的資料分佈,生成式模型在小規模的計算資源上並不適用。
生成模型可以處理多模態數據,因為生成式模型可以建立輸入資料和輸出資料之間的多元聯合分佈,從而能夠處理多模態資料。
辨別式模型:
如果不對資料做一些假設,生成式模型學習輸入分佈P(x|y)在計算上是困難的,例如,如果x由m個二進位特徵組成,為了對P(x|y)建模,我們需要從每個類別的資料中估計2個ᵐ參數(這些參數表示m個特徵的2個ᵐ組合中的每一個的條件機率)。而Naïve Bayes等模型則對特徵進行條件獨立性假設,以減少需要學習的參數數量,因此訓練複雜度低。但是這樣的假設通常會導致生成模型比判別模型表現得更差。
對於複雜的資料分佈和高維資料具有很好的表現,因為辨別式模型可以靈活地對輸入資料和輸出資料之間的映射關係進行建模。
辨別式模型對雜訊資料和缺失資料敏感,因為模型只考慮輸入資料和輸出資料之間的映射關係,不利用輸入資料中的資訊填補缺失值和移除雜訊。
生成式模型和辨別式模型都是機器學習中重要的模型類型,它們各自具有優點和適用場景。在實際應用中,需要根據特定任務的需求選擇合適的模型,並結合混合模型和其他技術手段來提高模型的效能和效果。
以上是生成式模型與辨別式模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















