

作者:校婭沈元朱迪等
點評搜尋是大眾點評App的核心入口之一,用戶透過搜尋來滿足不同場景下對生活服務類商家的找店需求。搜尋的長期目標是持續優化搜尋體驗,提升用戶的搜尋滿意度,這需要我們理解用戶搜尋意圖,準確衡量搜尋字詞與商家之間的相關程度,盡可能展示相關商家並將更相關的商家排序靠前。因此,搜尋詞與商家的相關性計算是點評搜尋的重要環節。
大眾點評搜尋場景面臨的相關性問題複雜多樣,使用者的搜尋字詞比較多樣,例如搜尋商家名稱、菜色、地址、類別以及它們之間的各種複雜組合,同時商家也有多種類型的信息,包括商家名稱、地址資訊、團單資訊、菜餚資訊以及其他各種設施和標籤資訊等,導致Query與商家的配對模式異常複雜,容易滋生各種各樣的相關性問題。具體來說,可以分為以下幾種類型:
(a) 文字錯誤匹配範例
(b) 語意偏移範例
圖1 點評搜尋相關性問題範例
基於字面匹配的相關性方法無法有效應對上述問題,為了解決搜尋清單中的各類別不符合使用者意圖的不相關問題,需要更準確地刻畫搜尋字詞與商家的深度語意相關性。本文在基於美團海量業務語料訓練的MT-BERT預訓練模型的基礎上,在大眾點評搜尋場景下優化Query與商家(POI,對應通用搜尋引擎中的Doc)的深度語義相關性模型,並將Query與POI的相關性資訊應用在搜尋連結各環節。
本文將從搜尋相關性現有技術綜述、點評搜尋相關性計算方案、應用實戰、總結與展望四個面向對點評搜尋相關性技術進行介紹。其中點評搜尋相關性計算章節將介紹我們如何解決商家輸入資訊建構、讓模型適配點評搜尋相關性計算及模型上線的效能最佳化等三項主要挑戰,應用實戰章節將介紹點評搜尋相關性模型的離線及線上效果。
搜尋相關性旨在計算Query和返回Doc之間的相關程度,也就是判斷Doc中的內容是否滿足使用者Query的需求,對應NLP中的語意配對任務(Semantic Matching)。在大眾點評的搜尋場景下,搜尋相關性就是計算使用者Query和商家POI之間的相關程度。
文字匹配方法:早期的文本匹配任務僅考慮了Query與Doc的字面匹配程度,透過TF-IDF、BM25等基於Term的匹配特徵來計算相關性。字面匹配相關性線上計算效率較高,但基於Term的關鍵字匹配泛化性能較差,缺少語義和詞序信息,且無法處理一詞多義或多詞一義的問題,因此漏匹配和誤匹配現象嚴重。
傳統語義匹配模型:為彌補字面匹配的缺陷,語義匹配模型被提出以更好地理解Query與Doc的語義相關性。傳統的語意配對模型主要包括基於隱式空間的匹配:將Query和Doc都映射到同一個空間的向量,再用向量距離或相似度作為匹配分,如Partial Least Square(PLS# )[1];以及基於翻譯模型的匹配:將Doc映射到Query空間後進行匹配或計算Doc翻譯成Query的機率[2]。
隨著深度學習和預訓練模型的發展,深度語意配對模型也被業界廣泛應用。深度語意配對模型從實作方法上分為基於表示法(Representation-based)的方法及基於交互作用(Interaction-based)的方法。預訓練模型作為自然語言處理領域的有效方法,也被廣泛使用在語意配對任務中。
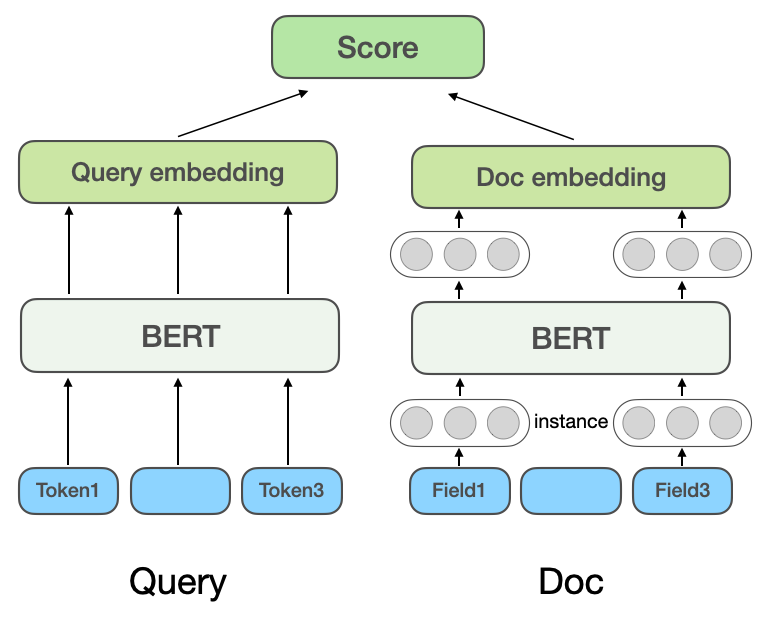
(a) 基於表示的多域相關性模型
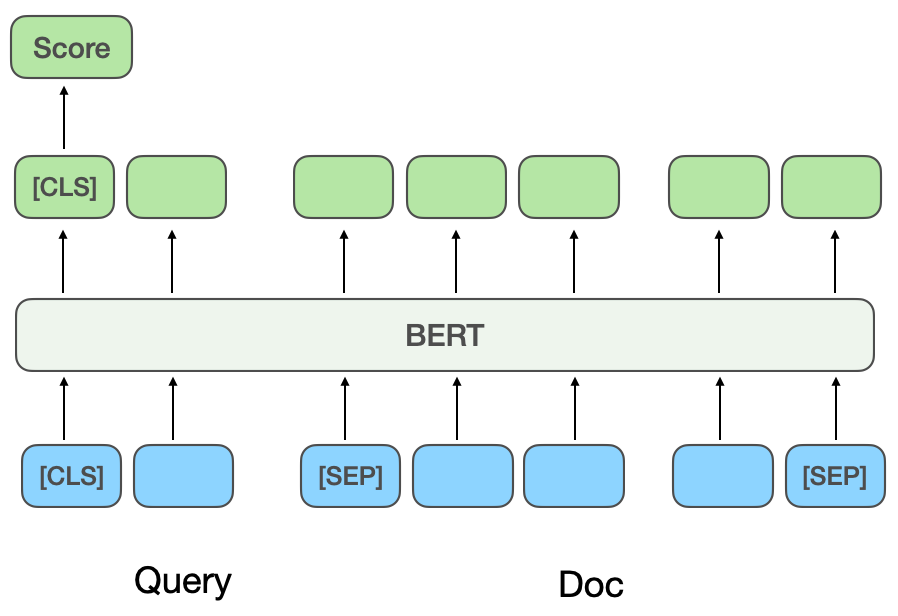
(b) 基於交互作用的相關性模型
圖2 深度語意配對相關性模型
##基於表示的深度語意匹配模型:基於表示的方法分別學習Query及Doc的語意向量表示,再基於兩個向量計算相似度。微軟的DSSM模型[3]提出了經典的雙塔結構的文本匹配模型,即分別使用相互獨立的兩個網絡構建Query和Doc的向量表示,用餘弦相似度衡量兩個向量的相關程度。微軟Bing搜尋的NRM[4]針對Doc表徵問題,除了基礎的Doc標題和內容,還考慮了其他多源資訊(每類資訊稱為一個域Field ),如外鏈、使用者點擊過的Query等,考慮一個Doc中有多個Field,每個Field內又有多個實例(Instance),每個Instance對應一個文本,如一個Query字。模型先學習Instance向量,將所有Instance的表示向量聚合起來就得到一個Field的表示向量,將多個Field的表示向量聚合起來得到最終Doc的向量。 SentenceBERT[5]將預訓練模型BERT引入雙塔的Query和Doc的編碼層,採用不同的Pooling方式取得雙塔的句向量,透過點乘、拼接等方式對Query和Doc進行互動。
大眾點評的搜尋相關性早期模型就藉鑒了NRM和SentenceBERT的思想,採用了圖2(a)所示的基於表示的多域相關性模型結構,基於表示的方法可以將POI的向量提前計算並存入緩存,線上只需計算Query向量與POI向量的交互部分,因此在線上使用時計算速度較快。
基於互動的深度語意配對模型:基於互動的方法不會直接學習Query和Doc的語意表示向量,而是在底層輸入階段就讓Query和Doc進行交互,建立一些基礎的匹配訊號,再將基礎匹配訊號融合成一個匹配分。 ESIM[6]是預訓練模型引入先前被業界廣泛使用的經典模型,首先對Query和Doc進行編碼得到初始向量,再用Attention機制進行交互加權後與初始向量進行拼接,最終分類得到相關性得分。
引入預訓練模型BERT進行交互計算時,通常將Query和Doc拼接作為BERT句間關係任務的輸入,透過MLP網路得到最終的相關性分數[ 7],如圖2(b)所示。 CEDR[8]在BERT句間關係任務取得Query和Doc向量之後,將Query和Doc向量進行拆分,進一步計算Query與Doc的餘弦相似矩陣。美團搜尋團隊[9]將基於互動的方法引入美團搜尋相關性模型中,引入商戶品類資訊進行預訓練,並引入實體辨識任務進行多工學習。美團到店搜尋廣告團隊[10]提出了將基於交互的模型蒸餾到基於表示的模型上的方法,實現雙塔模型的虛擬交互,在保證性能的同時增加Query與POI的交互。
基於表示的模型重在表示POI的全局特徵,缺乏線上Query與POI的匹配信息,基於交互的方法可以彌補基於表示方法的不足,增強Query和POI的交互,提升模型表達能力,同時,鑑於預訓練模型在文本語義匹配任務上的強勁表現,點評搜索相關性計算確定了基於美團預訓練模型MT-BERT[11]的互動式方案。將基於預訓練模型的互動式BERT應用在點評搜尋場景的相關性任務中時,仍有許多挑戰:
經過不斷探索與嘗試,我們針對POI側的複雜多源信息,構造了適配點評搜索場景的POI文本摘要;為了讓模型更好地適配點評搜尋相關性計算,採用了兩階段訓練的方法,並根據相關性計算的特點改造了模型結構;最後,透過優化計算流程、引入快取等措施,成功降低了模型即時計算和整體應用鏈路的耗時,滿足了線上即時計算BERT的性能要求。
3.1 如何更好地建構POI側模型輸入資訊#在判定Query與POI的相關程度時,POI側有十幾個參與計算的字段,某些欄位下的內容特別多(例如一個商家可能有上百個推薦菜),因此需要找到合適的方式抽取並組織POI側信息,輸入到相關性模型中。通用搜尋引擎(如百度),或常見垂類搜尋引擎(如淘寶),其Doc的網頁標題或商品標題資訊量豐富,通常是相關性判定過程中Doc側模型輸入的主要內容。
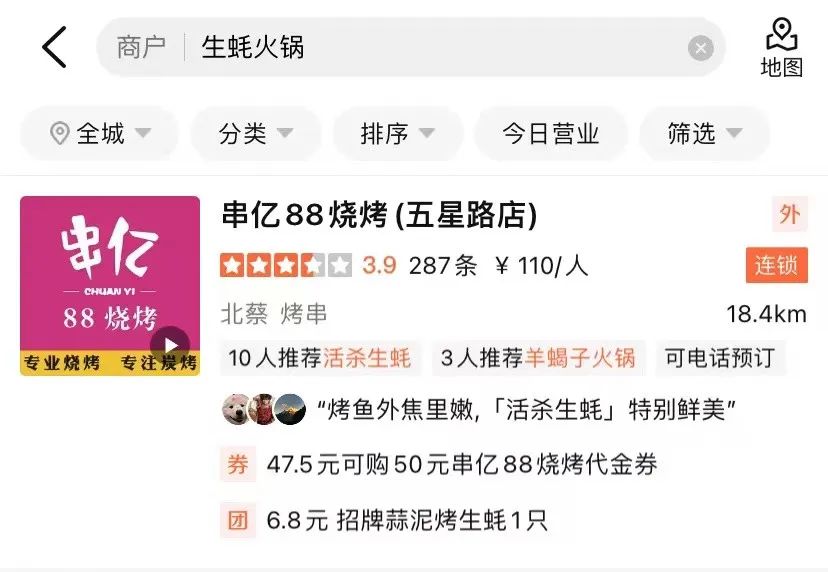
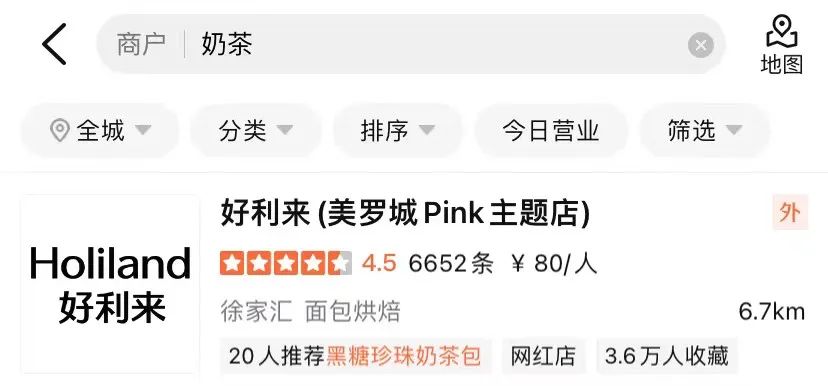
如圖3(a)所示,在通用搜尋引擎中,透過搜尋結果的標題可以一眼看出對應網站的關鍵資訊及是否與Query相關,而在圖3(b)大眾點評在 App的搜尋結果中,僅透過商家名稱段無法取得充足的商家資訊,需要結合商家類別目(奶茶果汁)、使用者推薦菜色(奧利奧利奶茶) 、標籤(網紅店)、地址(武林廣場)多個欄位才能判斷該商家與Query「武林廣場網紅奶茶」的相關性。
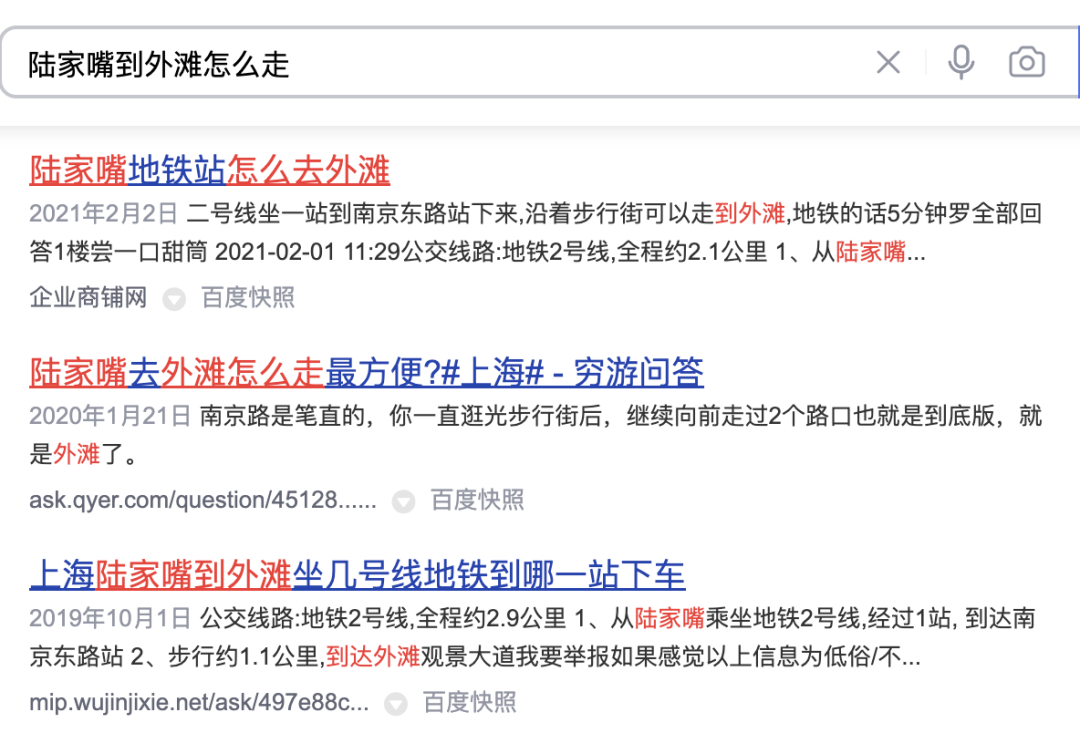
(a) 通用搜尋引擎搜尋結果範例
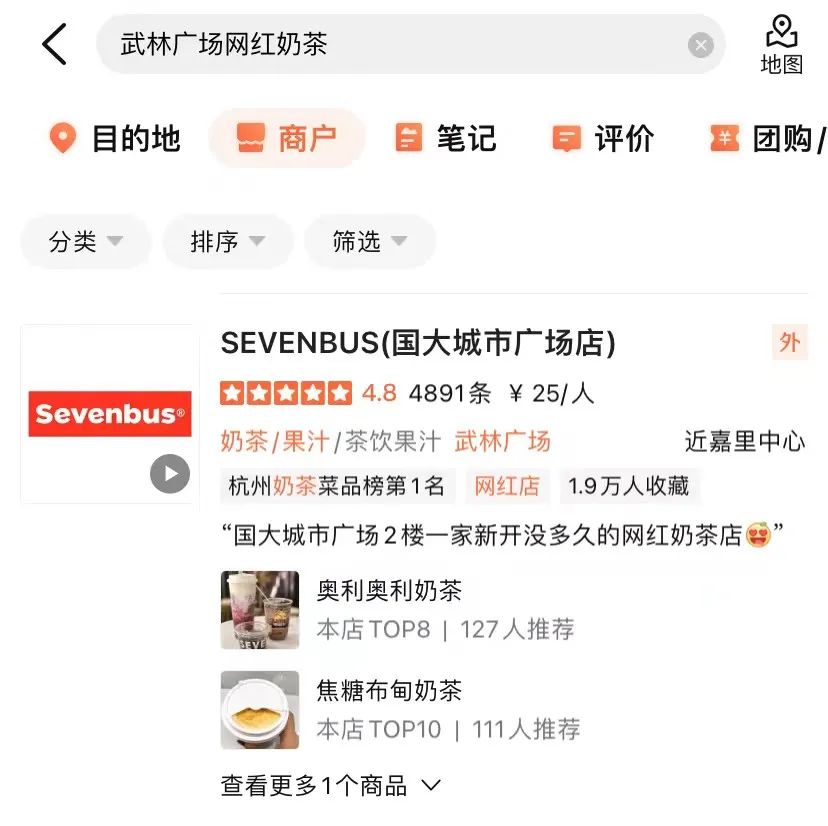
# #(b) 大眾點評App搜尋結果範例
圖3 通用搜尋引擎與大眾點評搜尋結果比較
標籤抽取是業界比較通用的抽取主題資訊的途徑,因此我們首先嘗試了透過商家標籤來建構POI側模型輸入的方法,根據商家的評論、基礎資訊、菜色、商家對應的頭部搜尋點擊詞等抽取具有代表性的商家關鍵字作為商家標籤。在線上使用時,將已抽取的商家標籤,及商家名稱和類別目基礎資訊一起作為模型的POI側輸入訊息,與Query進行交互計算。然而,商家標籤對商家資訊的涵蓋範圍仍不夠全面,例如用戶搜尋菜色「蛋奶凍」時,某個距用戶很近的韓式料理店有雞蛋羹售賣,但該店的招牌菜、頭點擊詞等均與「雞蛋羹」無關,導致該店所抽取的標籤詞也與「雞蛋羹」相關性較低,因此模型會將該店判斷為不相關,從而對用戶體驗帶來傷害。
為了獲得最全面的POI表徵,一個方案是不抽取關鍵字,直接將商家的所有欄位拼接到模型輸入中,但這種方式會因為模型輸入長度過長而嚴重影響線上效能,大量冗餘資訊也會影響模型表現。
為建構更具資訊量的POI側資訊作為模型輸入,我們提出了POI匹配欄位摘要抽取的方法,即結合線上Query的匹配情況即時抽取POI的匹配字段文本,並建構匹配字段摘要作為POI側模型輸入資訊。 POI匹配字段摘要抽取流程如圖4所示,我們基於一些文本相似度特徵,將與Query最相關且最具資訊量的文本字段提取出來,並融合字段類型信息構建為匹配字段摘要。線上使用時,將已抽取的POI符合欄位摘要、商家名稱及類別目基礎資訊一起輸入為POI側模型。
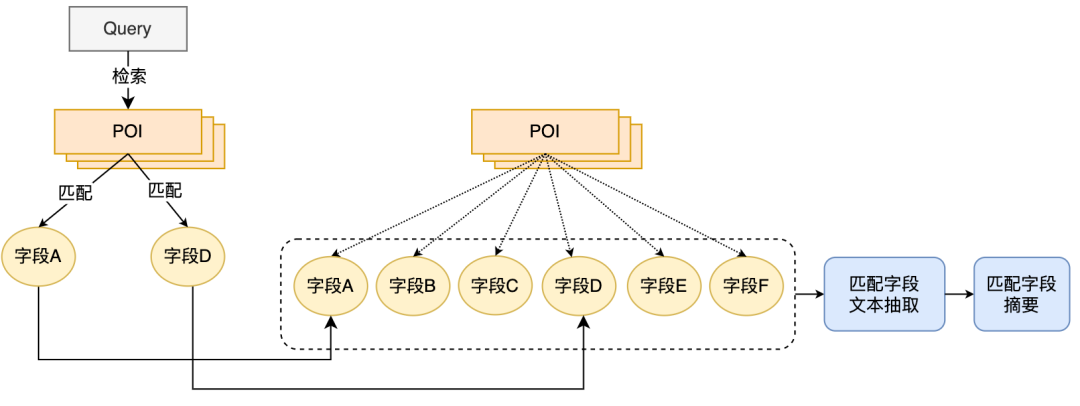
圖4 POI符合欄位摘要擷取流程在確定POI側模型輸入資訊後,我們採用BERT句間關係任務,先用MT-BERT對Query側和POI側匹配字段摘要資訊進行編碼,然後使用池化後的句向量計算相關分。採用POI匹配字段摘要的方案建構POI側模型輸入資訊後,配合樣本迭代,相較於基於標籤的方法,模型的效果有了極大的提升。
3.2 如何最佳化模型來更好地適配點評搜尋相關性計算讓模型更好地適配點評搜尋相關性計算任務包含兩層意義:大眾評論搜尋場景下的文字資訊與MT-BERT預訓練模型所使用的語料在分佈上有一定的差異;預訓練模型的句間關係任務與Query和POI的相關性任務也略有不同,需要對模型結構進行改造。經過不斷探索,我們採用基於領域資料的兩階段訓練方案,結合訓練樣本構造,使預訓練模型更適配點評搜尋場景的相關性任務;並提出了基於多相似矩陣的深度交互相關性模型,加強Query和POI的交互,提升模型對複雜的Query和POI資訊的表達能力,優化相關性計算效果。
為了有效利用用戶點擊數據,並使預訓練模型MT-BERT更適配點評搜尋相關性任務,我們藉鑑百度搜索相關性[12]的思想,引入多階段訓練方法,採用用戶點擊和負採樣資料進行第一階段領域適配的預訓練(Continual Domain-Adaptive Pre-training),採用人工標註資料進行第二階段訓練(Fine-Tune),模型結構如下圖5所示:
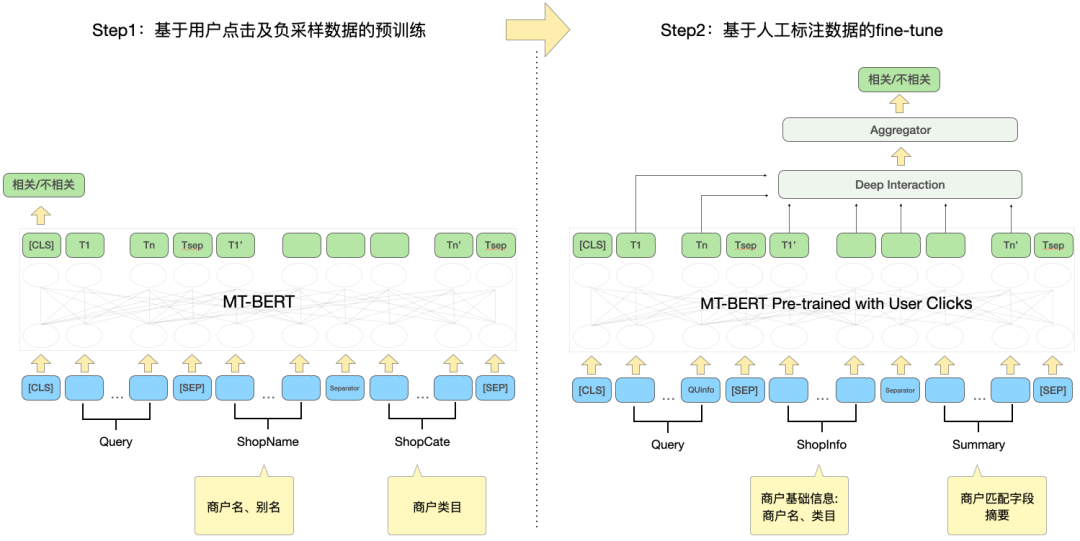
圖5 基於點擊及手動標註資料的兩階段訓練模型結構
基於點擊資料的第一階段訓練
引入點擊資料作為第一階段訓練任務的直接原因是在點評搜尋場景下存在著一些特有的問題,例如「開心」和「高興」兩個詞在通用場景下是幾乎完全同義詞的詞,但是在點評搜尋的場景下「開心燒烤」和「高興燒烤」卻是兩家完全不同的品牌商戶,因此點擊數據的引入能夠幫助模型學習到搜尋場景下的一些特有知識。但直接將點擊樣本用於相關性判斷會存在較大噪聲,因為用戶點擊某個商家可能是由於排序較為靠前導致的誤點擊,而未點擊某個商家也可能僅僅是因為商家距離較遠,而並不是因為相關性問題,因此我們引入了多種特徵和規則來提高訓練樣本自動標註的準確率。
在建構樣本時,透過統計是否點擊、點擊位次、最大點擊商家距離使用者的距離等特徵篩選候選樣本,將曝光點擊率大於一定閾值的Query-POI對作為正例,並根據業務特徵對不同類型商家調整不同的閾值。在負例的構造上,Skip-Above取樣策略將位於點擊商家之前且點擊率小於閾值的商家才做為負樣本。此外,隨機負採樣的方式可以為訓練樣本補充簡單負例,但考慮隨機負採樣時也會引入一些噪聲數據,因此我們利用人工設計的規則對訓練數據進行降噪:當Query的類目意圖與POI的類別目系統較為一致時或與POI名高度相符時,則將其從負樣本中剔除。
基於人工標註資料的第二階段訓練
經過第一階段訓練後,考慮到無法完全清除掉點擊資料中的噪音,以及相關性任務的特點,因此需要引入基於人工標註樣本的第二階段訓練來對模型進行糾偏。除了隨機採樣一部分資料交給人工去標註外,為了盡可能提升模型的能力,我們透過難例挖掘和對比樣本增強方式生產大量高價值樣本交給人工去標註。具體如下:
1)難例挖掘
2)對比樣本增強:借鑒對比學習的思想,為一些高度匹配的樣本生成對比樣本進行數據增強,並進行人工標註確保樣本標籤的準確率。透過比較樣本之間的差異,模型可以關注到真正有用的信息,同時提升對同義詞的泛化能力,從而得到更好的效果。
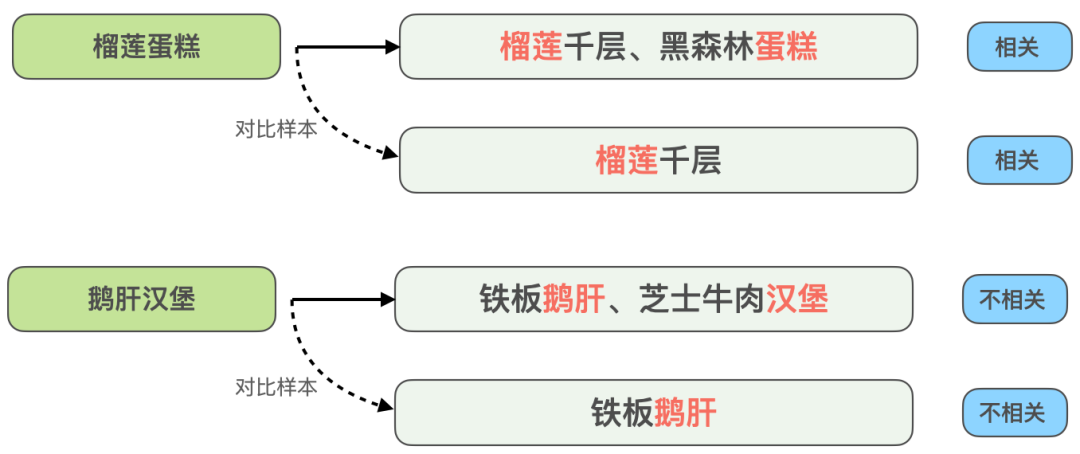
圖6 比較樣本增強範例
以跨菜品匹配的相關性問題為例,如上圖6所示,同樣是Query拆開後與商家的多個推薦菜字段匹配的情況,Query「榴槤蛋糕」與推薦菜「榴槤千層、黑森林蛋糕」是相關的,但Query 「鵝肝漢堡」與「鐵板鵝肝、起司牛肉漢堡」是不相關的,為了增強模型對這類高度匹配但結果相反的Case的識別能力,我們構造了「榴蓮蛋糕」與「榴蓮千層」、「鵝肝漢堡」與「鐵板鵝肝」這兩組對比樣本,去掉了與Query在文本上匹配但對模型判斷沒有幫助的信息,讓模型學到真正決定是否相關的關鍵信息,同時提升模型對「蛋糕」和「千層」這類同義詞的泛化能力。類似地,其他類型的難例同樣可以用這種樣本增強方式來提升效果。
BERT句間關係是一個通用的NLP任務,用來判斷兩個句子的關係,而相關性任務是計算Query和POI的相關程度。在計算過程中,句間關係任務不僅計算Query與POI的交互,也計算Query內部與POI內部的交互,而相關性計算則較關注Query與POI的交互。此外,在模型迭代過程中,我們發現部分類型的困難BadCase對模型的表達能力有更高要求,例如文字高度匹配但不相關的類型。因此,為進一步提升模型對複雜的Query和POI在相關性任務上的計算效果,我們對第二階段訓練中的BERT句間關係任務進行改造,提出了基於多相似矩陣的深度交互模型,透過引入多相似矩陣來對Query和POI進行深度交互,引入indicator矩陣以更好地解決困難BadCase問題,模型結構如下圖7所示:
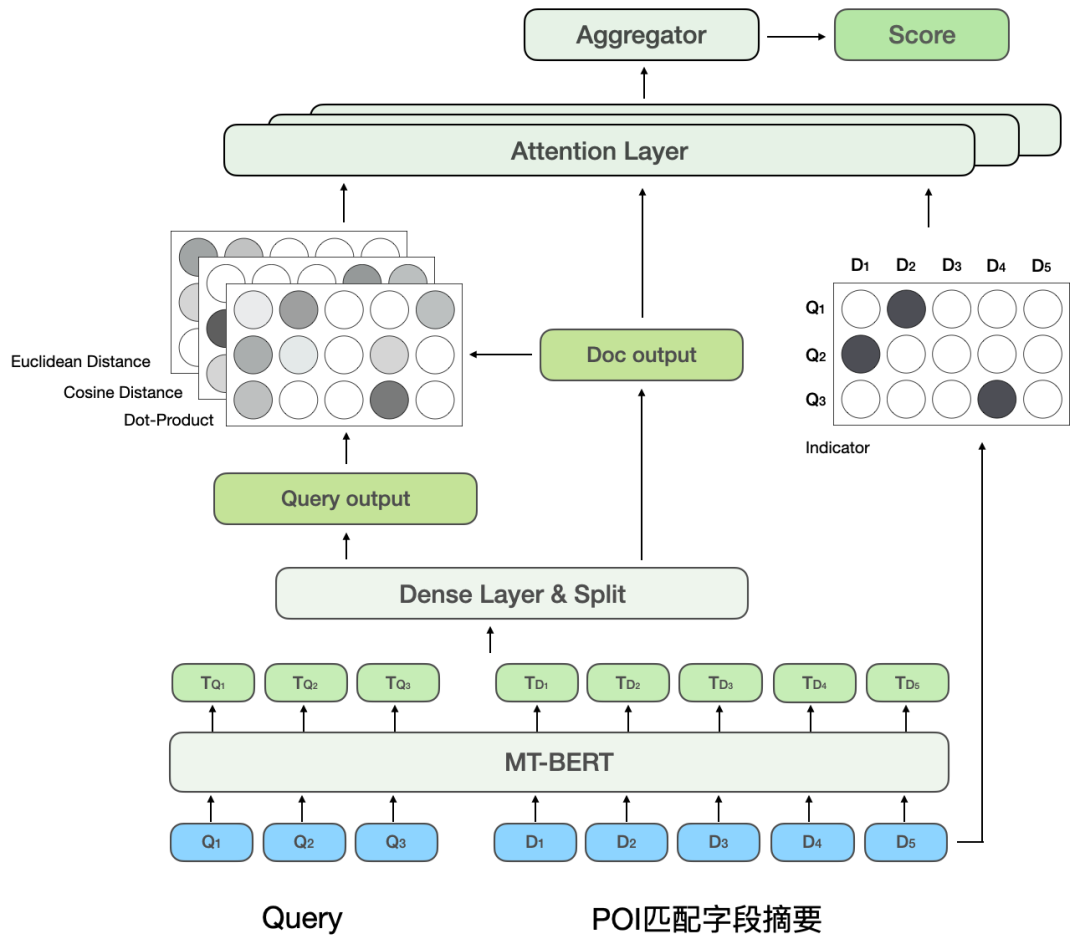
##圖7 基於多重相似矩陣的深度交互作用相關性模型
受CEDR[8]的啟發,我們將經過MT-BERT編碼後的Query和POI向量進行拆分,用於明確地計算兩部分的深度交互關係,將Query和POI拆分並進行深度交互,一方面可以專門用於學習Query與POI的相關程度,另一方面,增加的參數量可以提升模型的擬合能力。
參考MatchPyramid[13]模型,深度交互相關性模型計算了四種不同的Query-Doc相似矩陣並進行融合,包括Indicator、Dot- product、餘弦距離及歐氏距離,並與POI部分的輸出進行Attention加權。其中Indicator矩陣用來描述Query與POI的Token是否一致,計算方式如下:
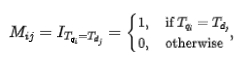
#其中代表匹配矩陣的第行列對應的元素,代表Query的第個Token,代表POI的第個Token。由於Indicator矩陣是表示Query與POI是否字面匹配的矩陣,與另外三個語意匹配矩陣的輸入格式不同,Dot-product、餘弦距離、歐式距離三個匹配矩陣先融合,再將得到的結果與Indicator矩陣進一步融合後再計算最終的相關性得分。
Indicator矩陣可以較好地刻畫Query和POI的匹配關係,該矩陣的引入主要考慮到判定Query和POI相關程度時的一個難點:有時即使文本高度匹配,兩者也不相關。基於互動的BERT模型結構更容易將文字匹配程度高的Query和POI判定為相關,但是在點評搜尋場景中,有些難例卻未必如此。例如“豆汁”和“綠豆汁”雖然高度匹配,但並不相關。 「貓空」和「貓的天空之城」雖然是拆開匹配,但因為前者是後者的縮寫而相關。因此,將不同的文本匹配情況透過Indicator矩陣直接輸入給模型,讓模型明確地接收「包含」、「拆開匹配」等文本匹配情況,在幫助模型提升對難例判別能力的同時,也不會影響大部分正常的Case的表現。
基於多重相似矩陣的深度交互相關性模型將Query和POI拆分後計算相似矩陣,相當於讓模型對Query和POI進行明確交互,使模型更加適配相關性任務。多個相似矩陣則增加了模型對Query和POI相關程度計算的表徵能力,而Indicator矩陣則是針對相關性任務中複雜的文本匹配情況所做的特殊設計,讓模型對不相關結果的判斷更加準確。
將相關性運算部署在線上時,現有方案通常會採用知識蒸餾的雙塔結構[10,14]以確保線上計算效率,但此種處理方式或多或少對於模型的效果是有損的。點評搜尋相關性計算為保證模型效果,在線上使用了基於互動的12層BERT預訓練相關性模型,需要對每個Query下的數百個POI經過12層BERT的模型預測。為確保線上運算效率,我們從模型即時計算流程和應用鏈路兩個角度出發,透過引入快取機制、模型預測加速、引入前置黃金規則層、將相關性計算與核心排序並行化等措施優化相關性模型在線上部署時的效能瓶頸,使得12層基於互動的BERT相關性模型在線上穩定且有效率地運行,保證可以支援數百個商家和Query間的相關性運算。
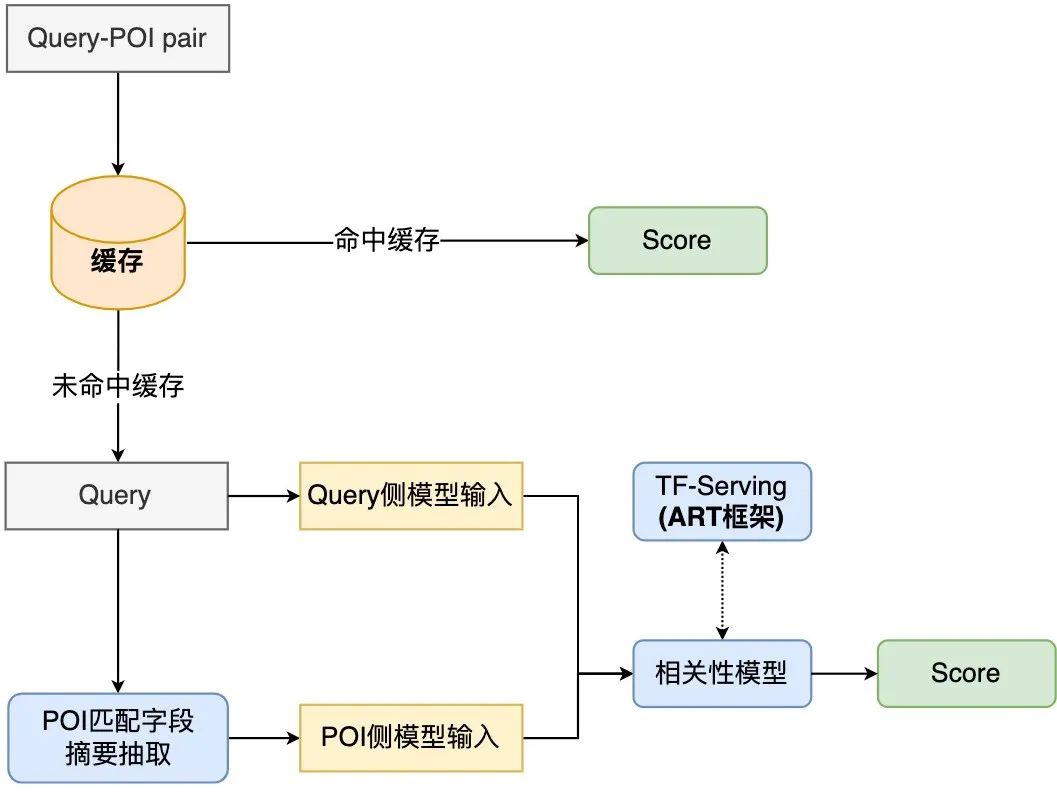
#圖8 相關性模型線上計算流程圖
點評搜尋相關性模型的線上計算流程如圖8所示,透過快取機制及TF-Serving模型預測加速來最佳化模型即時運算的效能。
為有效利用運算資源,模型線上部署引入快取機制,將高頻Query的相關性分數寫入快取。後續呼叫時會優先讀取緩存,若命中緩存則直接輸出評分,未命中緩存的則進行線上即時計算。快取機制大大節省了運算資源,有效緩解線上運算的效能壓力。
對未命中快取的Query,將其處理為Query側模型輸入,透過圖4所述的流程取得每個POI的匹配欄位摘要,並處理為POI側模型輸入格式,再呼叫線上相關性模型輸出相關分。相關性模型部署在TF-Serving上,在模型預測時,採用美團機器學習平台的模型最佳化工具ART框架(基於Faster-Transformer[15]改進)進行加速,在保證精度的同時大大提高了模型預測速度。
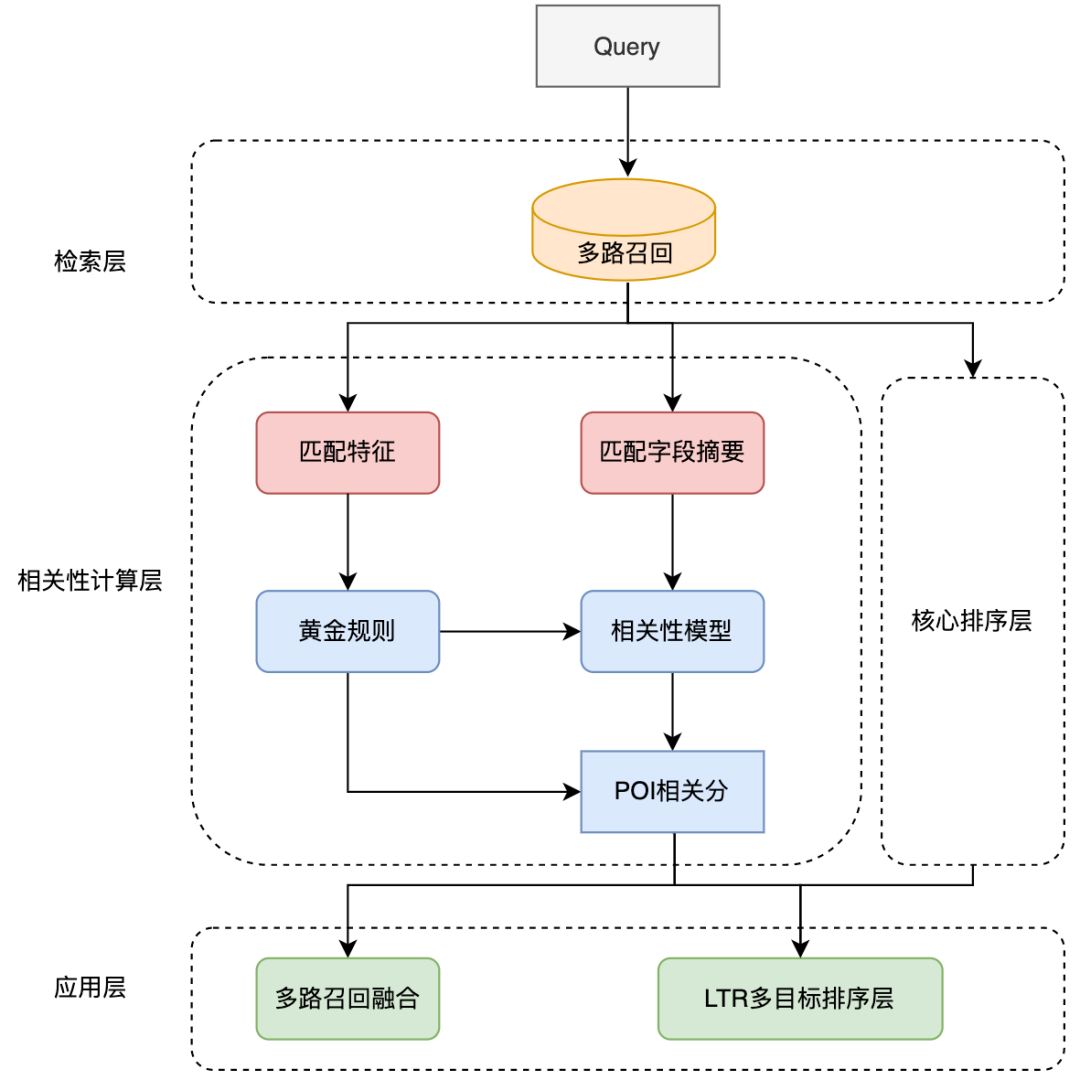
#圖9 相關性模型在點評搜尋連結中的應用
相關性模型在搜尋連結中的應用如上圖9所示,透過引入前置黃金規則、將相關性計算與核心排序層並行化來優化整體搜尋連結中的性能。
為了進一步對相關性調用鏈路加速,我們引入了前置黃金規則對Query分流,對部分Query透過規則直接輸出相關分,從而緩解模型計算壓力。在黃金規則層中利用文字比對特徵對Query和POI進行判斷,例如,若搜尋字詞跟商家名稱完全一致,則透過黃金規則層直接輸出「相關」的判定,而無需透過相關性模型計算相關分。
在整體計算連結中,相關性計算過程與核心排序層進行並發操作,以確保相關性計算對搜尋連結的整體耗時基本無影響。在應用層,相關性計算被用在搜尋連結的回想和排序等多個環節。為降低搜尋清單的首屏不相關商家佔比,我們將相關分引入LTR多目標融合排序中進行清單頁排序,並採用多路召回融合策略,利用相關性模型的結果,僅將補充召迴路中的相關商戶融合到清單中。
為精準反映模型迭代的離線效果,我們透過多輪人工標註方式建構了一批Benchmark,考慮到目前線上實際使用時主要目標為降低BadCase指標,即對不相關商戶的準確識別,我們採用負例的準確率、召回率、F1值作為衡量指標。經過兩階段訓練、樣本建構及模型迭代帶來的效益如下表1所示:
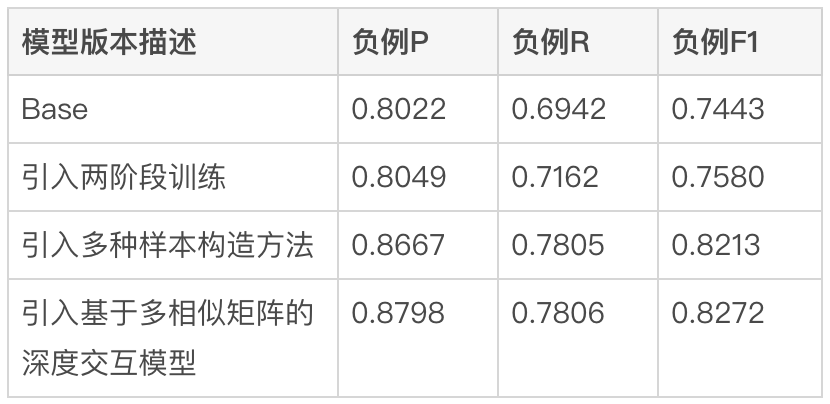
#表1 點評搜尋相關性模型迭代離線指標
初始方法(Base)採用Query拼接POI匹配欄位摘要資訊的BERT句對分類任務,Query側模型輸入採用使用者輸入的原始Query, POI側採用商家名稱、商家類別目及符合欄位摘要文字拼接方式。引入基於點擊資料的兩階段訓練後,負例F1指標相比Base方法提升1.84%,透過引入對比樣本、難例樣本持續迭代訓練樣本並配合第二階段的模型輸入構造,負例F1相比Base顯著提升10.35%,引入基於多重相似矩陣的深度交互方法後,負例F1相比Base提升11.14%。模型在Benchmark上的整體指標也達到了AUC為0.96,F1為0.97的高值。
為有效衡量使用者搜尋滿意度,點評搜尋每天對線上實際流量進行抽樣並人工標註,採用清單頁首屏BadCase率作為相關性模型效果評估的核心指標。相關性模型上線後,點評搜尋的月平均BadCase率指標相比上線前顯著下降了2.9pp(Percentage Point,百分比絕對點),並在後續幾週BadCase率指標穩定在低點附近,同時,搜尋清單頁的NDCG指標穩定提升2pp。可以看出相關性模型可以有效識別不相關商戶,顯著降低了搜尋的首屏不相關性問題佔比,從而提升了用戶的搜尋體驗。
下圖10列舉了部分線上BadCase解決範例,小標題是此範例對應的Query,左邊為應用了相關性模型的實驗組,右邊為對照組。圖10(a)當搜尋詞為「佩姐」時,相關性模型將商家核心詞包含「佩姐」的商家「佩姐名品」判斷為相關,並將用戶可能想找但輸錯的高質目標商戶「珮姐老火鍋」也判斷為相關,同時,透過引入地址字段標識,將地址中位於「珮姐」旁的商戶判斷為不相關;圖10(b)中用戶透過Query「柚子日料自助」想找一家名為「柚子」的日料自助店,相關性模型將拆詞匹配到有柚子相關商品售賣的日料自助店「竹若鮪魚」正確判斷為不相關並將其排序靠後,保證展示在靠前的均為更符合用戶主要需求的商家。
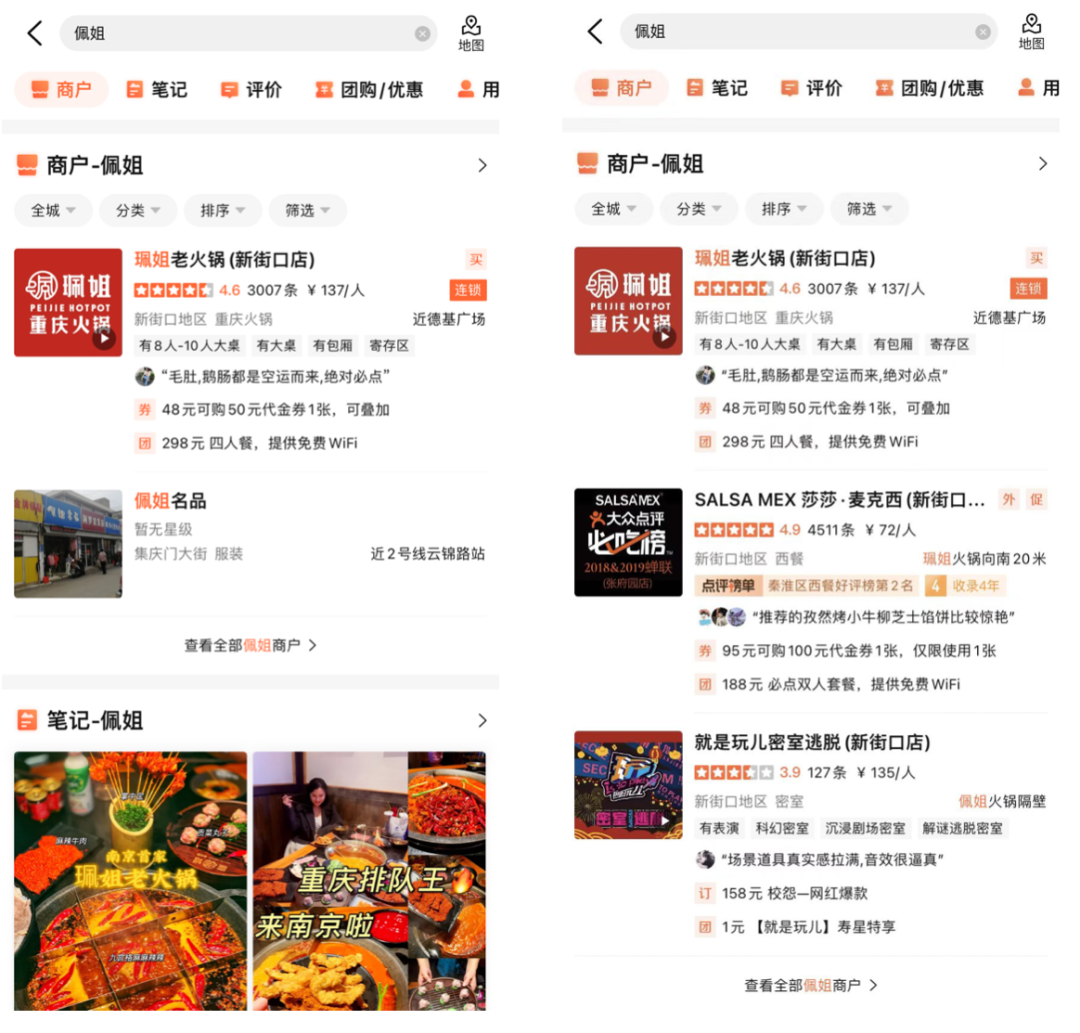
(a) 佩姐
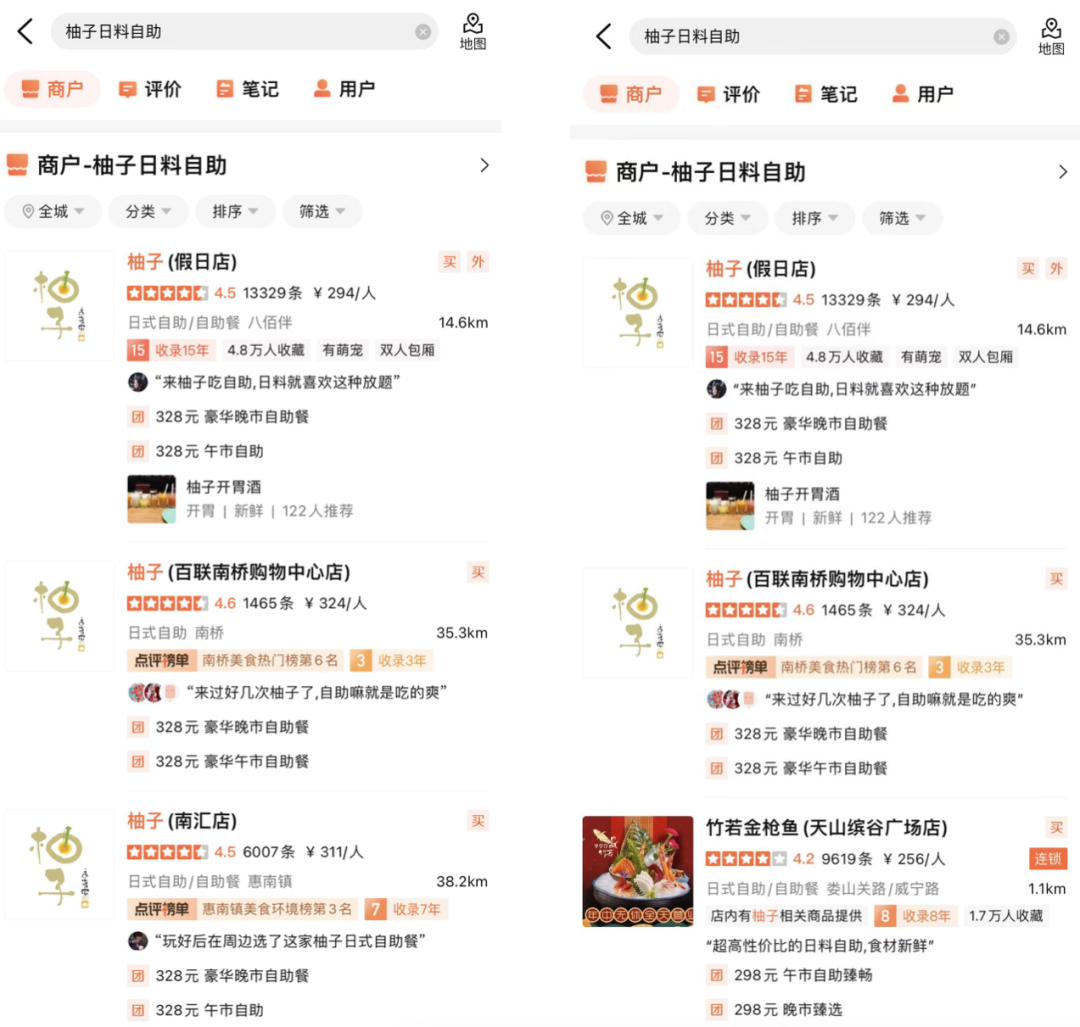 (b) 柚子日料自助圖10 線上BadCase解決範例
(b) 柚子日料自助圖10 線上BadCase解決範例
本文介绍了大众点评搜索相关性模型的技术方案及应用实战。为了更好地构造商户侧模型输入信息,我们引入了实时抽取商户匹配字段摘要文本的方法来构造商户表征作为模型输入;为了优化模型来更好地适配点评搜索相关性计算,使用了两阶段训练的方式,采用基于点击和人工标注数据的两阶段训练方案来有效利用大众点评的用户点击数据,并根据相关性计算的特点提出了基于多相似矩阵的深度交互结构,进一步提升相关性模型的效果;为缓解相关性模型的线上计算压力,在线上部署时引入缓存机制和TF-Serving预测加速,引入黄金规则层对Query分流,将相关性计算与核心排序层并行化,从而满足了线上实时计算BERT的性能要求。通过将相关性模型应用在搜索链路各环节,显著降低了不相关问题占比,有效改善了用户的搜索体验。
目前,点评搜索相关性模型在模型表现及线上应用上仍有提升空间,在模型结构方面,我们将探索更多领域先验知识的引入方式,例如识别Query中实体类型的多任务学习、融入外部知识优化模型的输入等;在实际应用方面,将进一步细化为更多档位,以满足用户对于精细化找店的需求。我们还会尝试将相关性的能力应用到非商户模块中,优化整个搜索列表的搜索体验。
校娅*、沈元*、朱迪、汤彪、张弓等,均来自美团/点评事业部搜索技术中心。*为本文共同一作。
以上是大眾點評搜尋相關性技術探索與實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































