

儘管大型語言模型能力驚人,但由於規模較大,其部署所需的成本往往巨大。華盛頓大學聯合Google雲端運算人工智慧研究院、Google研究院針對此問題進行了進一步解決,提出了逐步蒸餾(Distilling Step-by-Step)範式幫助模型訓練。相對於LLM,這種方法對於訓練小型模型並應用於特定任務方面更有效,且所需的訓練資料比傳統的微調和蒸餾更少。在一個基準任務上,他們的 770M T5 模型勝過了 540B PaLM 模型。令人印象深刻的是,他們的模型只使用了可用數據的 80%。

#雖然大型語言模型(LLMs)展現了令人印象深刻的少樣本學習能力,但要將這樣大規模的模型部署在現實應用上是很難的。為 1750 億參數規模的 LLM 提供服務的專門基礎設施,至少需要 350GB 的 GPU 記憶體。更甚者,現今最先進的 LLM 是由超過 5,000 億的參數組成的,這意味著它需要更多的記憶體和運算資源。這樣的計算要求對於大多數生產商來說都是難以企及的,更何況是要求低延遲的應用了。
為了解決大型模型的這個問題,部署者往往會採用小一些的特定模型來取代。這些小一點的模型用常見範式 —— 微調或是蒸餾來進行訓練。微調使用下游的人類註釋資料升級一個預先訓練過的小模型。蒸餾用較大的 LLM 產生的標籤訓練同樣較小的模型。但很遺憾,這些範式在縮小模型規模的同時也付出了代價:為了達到與 LLM 相當的性能,微調需要昂貴的人類標籤,而蒸餾需要大量很難獲得的無標籤數據。
在一篇題為「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」的論文中,來自華盛頓大學、谷歌的研究者引入了一種新的簡單機制— 逐步蒸餾(Distilling step-bystep),用於使用更少的訓練資料來訓練較小的模型。這種機制減少了微調和蒸餾 LLM 所需的訓練資料量,使其有更小的模型規模。

#論文連結:https://arxiv.org/pdf/2305.02301 v1.pdf
該機制的核心是換一個角度,將LLM 看作是可以推理的agent,而不是雜訊標籤的來源。 LLM 可以產生自然語言的理由(rationale),這些理由可以用來解釋和支持模型所預測的標籤。例如,當被問及「一位先生攜帶著打高爾夫球的設備,他可能有什麼?(a) 球桿,(b) 禮堂,(c) 冥想中心,(d) 會議,(e) 教堂」 ,LLM 可以透過思考鏈(CoT)推理回答出「(a)球桿」,並透過說明「答案一定是用來打高爾夫球的東西」來合理化這個標籤。在上述選擇中,只有球桿是用來打高爾夫的。研究者使用這些理由作為額外更豐富的資訊在多任務訓練設定中訓練較小的模型,並進行標籤預測和理由預測。
如圖 1 所示,逐步蒸餾可以學習特定任務的小模型,這些模型的參數量還不到 LLM 的 1/500。與傳統的微調或蒸餾相比,逐步蒸餾使用的訓練範例也少得多。

#實驗結果顯示,在4 個NLP 基準中,有三個有希望的實驗結論。
當只有未標記的資料時,小模型的表現相比LLM 而言仍然有過之而無不及—— 只用一個11B 的T5 模型就超過了540B 的PaLM 的性能。
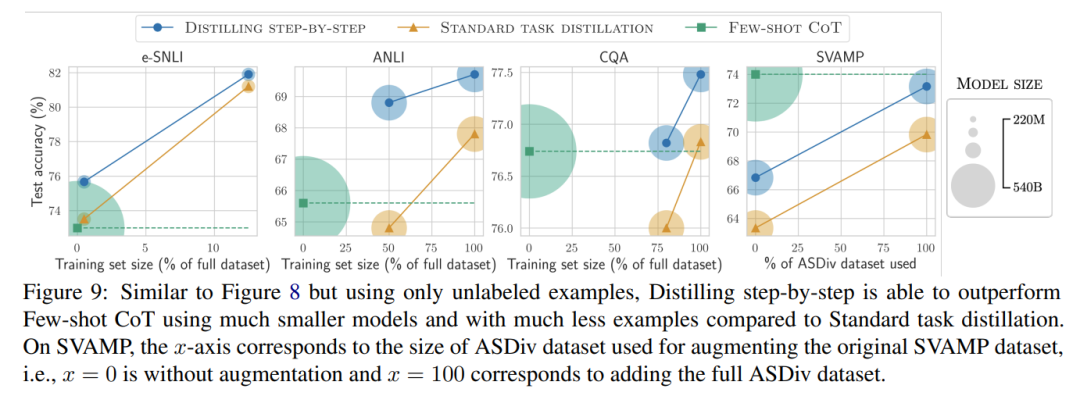
該研究進一步表明,當一個較小的模型表現比LLM 差時,與標準的蒸餾方法相比,逐步蒸餾可以更有效地利用額外的無標籤資料來使較小的模型媲美LLM 的性能。
研究者提出了逐步蒸餾這個新範式,是利用LLM 對其預測的推理能力,以數據高效率的方式訓練更小的模型。整體框架如圖 2 所示。
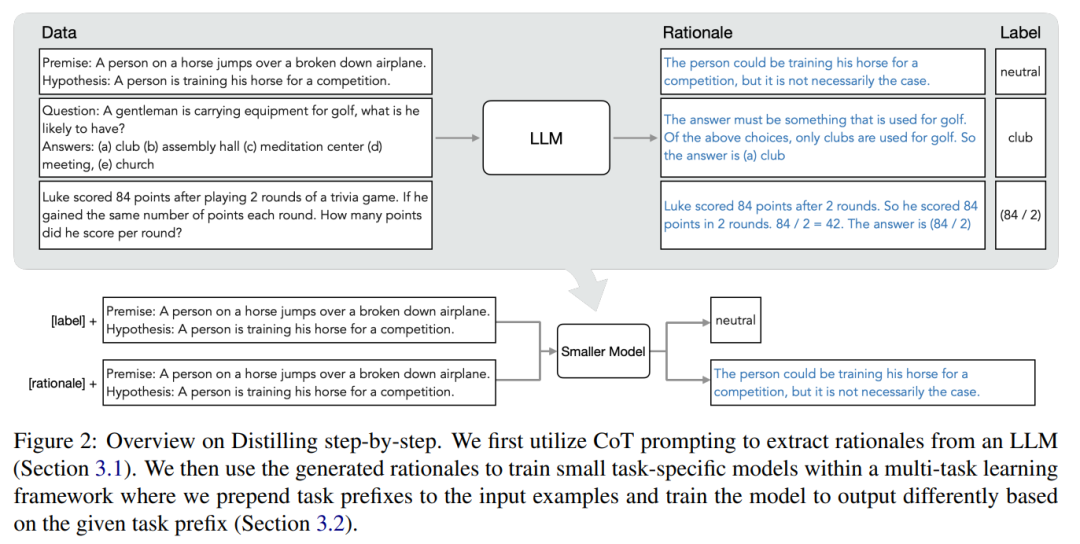
#這個範式有兩個簡單的步驟:首先,給定一個LLM 和一個無標籤的資料集,提示LLM 產生輸出標籤以及證明該標籤成立的理由。理由用自然語言解釋,為模型預測的標籤提供支持(見圖 2)。理由是當前自監督 LLM 的一個湧現的行為屬性。
然後,除了任務標籤之外,利用這些理由來訓練更小的下游模型。說白了,理由能提供了更豐富、更詳細的信息,來說明一個輸入為什麼被映射到一個特定的輸出標籤。
研究者在實驗中驗證了逐步蒸餾的有效性。首先,與標準的微調和任務蒸餾方法相比,逐步蒸餾有助於實現更好的效能,訓練實例的數量少得多,大幅提高了學習小型特定任務模型的資料效率。
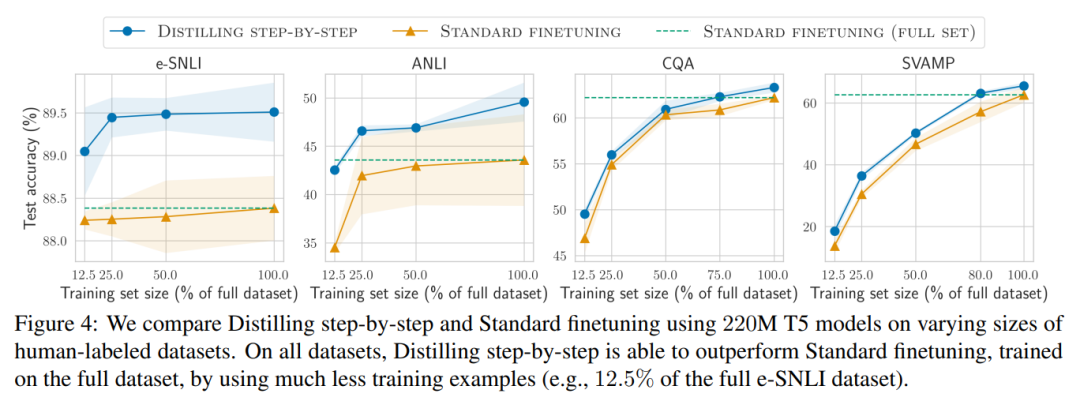
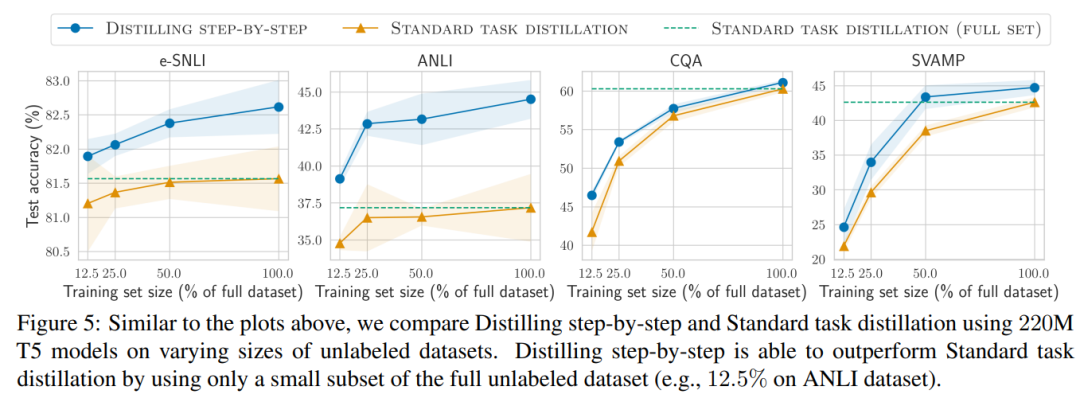
研究表明,逐步蒸餾方法以更小的模型大小超越了LLM 的性能,與llm 相比,大大降低了部署成本。
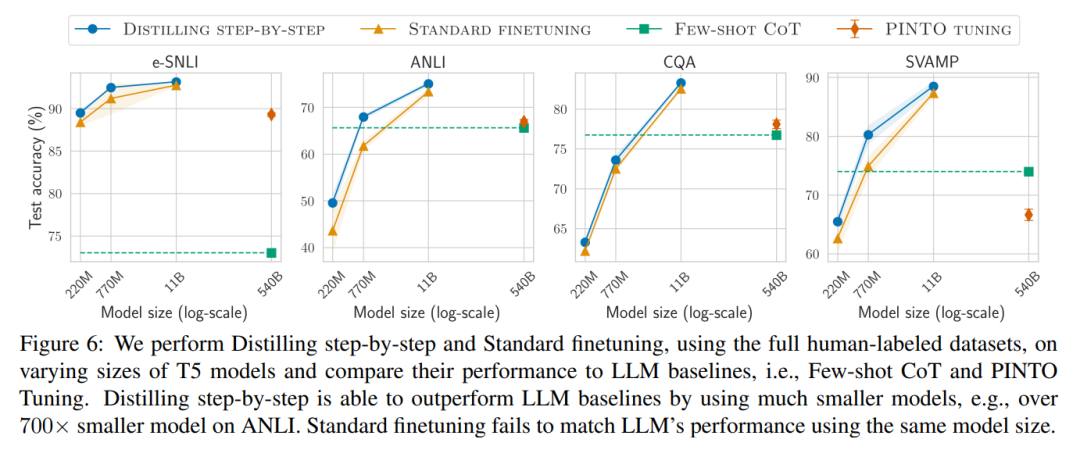
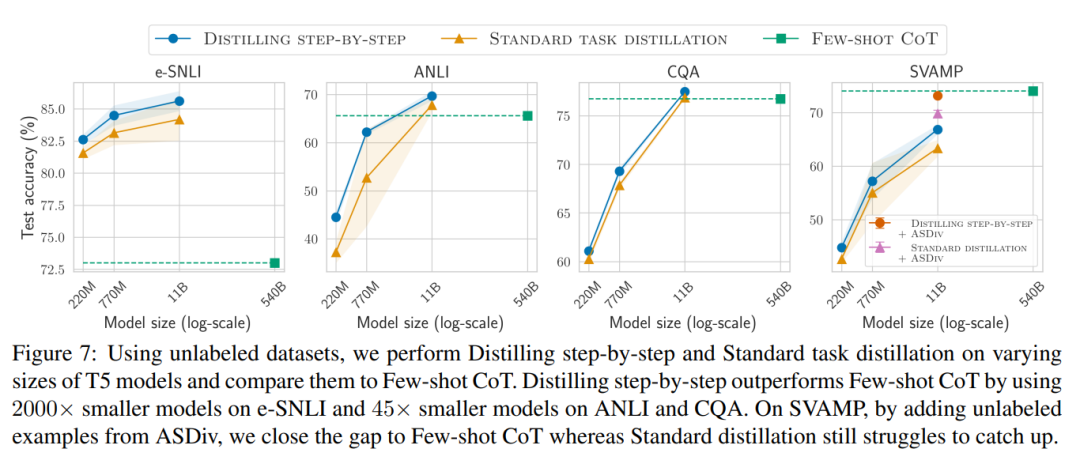
最後,研究者調查了逐步蒸餾方法在超過LLM 的性能方面所需的最低資源,包括訓練範例數量和模型大小。他們展示了逐步蒸餾方法透過使用更少的數據和更小的模型,同時提高了數據效率和部署效率。 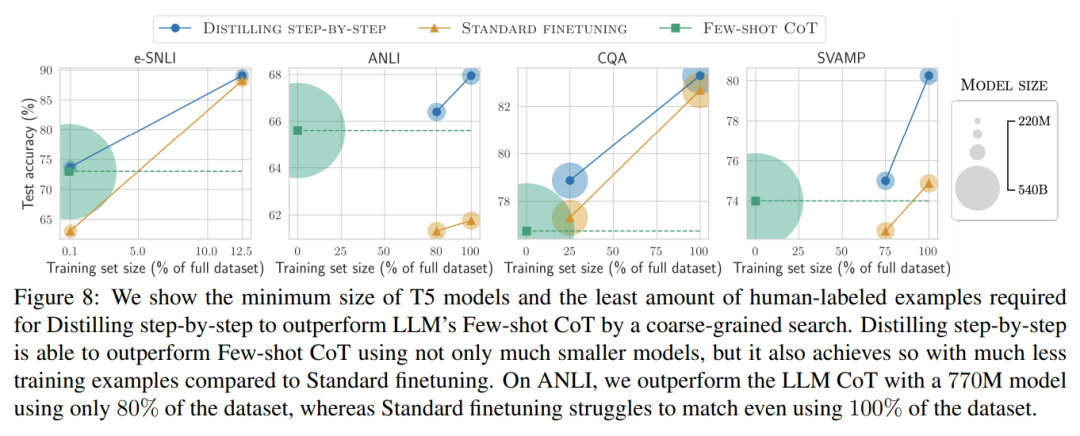
以上是蒸餾也能Step-by-Step:新方法讓小模型也能媲美2000倍體量大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















