


特斯拉的攝影機視野可以覆蓋車身周圍360°,在前向有120°魚眼、長焦鏡頭用於加強觀測,佈局如上圖。

#特斯拉採用的是36Hz的1280*960-12bit的圖像原始數據,這相對於只有8-bit的ISP後處理數據多了4位信息,動態方位擴大了16倍。特斯拉這樣處理的原因有2個:
1) ISP基於rule-base的演算法對原始訊號做了自動對焦(AF)、自動曝光(AE)、自動白平衡(AWB)、壞點校正(DNS)、高動態範圍成像(HDR)、色彩校正(CCM)等,這些滿足於人眼可視化需求,但不一定是自動駕駛的需要。相對於rule-base的ISP,神經網路的處理能力更為強大,能夠更好的利用影像的原始訊息,同時避免ISP帶來的資料損失。
2) ISP的存在不利於資料的高速傳輸,影響影像的幀率。而將原始訊號的處理放在網路運算中,速度快很多。
這種方式跨越了傳統類似ISP的專業知識,直接從後端需求驅動網路學習更強的ISP能力,可以強化系統在低光照、低可見度條件下超越人眼的感知能力。基於這個原理Lidar、radar的原始資料用於網路擬合應該也是更好的方式。
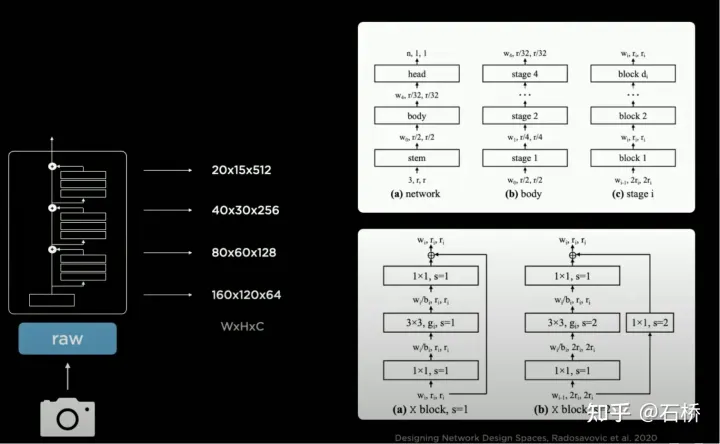
RegNet
#特斯拉採用的是RegNet,相較於ResNet進行了更高一層的抽象,解決了NAS搜尋設計空間(將卷積、池化等模組:連接組合/訓練評估/選最優)固定、無法創建新模組的弊端,可以創建新穎的設計空間範式,能夠發掘更多的場景適配新的"ResNet",從而避免專門去研究設計神經網路架構。如果出來更好的BackBone可以替換這部分。
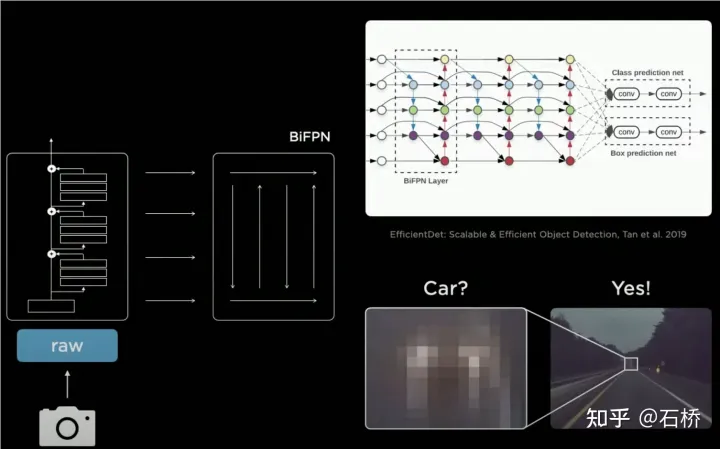
BiFPN

FPN->BiFPN

#2D感知
在BEV出現之前,自動駕駛感知主流方案都是基於相機的2D Image Space,但是感知的下游應用方-決策和路徑規劃都是在車輛所在的2D BEV Space進行的,感知與規控之間的壁壘阻礙了FSD的發展。為了消除這個壁壘,就需要將感知從2D影像空間後置到2D的自車參考系空間,也就是BEV空間。
基於傳統技術:
#會採用IPM(Inverse Perspective Mapping)假設地面為平面利用相機-自車外參將2D Image Space轉換為2D的自車空間,即BEV鳥瞰空間。這裡有個很明顯的缺陷:平面假設在面對道路起伏和上下坡時並不在成立。
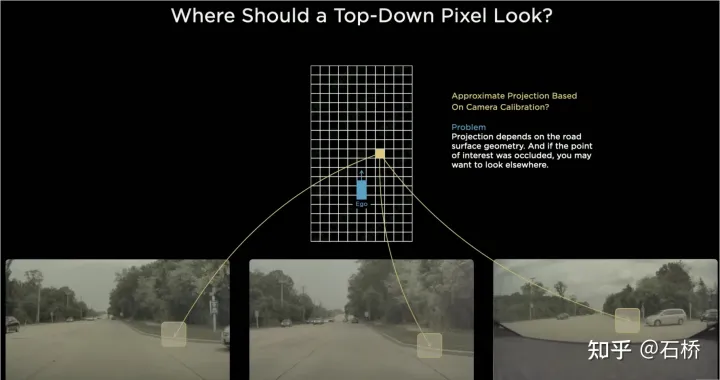
多相機接邊拼接問題
##由於每個相機的FOV有限,所以即使使用IPM將2D Image Space轉換到2D BEV空間還需要解決多個相機影像的BEV空間拼接。這其實需要高精度的多相機標定演算法,而且需要線上的即時校正演算法。總結來說,需要實現的就是將多相機2D影像空間特徵映射到BEV空間,同時解決由於標定和非平面假設引起的變換重疊問題。
Tesla基於Transformer的BEV Layer的實作方案:
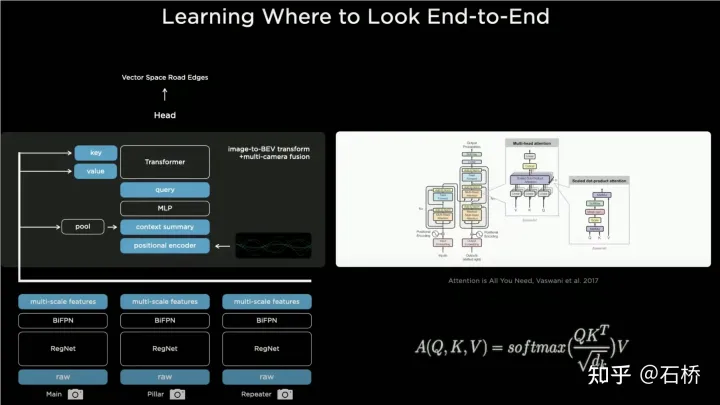
##BEV_FUSION
首先在各台相機分別透過CNN主幹網路和BiFPN擷取多尺度特徵圖層,多尺度特徵圖層一方面透過MLP層產生Transformer的方法中所需的Key和Value,另一方面對多尺度Feature Map進行Global Pooling操作得到一個全域描述向量(即圖中的Context Summary),同時透過對目標輸出BEV空間進行柵格化,再對每個BEV柵格進行位置編碼,將這些位置編碼與全域描述向量進行拼接(Concatenate)後再透過一層MLP層得到Transformer所需的Query。在Cross Attention操作中,Query的尺度決定最終BEV層之後的輸出尺度(即BEV柵格的尺度),而Key和Value分別處於2D影像座標空間下,依照Transformer的原理,透過Query和Key建立每個BEV柵格收到2D影像平面像素的影響權重,從而建立從BEV到輸入影像之間的關聯,再利用這些權重加權由影像平面下的特徵得到的Value,最終得到BEV座標系下的Feature Map,完成BEV座標轉換層的使命,後面就可以基於BEV下的Feature Map利用已經成熟的各個感知功能頭來直接在BEV空間下進行感知了。 BEV空間下的感知結果與決策規劃所在的座標係是統一的,因此感知與後續模組就透過BEV變換緊密地連結到了一起。

Calibration
#透過這個方法,實際上相機外參以及地面幾何形狀的變化都在訓練過程中被神經網路模型內化在參數裡邊。這裡存在的一個問題就是使用同一套模型參數的不同車子的相機外參存在微小的差異,Karparthy在AI Day上補充了一個Tesla應對外參差異的方法:他們利用標定出來的外參將每輛車採集到的影像通過去畸變,旋轉,恢復畸變的辦法統一轉換到同樣一套虛擬標準相機的佈設位置,從而消除了不同車相機外參的微小差別。
#
BEV的方法是一個非常有效的多相機融合框架,透過BEV的方案,原本很難進行正確關聯的跨多個相機的近處的大目標的尺寸估計和追蹤都變得更加準確、穩定,同時這種方案也使得演算法對於某一個或幾個相機短時間的遮擋,丟失有了更強的魯棒性。簡而言之,BEV解決了多相機的影像融合拼接,增加了穩健性。

解決了多相機的車道線和邊界融合

障礙物變的更穩定
#(從PPT來看,特斯拉初始的方案應該是主要應用了前向相機來做感知和車道線預測的。)
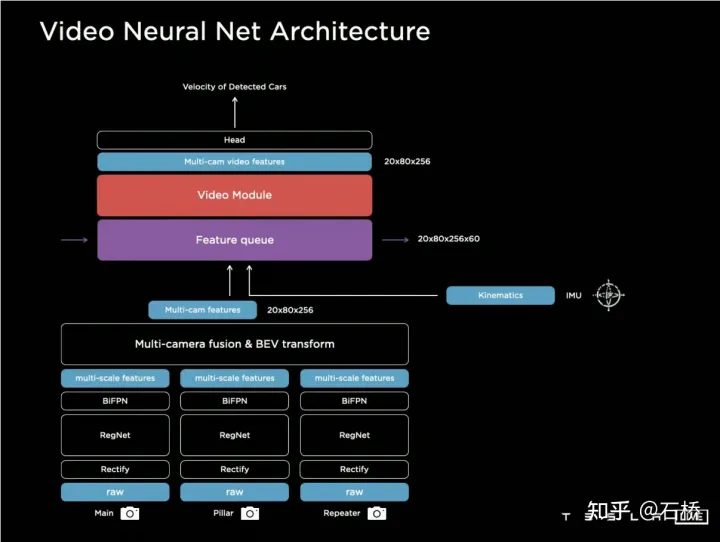
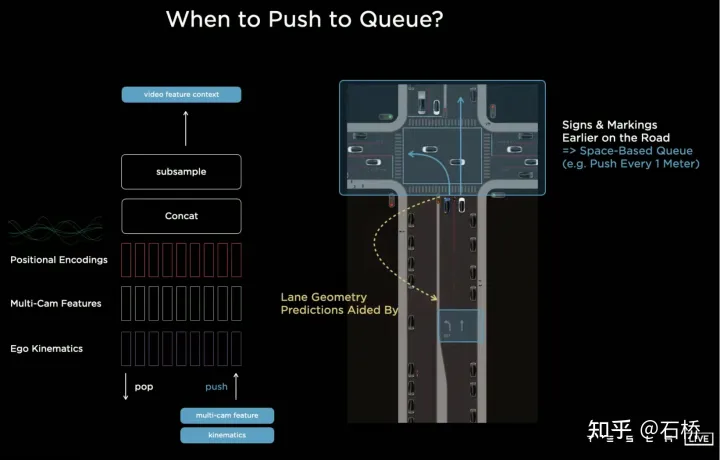
BEV的使用將感知從多相機分散的2D Image Space提升到2D的BEV 空間,但是自動駕駛實際的環境是一個4D的空間的問題,即便不考慮高程,仍缺少的一個維度是時間。 Tesla透過使用具有時序資訊的視訊片段替代圖像對神經網路進行訓練,從而使感知模型具有短時間的記憶的能力,實現這個功能的方法是分別引入時間維度和空間維度上的特徵隊列進入神經網路模型。規則:每隔27毫秒push queue或每走過每隔1公尺遠就會連同運動訊息緩存在影片序列。

對於如何融合時序訊息,Tesla嘗試了三種主流的方案:3D卷積,Transformer以及RNN。這三種方法都需要把自車運動信息與單幀感知結合起來,Karparthy表示自車運動信息只使用了包括速度和加速度的四維信息,這些運動信息可以從IMU中獲取,然後與BEV空間下的Feature Map(20x80x256)還有Positional Encoding結合(Concatenate),形成20x80x300x12維的特徵向量隊列,這裡第三維由256維視覺特徵4維運動學特徵(vx, vy, ax, ay)以及40維位置編碼(Positional Encoding)構成,因此300 = 256 4 40,最後一維是降採樣過後的12幀時間/空間維度。
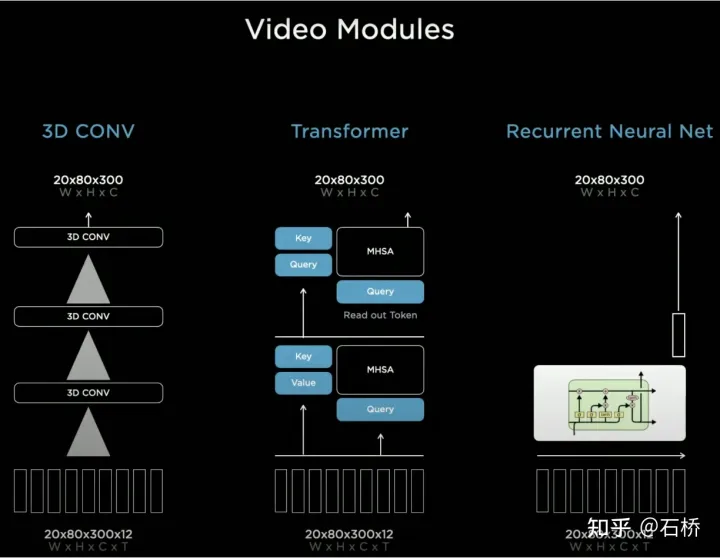
3D Conv, Transformer,RNN都能處理序列訊息,三者在不同任務上各有長短,但大部分時間採用哪個方案其實差別不大,然而AI Day上Karparthy另外分享了一個簡單有效,而且效果十分有趣可解釋的方案叫做Spatial RNN。與上面三個方法有所不同,Spatial RNN由於RNN原本就是串行處理序列訊息,幀間前後順序得以保留,因此無需將BEV視覺特徵進行位置編碼就可以直接給進RNN網絡,因此可以看到這裡輸入資訊就只包含20x80x256的BEV視覺Feature Map和1x1x4的自車運動資訊。

Spatial特徵在CNN中常指圖像平面上的寬高維度上的特徵,這裡Spatial RNN中的Spatial則指的是類似以某時刻的BEV座標為基準的一個局部座標系裡的兩個維度。這裡為了進行說明使用了LSTM的RNN層,LSTM的優勢在於其可解釋性強,這裡作為例子進行理解再合適不過了。
LSTM特徵在於Hidden State裡面可以保留前面長度可變的N個時刻的狀態的編碼(也即短時記憶),然後當下時刻可以透過輸入和Hidden State決定哪一部分記憶的狀態需要被使用,哪一部分需要被遺忘等等。在Spatial RNN中,Hidden State是一個比BEV柵格空間更大的矩形柵格區域,尺寸為(WxHxC)(見上圖,WxH大於20x80的BEV尺寸),自車運動學資訊決定前後BEV特徵分別影響的是Hidden State的哪一部分柵格,這樣連續的BEV資料就會持續對Hidden State的大矩形區域進行更新,且每次更新的位置與自車運動相符。經過連續的更新後,就形成了一個類似局部地圖一樣的Hidden State Feature Map如下圖所示。

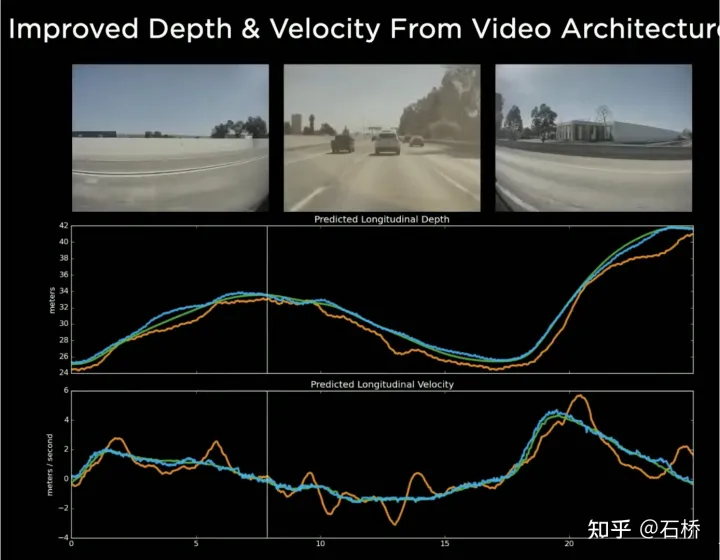
時序隊列的使用賦予了神經網路獲得幀間連續的感知結果的能力,與BEV結合後則使FSD獲得了應對視野盲區和遮擋,選擇性地對局部地圖進行讀寫的能力,正因為有了這樣的實時的局部地圖構建的能力,FSD才能不依賴高精地圖進行城市中的自動駕駛。這裡具備不只是3D的地圖能力,其實是局部4D場景建構能力,可用於預測等。在Occupancy出來後,普遍認為基於Spatial RNN改為上述中的transformer方案。

BEV的2D鳥瞰圖很顯然與真實自動駕駛面臨的3D場景還有差距,所以必然存在某些場景下BEV2D感知失效的情況。在2021年特斯拉就具備了深度構建的能力,所以從2D走向3D只是時間問題,2022年就帶來了Occupancy Network,它是BEV網絡在高度方向進行了進一步的擴展,將BEV坐標系下2D柵格位置編碼產生的Query升級為3D柵格位置編碼產生的Query,以Occupancy Feature取代了BEV Feature。
在CVPR2022上,Ashork給出了使用Occupancy Feature而不使用基於影像深度估計的原因:

1)深度估計近處是OK的,但是遠處深度就不一致,遠處越靠近地面的地方深度值點越少(這是受限於影像的成像原理導致的,在20m外一個像素所代表的縱向距離可能超過了30cm),而且資料難以被後續規劃流程所使用。
2)深度網路基於回歸構建,很難透過遮蔽來進行預測,所以邊界上難以進行預測,可能平滑的從車輛過渡到背景。
使用Occupancy的優點如下:
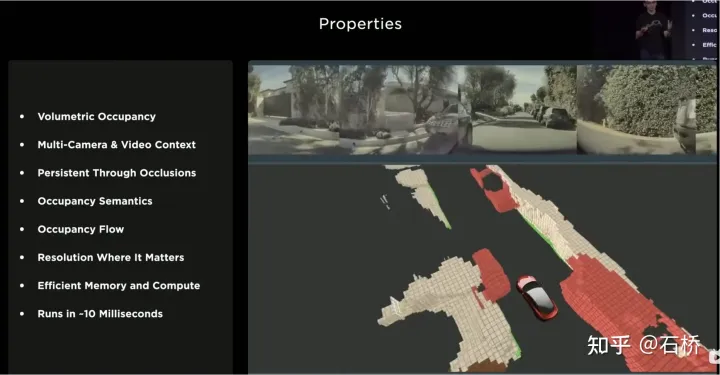
Occupancy優點
#1)在BEV空間生成了統一的體素,可以預測任意一個體素的佔用機率
2)獲取了所有相機的視頻流,並且是統一的(沒有lidar-camera融合的問題,資訊的維度比lidar也要高)
3)能夠即時預測被遮擋物體的狀態(Occupancy的動態描述能力是從3D到4D過渡)
4)可以為每個體素產生對應的語意類別(影像的辨識能力是遠強於lidar)

即使不辨識類別也能處理運動物件
5)可以為每個體素預測其運動狀態,對隨機運動進行建模
6)各個位置的分別率是可以調整的(也就是具備BEV空間變焦能力)
7)得益於特斯拉的硬件,Occupancy具有高效的儲存與運算優勢
8 )10ms內可以完成計算,處理頻率可以很高(36Hz的圖像輸出能力已經強於10Hz的lidar頻率)
Occupancy的方案相比於bounding box的感知方案優點在於:
可以描述不具有固定bounding box,可以隨意變換形態,任意移動的未知類別物體,將障礙物的描述粒度從box提升到了voxel粒度,可以解決感知中很多的長尾問題。
來看下Occupancy整體方案:

Occupancy Network
1)Image Input:輸入原始影像訊息,擴大了資料維度和動態範圍
2)Image Featurers: RegNet BiFPN提取多尺度的圖像特徵
3)Spatial Atention:透過帶有3D空間位置的spatial query對2D圖像特徵進行基於attention的多相機融合
實現方案1:根據每台相機的內外參將3D spatial query投影到2D特徵圖上,提取對應位置的特徵。
實作方案2:利用positional embedding來進行隱式的映射,即將2D特徵圖的每個位置加上合理的positional embedding,如相機內外參、像素座標等,然後讓模型自己學習2D到3D特徵的對應關係
4)Temporal Alignment:利用軌跡資訊對每個frame的3D Occupancy Features按照時序進行空間上Channel維度的拼接,隨著時間遠近有一個權重的衰減,組合特徵會進入Deconvolutions的模組來提高分辨率
5)Volume Outputs:輸出固定大小柵格的佔用率和占用流
6)Queryable Outputs:設計了一個隱式queryable MLP decoder,輸入任意座標值(x,y,z),用於取得更高解析度的連續體素語意、佔用率、佔用流信息,打破了模型分辨率的限制
7)生成具有三維幾何和語義的可行駛區域路面,有利於坡度、彎曲道路上的控制。

地與Occupancy是一致的
8)NeRF state: nerf建構的是場景的幾何結構,可以產生任意視角的影像,可以恢復高解析度的真實場景。
如果能夠用Nerf進行升級或替換,那麼將具備還原真實場景的能力,而這個場景還原能力將是過去-現在-未來的。對於特斯拉技術方案追求的4D場景自動駕駛應該是極大的補充和完善。
只分割、辨識出車道線是不夠的,還需要推理取得車道之間的拓樸連結關係,這樣才能用於軌跡規劃。
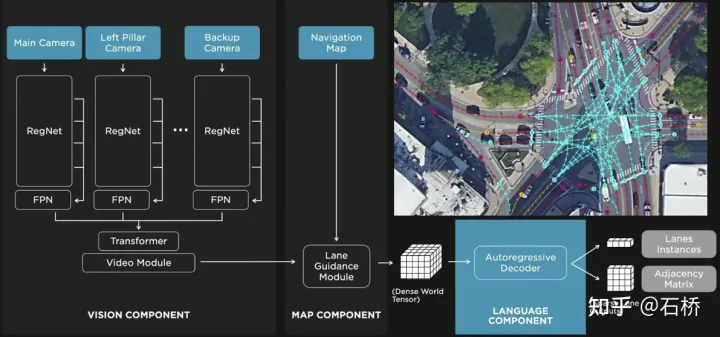
FSD車道線拓樸關係感知
#1)Lane Guidance Module:使用了導航圖中的道路的幾何&拓撲關係,車道等級、數量、寬度、屬性信息,將這些信息與Occupancy特徵整合起來進行編碼生成Dense World Tensor給到拓樸關係建立的模組,將視訊流稠密的特徵通序列產生範式解析出稀疏的道路拓樸資訊(車道節點lane segment和連接關係adjacent)。
2)Language Component:把車道相關資訊包含車道節點位置、屬性(起點,中間點,終點等)、分叉點、匯合點,以及車道樣條曲線幾何參數進行編碼,做成類似語言模型中單字token的編碼,然後利用時序處理方法處理。具體流程如下:

language of lanes 流程

language of lanes
#最終language of lanes表徵的就是圖中的拓樸連結關係。

障礙物感知與預測
FSD的Object Perception是一個2-Step的方法,第1階段先從Occupancy中辨識出障礙物在3D空間中的位置,第2階段將這些3D物體的張量concat一些運動學資訊的編碼(如自車運動,目標行駛車道線,交通燈交通信號等)然後在接入軌跡預測、物體建模、行人位姿預測等head。將複雜的感知Heads聚焦在有限的ROI區域,減少了處理延遲。從上圖可以看到有2步video module,分別服務自車和它車的預測。
這裡留下個疑問:上圖的2次video module有什麼差別?效率上會不會有問題?
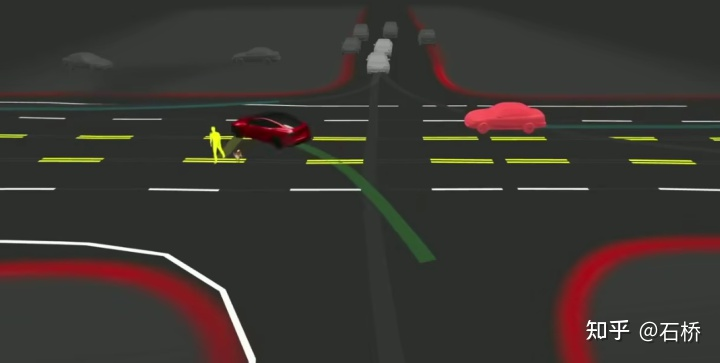
路口無保護左轉的決策規劃場景
上述這個場景決策規劃的困難在於:
自車執行無保護左轉通過路口場景過程中需要與行人、正常直行車輛交互,理解多方的相互關係。
與前者的互動決策,直接影響與後者的互動策略。這裡最後選擇的方案是:盡量不干擾其他交通參與者的運動。


決策規劃的流程
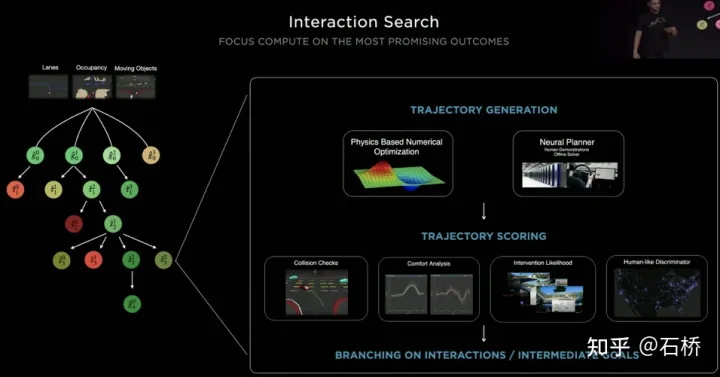
#Tesla實現這個目標採用的是“交互搜尋”,對一系列可能的運動軌跡進行並行搜索,對應的狀態空間包含了自車、障礙物、可行駛區域、車道、交通號誌等。解空間採用的是一組目標運動候選軌跡,在與其他交通參與互動決策後產生分支,進而遞進決策規劃下去,最後選出最優的軌跡,流程如上圖所示:
#1) 根據道路拓樸或人駕資料先驗得到goal點或其機率分佈(大數據軌跡)
2)依據goal點產生候選軌跡(優化演算法神經網路)
3)沿著候選軌跡rollout並互動決策,重新規劃路徑,評估各個路徑的風險和得分,優先搜尋最佳路徑知道goal點
整個決策規劃的最佳化表達式:

#決策計畫最佳化表達式
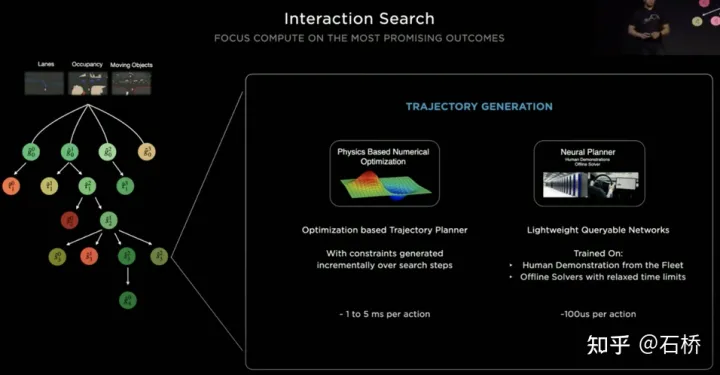
「輕量級的規劃軌跡查詢網路
特斯拉採用遞增的方式不斷加入新的決策約束,以較少約束下最優方案作為初值繼續求解更複雜的最佳化問題,最終得到最優解。但由於有眾多的可能分支,就要整個決策規劃過程要十分的高效,採用基於傳統優化演算法的planner每次決策規劃需要耗時1~5ms,當存在高密度交通參與者時顯然是不夠安全的。特斯拉採用的Neural Planner是一個輕量級的網絡,查詢的規劃軌跡使用Tesla車隊中人類駕駛員駕駛數據和在無時間約束的離線條件下規劃的全局最優路徑最為真值進行訓練出來的,每次決策規劃只有100us。
#規劃決策評估
#每次決策後查詢到的多個候選軌跡都需要進行評估,評估依據的規範有碰撞檢查、舒適性分析、接管可能性、與人的相似程度等,有助於修剪搜素分支,避免整個決策樹過於龐大,同時也能夠將算力集中到最有可能的分支。 Tesla強調方案同樣適用於遮蔽場景,在規劃過程會考慮被遮蔽的物體的運動狀態,透過加入「鬼影」來規劃。

ghost遮蔽場景
#在CVPR也分享了碰撞規避的網路流程和對應的規劃過程,不細述。
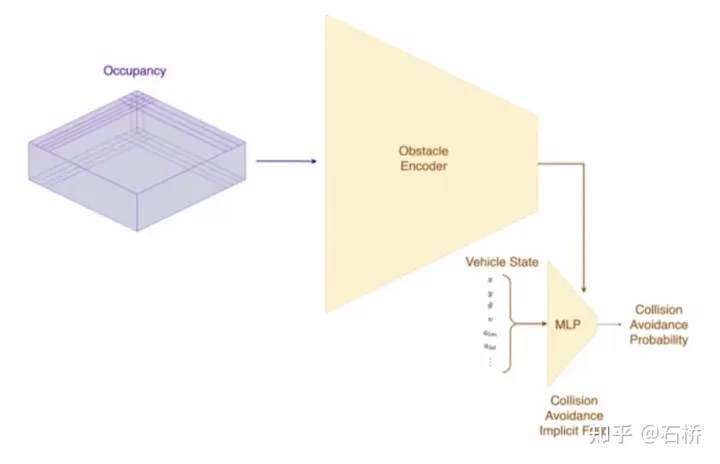
碰撞規避網路


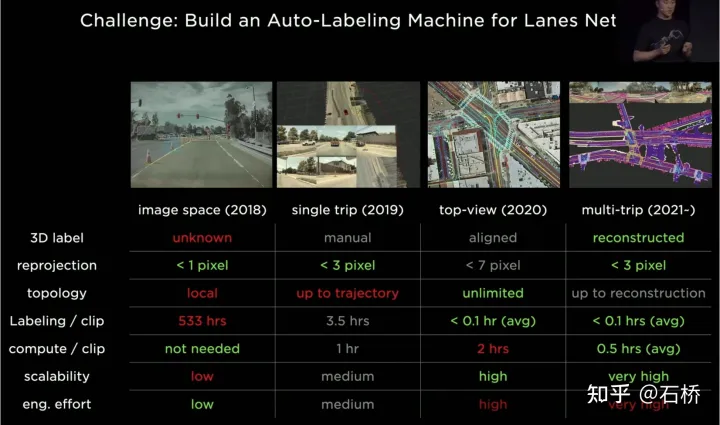
##03 場景重建&自動標註特斯拉強大的感知能力需要強大的標註能力作為支撐,從2018至今,特斯拉的標註經歷了4個階段:
##特斯拉的標註迭代
第1階段(2018):只有純人工的2維的影像標註,效率非常低
第2階段(2019):開始有3D label,但是是單趟的人工的
第3階段(2020):採用BEV空間進行標註,重投影的精度明顯降低
第4階段(2021):採用多趟重建去進行標註,精度、效率、拓樸關係都達到了極高的水準

 自動標註系統
自動標註系統
第1步:VIO產生高精軌跡。將視訊串流、IMU、里程計給神經網絡,推理提取點、線、地面、分割特徵,然後在BEV空間用multi-camera VIO進行tracking和optimization,輸出100Hz的6dof的軌跡和3dof的結構和道路,同時還可以輸出camera的標定值。重建軌跡的精確度是1.3cm/m、0.45弧度/m,不算很高。所有的FSD都可以運作這套流程來取得某趟預處理的軌跡和結構資訊。 (看影片感覺vio只明確用了點特徵,可能隱式使用了用線、面特徵。)
 多趟軌跡重建
多趟軌跡重建
第2步:多趟軌跡重建。將多趟來自不同車輛的重建資料進行軌跡分組粗對齊->特徵匹配->聯合優化->路面精修,然後人工參與進來最終核實確認標註結果。這裡聯合優化後也進行了一個路面優化,猜測是視覺重建的誤差比較大,全局優化後在局部道路存在分層重疊問題,為了消除這部分全局優化錯誤分配的誤差,增加了路面優化。從演算法邏輯來講,全域最佳化後接局部最佳化是一個必須項,因為自動駕駛的要求是處處能可行駛。整個過程在集群上並行的。
###################粗對##########第3步:自動標註新軌跡資料。在預先建構的地圖上,對新行航軌跡資料執行多趟軌跡重建一樣的重建流程,這樣對齊後的新軌跡資料就可以自動的從預先建置地圖上取得語意標註。這其實就是一個重定位取得語意標籤的過程。這個自動標註其實是只能自動標註靜態的物體,例如:車道線、道路邊界等。透過感知模型,其實已經能夠獲取到車道線等的語意類別,但是在惡劣場景下會存在完整性和誤識別問題,透過這個自動標註可以解決這些問題。但缺陷在於對於動態障礙物可能就不太適用了,例如:行駛中的車輛、行人等。以下是使用場景:

自動標註使用場景
#特斯拉所展示的許多影像都有一個特點:存在模糊或污漬遮擋,但是不嚴重影響其感知結果。在正常的使用中,車輛的相機鏡頭很容易被弄髒,但是有了這個自動標註,特斯拉的感知穩健性會非常強,也降低了相機的維護成本。
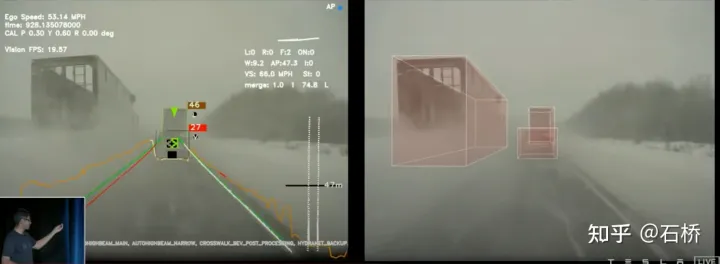
自動標註不適用於動態車輛
回顧2021年的ai day可知上述重建建構的是static world,而是不只是車道線車道線,還有車輛和建築。

#3D重建

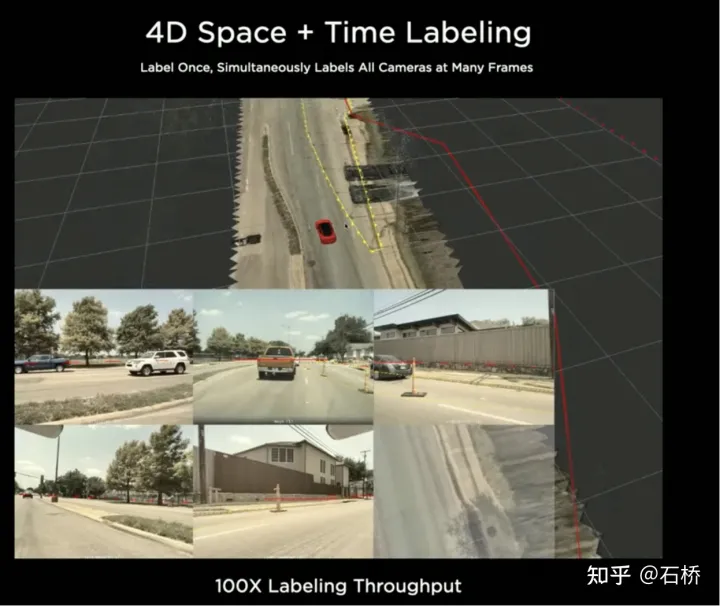
#重建靜態世界並標註
#4D空間標註
 在BEV空間標示完後,會將標註再映射會多台相機的影像中,從而實現4D空間一次標註可以2D多幀應用。
在BEV空間標示完後,會將標註再映射會多台相機的影像中,從而實現4D空間一次標註可以2D多幀應用。
關於場景重建,目前的重建能力和精準度可能還是沒有達到特斯拉工程師的期望,他們最終的目標是真實還原重建出所有特斯拉汽車行駛過的場景,而且可以真實的改變這些場景的條件產生新的真實場景,這才是終局目標。

#還原真實世界

##重建真實世界
 04 場景模擬:基於真實道路訊息,創造自動駕駛場景
04 場景模擬:基於真實道路訊息,創造自動駕駛場景
###場景模擬###########################模擬可以取得絕對正確的label#########
基於重建去建構的真實場景受限於資料、演算法等,目前還難以大規模實現,而且耗時還比較長,例如:上圖一個真實路口的模擬需要花費2週時間。但是自動駕駛的落地又依賴在不同場景中的訓練和測試,所以特斯拉就建構了一套模擬系統,用於模擬自動駕駛場景。這套系統並不能真實模擬現實場景,但好處是比上述真實常見重建方案快1000倍,可以提供現實中難以獲得或難以標記的數據,對於自動駕駛的訓練仍然非常有意義。
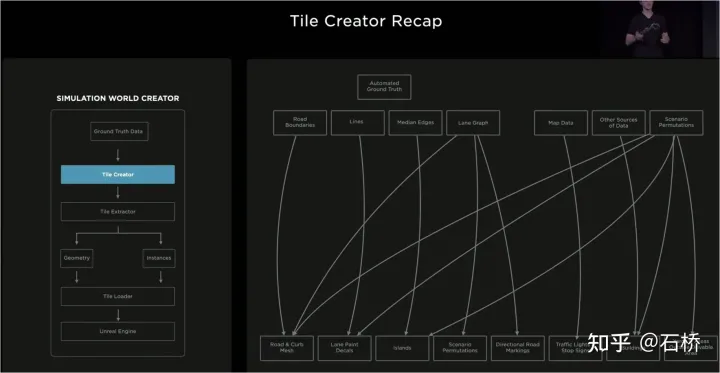
模擬所建構的架構
#這套模擬器的架構如上圖,在場景建立過程中需要經過以下步驟:
第1步:在模擬世界中鋪開道路,利用邊界label產生實體路面mesh,用道路拓樸關係重新關聯.
第2步:將路面上的車道線和幾何描述要素投影到車道路段上,建構車道細節
第3步:在道路中間邊界區域內生成中心分道區,隨機生成植物、交通標識填補;道路邊界外採用隨機啟發的方式生成一系列的建築、樹木、交通標識物等
#第4步:從地圖中取得紅綠燈或停止標誌的位置,還可以獲得車道數、道路名稱等
第5步:使用車道地圖取得車道的拓樸關係,產生行駛方向(左右轉標線)和輔助標記
第6步:利用車道地圖本身確定車道相鄰關係和其他有用的信息
第7步:根據車道關係產生隨機車流組合
在上述過程中,基於一套車道導航地圖真值可以修改模擬參數產生變化,產生多種組合場景。而且甚至可以根據訓練的需要,修改真值的某些屬性,創造新的場景,從而達到訓練目的。

資料分割為Tile儲存

基於Tile粒度構建的世界
上述建構的模擬是基於真實的道路信息,所以很多現實性的問題就可以藉助模擬來解決。例如:可以在模擬的洛杉磯道路環境中測試自動駕駛功能。 (上述的儲存方式就是在模擬建圖、儲存、載入使用)
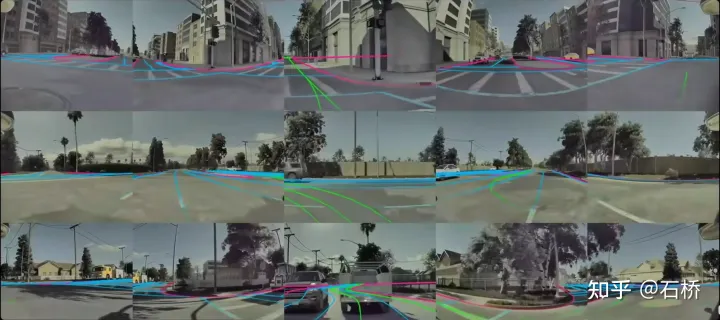
模擬場景下的自動駕駛
#感受:對於自動駕駛來說什麼樣的地圖資訊是不可被取代的可以從這個模擬建構過程中找到一些答案。
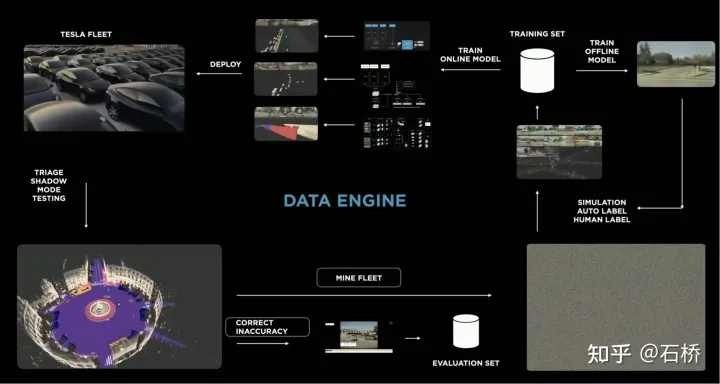
資料閉迴路流程
資料引擎從影子模式中挖掘模型誤判的數據,將之召回並採用自動標註工具進行標籤修正,然後加入到訓練和測試集中,可以不斷的優化網路。這個過程是資料閉環的關鍵節點,會持續產生corner case樣本資料。
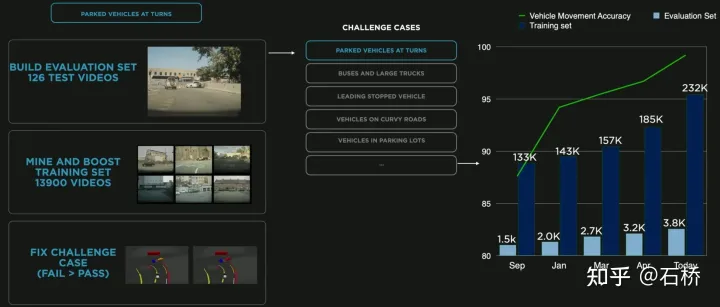
Data Mining for Curved Parking
The picture above shows the improvement of the model through data mining for curved parking In this case, as data is continuously added to the training, the accuracy index continues to improve.
以上是深度剖析Tesla自動駕駛技術方案的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















