

現在,已是2022年底。
深度學習模型在生成影像上的表現,已經如此出色。很顯然,它在未來會給我們更多的驚喜。

十年來,我們是如何走到今天這一步的?
在下面的時間軸裡,我們會追溯一些里程碑式的時刻,也就是那些影響了AI圖像合成的論文、架構、模型、資料集、實驗登場的時候。
一切,都要從十年前的夏天說起。
深度神經網路問世之後,人們意識到:它將徹底改變影像分類。
同時,研究人員開始探索相反的方向,如果使用一些對分類非常有效的技術(例如卷積層)來製作圖像,會發生什麼?
這就是「人工智慧之夏」誕生的伊始。
2012 年 12 月
一切發端於此。
這一年,論文《深度卷積神經網路的ImageNet分類》橫空出世。

論文作者之一,就是「AI三巨頭」之一的Hinton。
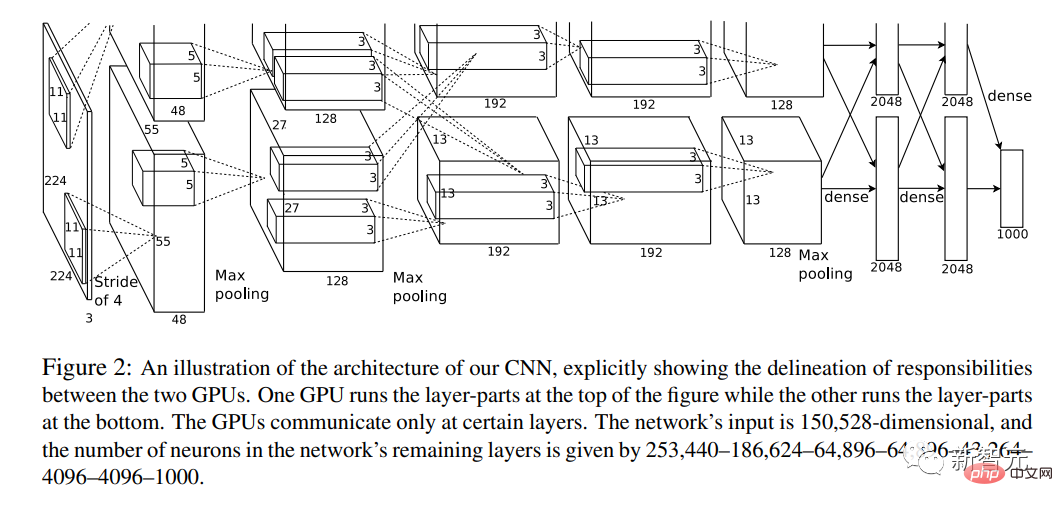
它首次將深度卷積神經網路 (CNN)、GPU和龐大的網路來源資料集(ImageNet)結合在一起。

2014 年12 月
Ian Goodfellow等AI巨佬發表了史詩性論文鉅作《生成式對抗網絡》。
GAN是第一個致力於影像合成而非分析的現代神經網路架構(「現代」的定義即2012年後)。
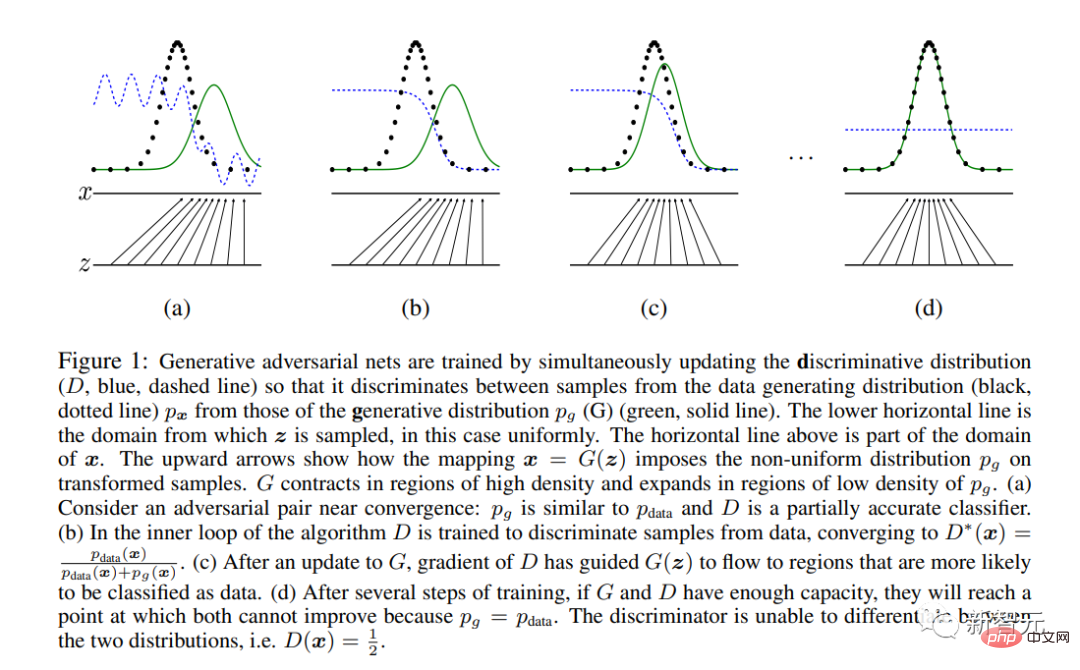
它引入了一種基於賽局理論的獨特學習方法,由兩個子網路「生成器」和「鑑別器」進行競爭。
最終,只有「生成器」被保留在系統之外,並用於影像合成。
Hello World!來自Goodfellow等人2014年論文的GAN生成人臉樣本。該模型是在Toronto Faces資料集上訓練的,該資料集已從網路上刪除
#2015 年11 月
#具有重大意義的論文《使用深度卷積生成對抗網路進行無監督代表學習》發表。

在這篇論文中,作者描述了第一個實際可用的GAN 架構 (DCGAN)。
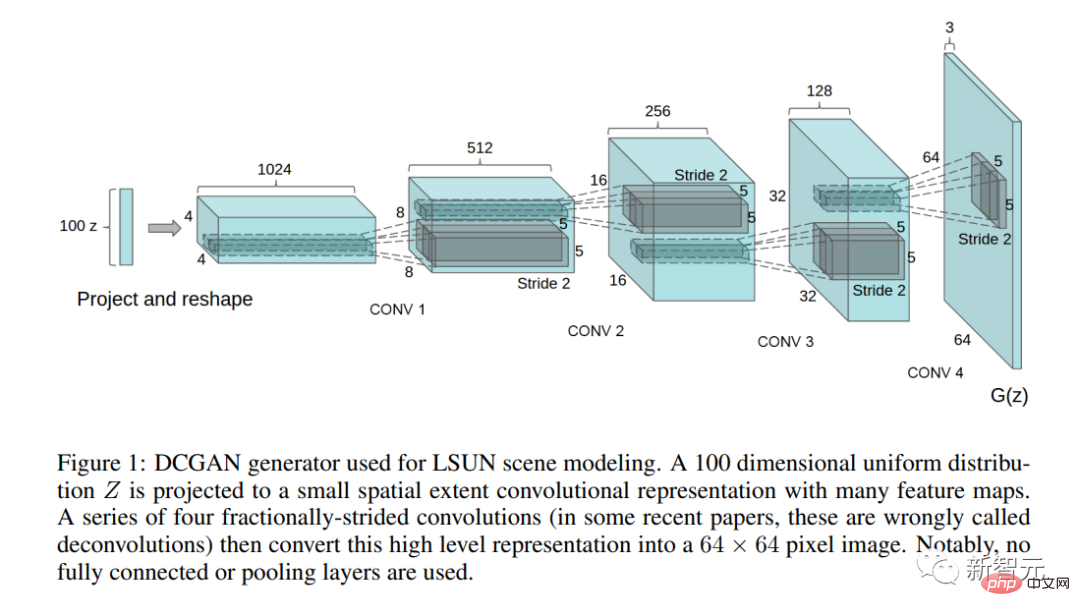
這篇論文也首次提出了潛在空間操弄的問題──概念是否映射到潛在空間方向?
#這五年間,GAN被應用於各種影像處理任務,例如風格轉換、修復、去噪和超解析度。
期間,GAN架構的論文開始爆炸式井噴。

#專案網址:https://github.com/nightrome/really-awesome-gan
同時,GAN的藝術實驗開始興起,Mike Tyka、Mario Klingenmann、Anna Ridler、Helena Sarin 等人的第一批作品出現。
第一個「AI 藝術」醜聞發生在2018年。三位法國學生使用「借來」的程式碼產生一副AI肖像,這副肖像成為第一幅在佳士得被拍賣的AI畫像。

同時,transformer架構徹底改變了NLP。
在不久的將來,這件事會對影像合成產生重大影響。
2017 年 6 月
《Attention Is All You Need》論文發布。

在《Transformers, Explained: Understand the Model Behind GPT-3, BERT, and T5》裡,也有詳實的解釋。
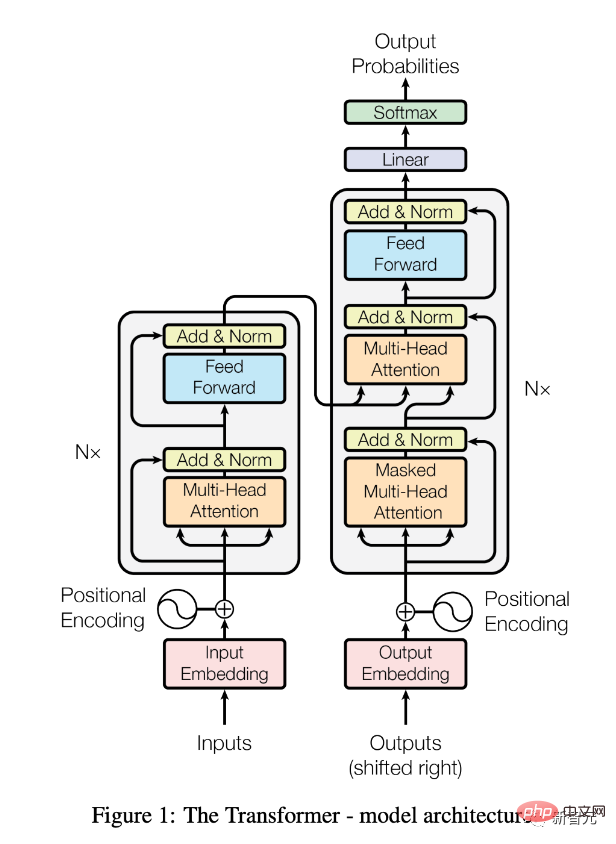
自此,Transformer架構(以BERT等預訓練模型的形式)徹底改變了自然語言處理 (NLP) 領域。

2018 年7 月

《概念性標註:用於自動圖像字幕的清理、上位化、圖像替代文字資料集》論文發表。
這個和其他多模態資料集對於 CLIP 和 DALL-E 等模型將變得極為重要。
2018-20年
#NVIDIA的研究人員對GAN 架構進行了一系列徹底改進。
在《使用有限資料訓練生成對抗網路》這篇論文中,介紹了最新的StyleGAN2-ada。

GAN 產生的影像第一次變得與自然影像無法區分,至少對於像Flickr-Faces-HQ (FFHQ)這樣高度最佳化的資料集來說是這樣。

Mario Klingenmann, Memories of Passerby I, 2018. The baconesque faces是該地區AI藝術的典型代表,其中生成模型的非寫實性是藝術探索的重點
2020 年5 月
##論文《語言模型是小樣本學習者》發表。
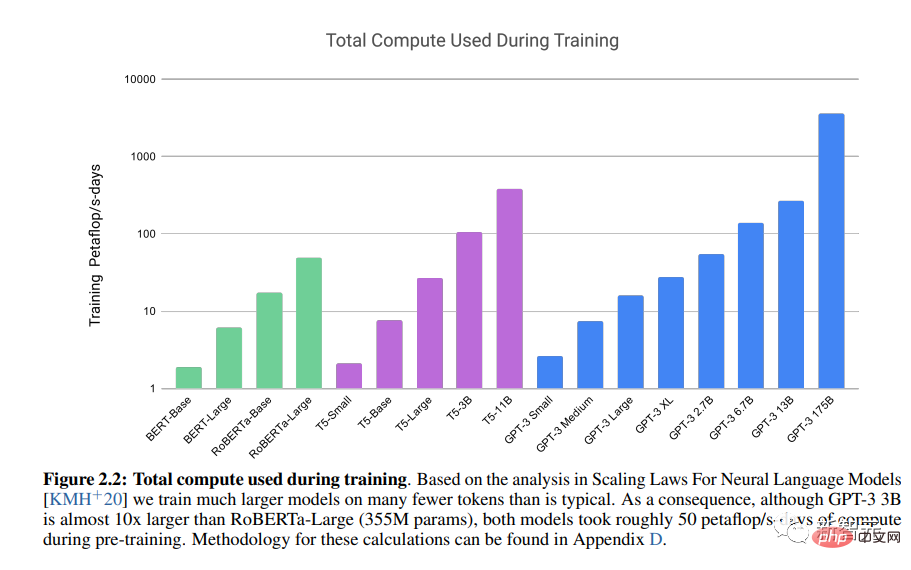
OpenAI的LLM Generative Pre-trained Transformer 3(GPT-3)展示了變壓器架構的強大功能。
2020 年12 月
論文《用於高解析度影像合成的Taming transformers》發表。

ViT表明,Transformer架構可用於映像。
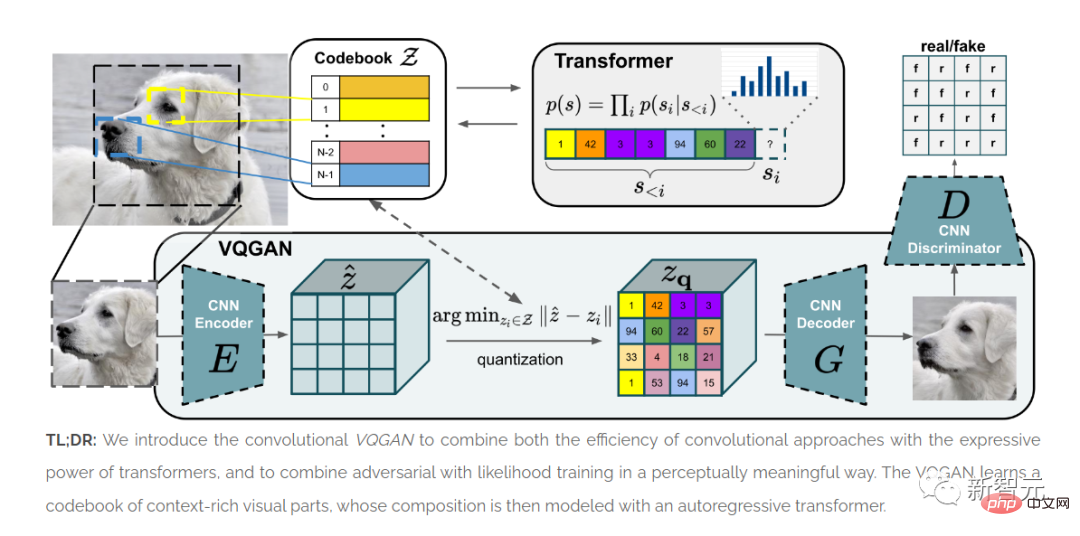
本文介紹的方法VQGAN在基準測試中產生了SOTA結果。
2010年代後期的GAN架構的品質主要根據對齊的臉部影像進行評估,對於更多異質資料集的效果很有限。
因此,在學術/工業和藝術實驗中,人臉仍然是一個重要的參考點。
Transformer的時代(2020-2022)#Transformer架構的出現,徹底改寫了影像合成的歷史。
從此,影像合成領域開始拋下GAN。
「多模態」深度學習整合了NLP和電腦視覺的技術,「即時工程」取代了模型訓練和調整,成為影像合成的藝術方法。
《從自然語言監督中學習可遷移視覺模型》這篇論文中,提出了CLIP 架構。

可以說,目前的影像合成熱潮,是由CLIP首次引入的多模態功能所推動的。
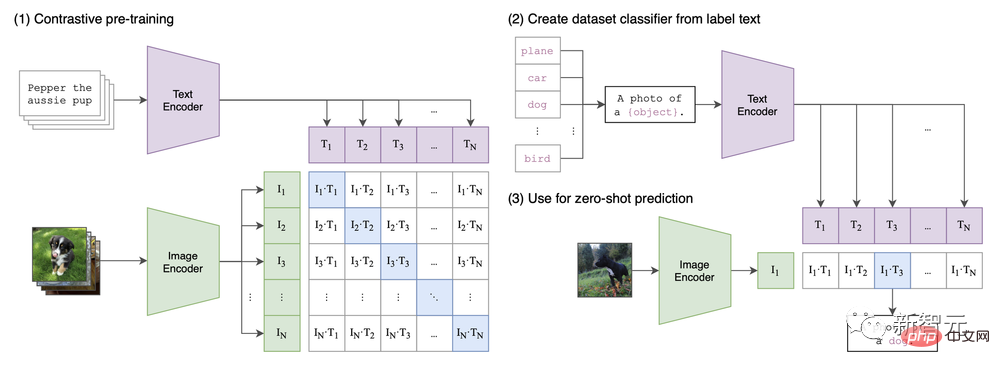
論文中的CLIP架構

論文《零樣本文字到圖像生成》發表(另請參閱OpenAI 的部落格文章),其中介紹了即將轟動全世界的DALL-E的第一個版本。
這個版本透過將文字和圖像(由VAE壓縮為「TOKEN」)組合在單一資料流中來運作。
該模型只是「continues」the“sentence”。
資料(250M 圖片)包括來自維基百科的文字圖像對、概念說明和YFCM100M的篩選子集。
CLIP為影像合成的「多模態」方法奠定了基礎。
2021 年1 月
論文《從自然語言監督學習可遷移視覺模型》發表。

論文中介紹了CLIP,結合了ViT和普通Transformer的多模態模型。
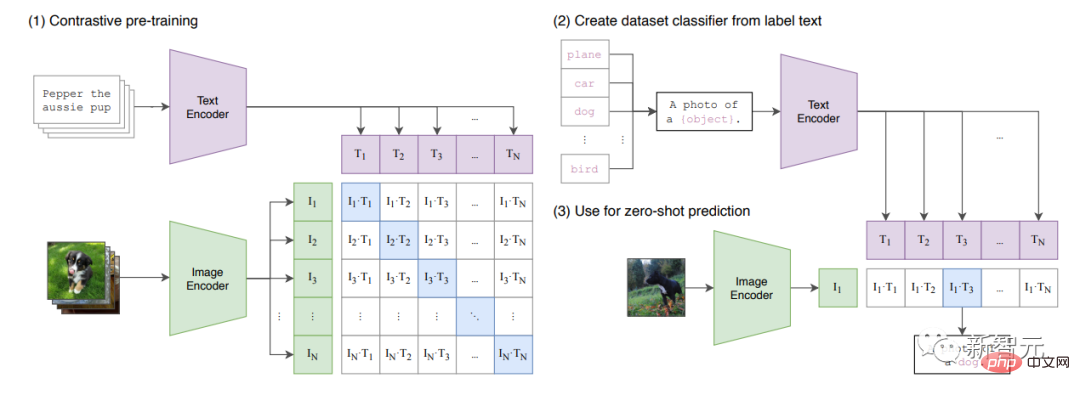
CLIP會學習圖像和標題的「共享潛在空間」,因此可以標記圖像。
模型在論文附錄A.1中列出的大量資料集上進行訓練。
2021 年6 月
#論文《擴散模型的發佈在影像合成方面擊敗了GAN》發表。

擴散模型引入了一種不同於GAN方法的影像合成方法。

研究者透過從人工添加的雜訊重建影像來學習。
它們與變分自動編碼器 (VAE) 相關。
2021 年 7 月
DALL-E mini發布。
它是DALL-E的複製品(體積更小,對架構和資料的調整很少)。
資料包括Conceptual 12M、Conceptual Captions以及 OpenAI 用於原始 DALL-E 模型的YFCM100M相同過濾子集。
因為沒有任何內容過濾器或API 限制,DALL-E mini為創意探索提供了巨大的潛力,並導致推特上「怪異的DALL-E」圖像爆炸式增長。
2021-2022
Katherine Crowson發布了一系列CoLab筆記,探索製作CLIP 引導生成模型的方法。
例如512x512CLIP-guided diffusion和VQGAN-CLIP(Open domain image generation and editing with natural language guidance,僅在2022年作為預印本發布但VQGAN一發布就出現了公共實驗)。
就像在早期的GAN時代一樣,藝術家和開發者以非常有限的手段對現有架構進行重大改進,然後由公司簡化,最後由wombo.ai等「新創公司」商業化。
2022 年4 月
#論文《具有CLIP 潛能的分層文字條件圖像生成》發表。

該論文介紹了DALL-E 2。

#它建立在僅幾週前發布的GLIDE論文(《 GLIDE :使用文字引導擴散模型實現逼真圖像生成和編輯》的基礎上。

同時,由於DALL-E 2 的訪問受限和有意限制,人們對DALL-E mini重新產生了興趣。
根據模型卡,數據包括“公開可用資源和我們許可的資源的組合”,以及根據論文的完整CLIP和DALL-E資料集。

#「金髮女郎的人像照片,用數位單眼相機拍攝,中性背景,高解析度」,使用DALL-E 2 生成。基於Transformer 的生成模型與後來的GAN 架構(如StyleGAN 2)的真實感相匹配,但允許創建廣泛的各種主題和圖案
2022 年5-6 月
#5月,論文《具有深度語言理解的真實感文本到圖像擴散模型”發表。

#6月,論文《用於內容豐富的文本到圖像生成的縮放自回歸模型》發表。

這兩篇論文中,介紹了Imagegen和Parti。

以及Google對DALL-E 2的回答。

# #「你知道我今天為什麼阻止你嗎?」由DALL-E 2生成,「prompt engineering」從此成為藝術圖像合成的主要方法
AI Photoshop(2022年至今)雖然DALL-E 2為圖像模型設定了新標準,但它迅速商業化,也意味著在使用上從一開始就受到限制。
#用戶仍繼續嘗試DALL-E mini等較小的模型。
緊接著,隨著石破天驚的Stable Diffusion的發布,所有這一切都發生了變化。
可以說,Stable Diffusion標誌著影像合成「Photoshop時代」的開始。

「有四串葡萄的靜物,試圖創造出像古代畫家Zeuxis Juan El Labrador Fernandez,1636 年,馬德里普拉多的葡萄一樣栩栩如生的葡萄」,Stable Diffusion產生的六種變化
2022 年8 月

Stability.ai發表Stable Diffusion模型。
在論文《具有潛在擴散模型的高解析度影像合成》中,Stability.ai隆重推出了Stable Diffusion。

這個模型可以實現與DALL-E 2同等的照片級真實感。

除了DALL-E 2,模型幾乎立即向公眾開放,並且可以在CoLab和Huggingface平台上運行。
2022 年8 月
#Google發表論文《DreamBooth:為主題驅動生成微調文字到影像擴散模型》。 
###DreamBooth提供了對擴散模型越來越細粒度的控制。 #####################然而,即使沒有此類額外的技術幹預,使用像Photoshop 這樣的生成模型也變得可行,從草圖開始,逐層新增生成的修改。 ##################2022 年10 月###########################最大的圖庫公司之一Shutterstock宣布與OpenAI 合作提供/許可生成圖像,可以預計,圖庫市場將受到Stable Diffusion等生成模型的嚴重影響。 ######
以上是Hinton上榜!盤點AI圖像合成10年史,那些值得被記住的論文和名字的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































