

正規表示式本身是獨立於程式語言的知識,但是它又依附於程式語言,基本上我們所使用的程式語言都提供了對它的實現,當然了,各家的實現也是有一些差異的,有的支持的功能多一點,有的支持的少一點。
因為正規表示式是實踐中使用廣泛的工具,所以脫離語言的學習我認為是不太可靠的。
正規表示式主要API關係圖
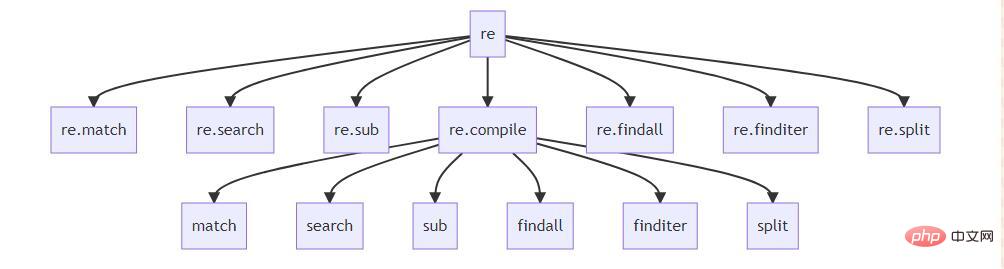
re.compile 下面有很多同名的函數。直接在 ·re· 模組下的是官方提供方便使用的函數,透過 re.compile 來使用是最正統的方式。 所以,接下來的內容,我基本上智慧使用 re.compile 及其下的方法來實作。
compile 函數用來編譯正規表示式,產生一個正規表示式(Pattern)對象,供match( ) 和search() 以及其它函數使用。
re.compile(pattern[, flags])
import re s = 'runoob 123 google 456' result1 = re.findall(r'\d+', s) pattern = re.compile(r'\d+') # 查找数字 result2 = pattern.findall(s) result3 = pattern.findall(s, 0, 20) print(result1) print(result2) print(result3) """ output: [‘123', ‘456'] [‘123', ‘456'] [‘123', ‘45'] """
這裡給出一個接下來會一直使用的範例模板,這個模板是這篇部落格最重要的東西了,之後的內容都會基於它來擴充。所以,請好好理解它。
import re
# 需要进行搜索或者匹配的文本
text = """I love you yesterday and today."""
# 正则表达式
regexp = r'love'
# 编译(对正则表达式进行编译获取 Pattern Object)
pattern = re.compile(regexp)
# 搜索
m = pattern.search(text)
if m:
print("匹配对象: ", m)
print("匹配的字符串: ", m.group())
print("匹配的开始位置: ", m.start())
print("匹配的结束位置: ", m.end())
print("匹配位置的元组: ", m.span())
else:
print("No match!")
# 替换
new_text = pattern.sub("hate", text)
print(new_text)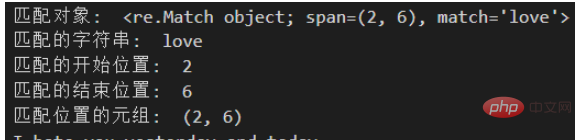
注意: 正規表示式regexp 在開始前會使用r 前綴,這樣做的目的是為了避免在正規表示式中大量使用轉義字符,破壞了整體的可讀性。
| 目的 | |
| 傳回正規符合的字串 | |
| 傳回符合的開始位置 | |
| 傳回符合的結束位置 | |
| 傳回包含符合(start, end) 位置的元組 |
以上是Python的正規表示式怎麼實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































